A Real-World Look at Scaling to the Amazon Cloud
Amazon Story
I have been working with Machine Perception Technologies [1], a small startup that has developed cutting-edge technology to detect facial expressions and emotions in videos. This technology can tell (with a reasonable degree of certainty) whether a person is being truthful, comes across as genuine, or is smiling. The software claims an impressive success rate, but processing requirements are fairly linear. On commodity hardware, each second of video takes an equivalent second of processing time. However, the binary is already multithreaded, so the more CPUs or cores you throw at the problem, the faster it processes each video.
Because this company essentially built a better mousetrap, the world soon beat a path to its door. This single binary approach works well if you process several videos, or maybe even a couple dozen videos, each day. However, the company soon started receiving requests that required them to process 5,000, or even 10,000, videos a day – with more to come. To make things worse, the system's capacity needed to absorb spikes in demand. Some back-of-the-envelope calculations quickly showed that each processing video machine could handle 480 three-minute videos in a 24-hour period. Thus, to process 10,000 videos in 24 hours, the company would need 21 machines. Investing in that kind of hardware, especially with a couple of extra machines to ensure quality of service, carries a forbidding price tag.
The company needed a scalable, flexible, and reliable solution that could be implemented cheaply and quickly. First, the system had to be scalable to process several dozen or tens of thousands of videos within a 24-hour period without incurring a remarkable difference in processing time per video. Second, the system had to be flexible enough to accommodate different kinds of processing or services. Video analysis was to be the first use case, but the company also wanted to use this solution for services, such as audio analysis, image processing, and encryption. Third, the development team was looking for reliability to support a 24/7 service. Any downtime would simply result in requests queuing up and overwhelming the service later on. Fourth, the solution had to fall within the limited budget of a small startup. Fifth, it had to be quick to implement because the company already had customers lining up.
After weighing several options, they decided to move the whole system, including the processing of the videos, to the cloud. This approach offered several benefits, not the least of which is that it required no investment in additional hardware. Cloud components mirror desktop software components, with the notable difference that economies of scale make it possible to have components with characteristics that one could not otherwise afford, such as scalability and redundancy.
The company chose Amazon as its cloud provider. Amazon Web Services (AWS) [2] are
A Closer Look
Overall, the system is currently using four of the many services offered by Amazon. Each of these services is exposed through a web service and can be interactively administered through AWS's excellent Management Console. The AWS offerings that we incorporated are:
- SQS [4] (Simple Queue Service) is used for input and output queues that make for loose coupling between components and a massively parallelized architecture. Our system includes two queues: one for incoming service requests and another for outputting processing results.
- EC2 [5] (Elastic Computing Cloud) lets us commission additional servers at a moment's notice, thus enabling us to scale up or down to meet fluctuations in demand. Amazon also provides a suite of command-line tools for EC2.
- S3 [6] (Simple Storage Service) offers permanent storage independent of EC2 virtual machines being deployed and shut down. Specifically, we use S3 to store the code that gets deployed on each EC2 instance.
- SimpleDB [7] is a highly available, scalable, and fast non-relational NoSQL database. We use SimpleDB for activity logging and maintaining status information on each EC2 instance.
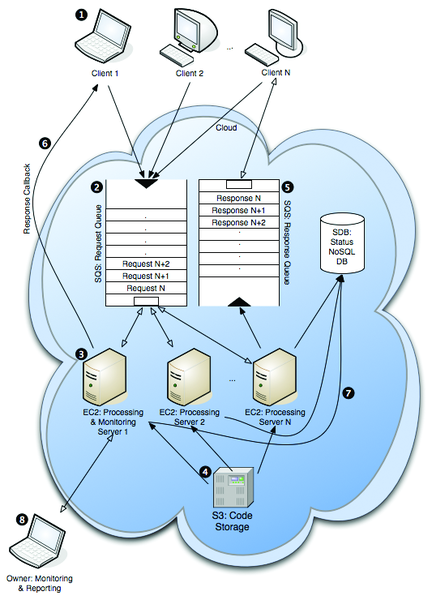 Figure 1: Architecture diagram and request-response lifecycle.
Figure 1: Architecture diagram and request-response lifecycle.
The architecture of the system is depicted in Figure 1. At Step 1, clients submit processing requests to the system. Three clients are shown in the diagram, but it could be any number. Users of the service must implement a way to submit requests that integrates with their existing workflow. However, we do provide reference implementations. For example, we have a command-line client that lets you submit a request and specify the input and output options on one line (Listing 1).
Listing 1
Request Command Line Client
submit-job.php \ --verbose\ --auth_user_file=dirk \ --auth_method_file=http-basic \ --auth_pass_file=krid \ --param=R:-100 \ --response=callback \ --callback_url=http://www.waferthin.com/admin/mpt4u-callback.php \ --auth_method_response=http-basic \ --auth_user_response=dirk \ --auth_pass_response=krid \ http://www.waferthin.com/admin/convert.mov
Requests are submitted in the form of short XML documents. Use the --verbose switch to invoke the complete request XML (Listing 2). Valid request formats are defined in a corresponding XSD (XML Schema Definition), against which all requests get validated as soon as they are received by one of the processing servers.
Listing 2
Request XML
<?xml version="1.0" encoding="UTF-8"?>
<serviceRequest>
<request service="analyze">
<input>
<file>
<URL>http://www.waferthin.com/admin/convert.mov</URL>
<credentials type="http-basic" username="dirk" password="mylilsecret"/>
</file>
</input>
<parameters>
<parameter name="R" value="-100"/>
</parameters>
<output>
<callback>
<URL>http://www.waferthin.com/admin/mpt4u-callback.php</URL>
<credentials type="http-basic" username="dirk" password="tellnoone"/>
</callback>
</output>
</request>
</serviceRequest>
In Listing 2, the service attribute of the request tag tells the system what kind of action to perform. In this case, analyze refers to the analysis of a short video clip and extraction of corresponding metadata. Each request consists of three main sections: input, parameters, and output.
The input section tells the system the location of the video file and how to retrieve it. In this example, the file convert.mov is retrieved from a URL at the waferthin.com server via HTTP. Accessing the file requires basic HTTP authentication and the necessary credentials are provided as well.
Parameters are specified in the aptly named parameters tag. These parameters are simply name-value pairs used to pass information to the binary performing the video analysis in the form of command-line options. Parameters give the client some control over the service. Listing 2 tells the processing server to pass to the binary a command-line argument of name "R" and value "-100". For security reasons, parameters must be filtered on the server side before being passed to the binary.
Finally, the output section of the request tells the processing server where to send the output. The service currently supports two methods for returning the results: a response queue and direct callback to any server. Listing 2 tells the system to post the results to the mpt4u-callback.php script on the waferthin.com server via HTTP. As in the input section, the credentials for basic HTTP authentication are provided as well.
In step 2 of Figure 1, clients submit requests to the request queue, which is a message queue provided by Amazon's SQS. The message itself can be anything (text, XML, HTML, an image), as long as it is no bigger than 8KB. Valid credentials are required, which prevents unauthorized users from flooding the queue or hijacking the service. Giving a new client access to the service simply involves giving them the queue URL and credentials. Whenever a message is submitted to the queue, clients receive a unique message ID that can later be used to tie responses to the original request.
Because of the distributed nature of SQS, it has the curious characteristic that, in rare circumstances, a message might be processed twice. In accordance with Amazon's recommendation, we designed this system so that processing a message twice would have no effect on the overall system.
On the back end are any number of servers responsible for fulfilling the requests (step 3 in Figure 1). Whenever a server is idle, it will ask the queue for the next message. If the queue is empty, the processing script on the server goes to sleep for some time and then checks again. Once a server receives a request, it will process the request and return the result. Once a server has received a request, it will ask the queue to make the item invisible to avoid another server processing the same request. Only after successfully returning the output of processing activity does the server ask the queue to delete the item. This ensures that the request will get serviced even if something should happen to the server during processing. For example, assume a processing server crashes while servicing a request. The server might become a zombie – no longer able to function properly. The request on which the server was working while it crashed, however, will become available again in the queue after a specified timeout period. This way, a healthy server can fulfill the request and eventually delete the corresponding request from the queue. Thanks to the request queue, the system has built-in disaster recovery – at least as far as the processing servers are concerned.
Having multiple servers processing requests from a single input queue is quite similar to a multithreaded or multiprocess system. The Apache web server, for instance, can be configured to pre-fork multiple instances, each of which will then service HTTP requests as they arrive. In the case of Apache, all processes typically run on the same machine. In this system, each processing server represents a separate process, but otherwise, the approach is not much different. (This is actually a design pattern also known as the thread pool pattern [8].)
Once a request arrives at a processing server, it gets parsed and turned into an object. The system does the processing and returns the output. The default response format is XML. Listing 3 contains a typical response XML document. Here, too, the XML document validates against the corresponding XSD.
Listing 3
Processing Results XML
<?xml version="1.0" encoding="UTF-8"?> <serviceResponse> <response service="analyze" status="success"> <request messageId="7d57b74c-78a4-459e-9445-4d5b9e0b3c27"/> <rawOutput><![CDATA[1 2 3 4 5 6 7 8 9 10 10 9 8 7 6 5 4 3 2 1]]></rawOutput> <message>Request successfully processed(in 6.01 seconds).</message> </response> </serviceResponse>
The original request can specify that results return to the client in either of two ways. First, results can be pushed out via an HTTP POST request (step 6 in Figure 1). You might recall that the callback URL was specified in the request. Second, a response can be added to the response queue, to be retrieved at the convenience of the client. In either case, the messageId attribute of the request tag allows the client to tie the result to the original request.
Virtual Linux, Amazon Style
Amazon's EC2 servers are completely virtual hardware running software that comes in the form of Amazon Machine Images (AMIs). At boot time, you can choose from several hardware configurations with different performance characteristics, as shown in Figure 2. At the time of writing, prices per machine per hour ranged from US$ 0.02 for "Micro" on Linux/Unix to US$ 2.48 for the "Quadruple Extra Large" on Windows. Amazon's prices for EC2 instances tend to go down over time. You also can lower the cost per unit by pre-purchasing "Reserved Instances" and bidding on unused capacity in the form of "Spot Instances."
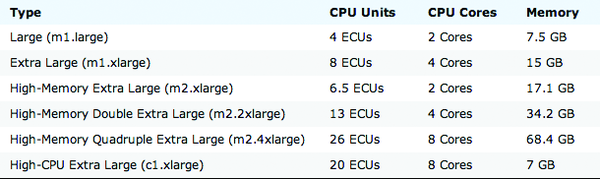 Figure 2: Amazon virtual hardware Options.
Figure 2: Amazon virtual hardware Options.
Our application is CPU bound. The faster the CPU and the more cores it has, the faster it can process each input file. Conversely, increasing memory results in no significant improvement in performance. For that reason, the "Large" or "Extra Large" hardware instances give the most bang for the buck.
To create the virtual image containing the software that will run on the hardware, you can select from images provided by Amazon or other developers, or you can create your own image. For this setup, our team started with an 64-bit Fedora 8 distro, which we then customized by disabling unnecessary services and upgrading PHP. Although we are well behind the Fedora release schedule with version 8, we chose this image because it was provided by Amazon and was optimized for working with AWS.
You can select an image and hardware configuration and launch them together. Once your virtual server has booted, you can connect to it over SSH as you would with any other Linux server. You can make any changes on the server you want, such as editing configuration files and installing additional RPMs; however, you have to save a modified image, unless you don't mind losing all your changes when you shut down the machine. Initially, the team installed all the application code and startup scripts on the image. This approach had the advantage that the whole system was ready to run as soon as the virtual machine finished booting. Unfortunately, we quickly discovered that this approach also made it cumbersome to test new versions of the code because we had to create a new image each time, which gets old pretty quickly.
Also, on a few occasions, something went wrong with our own startup scripts that prevented the boot sequence from completing, essentially rendering the machine inaccessible. In those cases, we had to revert to an earlier version of the image and re-do the most recent changes. To make the development process more flexible and the base image more stable, we came up with the following approach. The application code is stored in an S3 bucket – using Amazon's S3 cloud storage service (step 4 in Figure 1). S3 allows you to store and retrieve data in buckets of unlimited size, although any single file is not to exceed 5TB. Using Victor Lowther's excellent Bash implementation of an S3 interface [9], we created a Bash script that performs the following tasks: First, it renames the directory containing the existing code. (This only happens if we tell a running instance to update the deployed code.) Second, it downloads all code stored in a particular S3 bucket that is specifically reserved for this purpose. Third, it creates some symlinks and sets permissions to make sure the code will execute without a problem. Finally, the Bash script runs a startup script that was downloaded with the rest of the code. That startup script now asks init to run the two main processes, process-job.php and auto-scale.php.
With the Bash script doing everything necessary to download the code and start the processes, we still had to integrate it into the startup routine of the server. Because Fedora 8 follows the basic SysV startup process, with init being the process that launches all others, we simply added a single line to the /etc/rc.local script. This script is reserved for site-specific startup actions and gets executed near the end of the SysV boot sequence.
What did the company achieve with this configuration? For starters, we don't have to modify the virtual image anymore to test code changes. We simply use a nice S3 GUI to upload the code to the S3 bucket (think FTP). Any machine that boots up thereafter will download the new code. Also, we now have an easy way to upgrade the code on a running instance without having to reboot the machine. Executing the Bash script will cause the new code to be deployed. In essence, hosting the production code in an S3 bucket shortened the test cycle and made our production deployments more flexible.
Logging, NoSQL Style
All of the EC2 processing servers (or worker threads if you think of our architecture as a multithreaded system) log activity to a local text file. Also, these machines send the same logging statements to Amazon's SimpleDB. SimpleDB is fast and, as the name implies, simple. At this point, we are not sending enough data to really test how "scalable" the service truly is. And, because SimpleDB is still in the beta stage as of this writing, no support exists for it in the Zend Framework, which is the PHP framework of choice on this project. Instead, we use a couple of classes courtesy of Dan Myers's Amazon SimpleDB PHP [10] class project on SourceForge to read and write data to SimpleDB storage.
Rather than using tables with which you might be familiar from relational databases, SimpleDB lets you create "domains." In this case, we created two domains to which we log two distinct types of data that corresponds directly to the two processes that run on each server.
The first domain contains activity data generated by events, such as checking the queue for requests, processing a request, sending a response, encountering an error condition, and so on. This is the domain you turn to for usage statistics or to troubleshoot problems with a specific instance.
The data elements in the activity log domain are modeled after the Common Log Format that is often employed by web servers and other information servers. Because any of the processing servers can potentially go away at any time, it makes sense to persist their combined activity logs to a central location.
Buy ADMIN Magazine
Related content
-
Citrix NetScaler steps in for Microsoft TMG/ISA
 Since Microsoft announced the discontinuation of its Threat Management Gateway (TMG) – successor to the Internet Security and Acceleration (ISA) Server – companies have been looking for an adequate replacement. Citrix jumps into the breach with its various NetScaler products.
Since Microsoft announced the discontinuation of its Threat Management Gateway (TMG) – successor to the Internet Security and Acceleration (ISA) Server – companies have been looking for an adequate replacement. Citrix jumps into the breach with its various NetScaler products. - Amazon Announces AWS Fargate
-
Real World AWS for Everyone
 Sure you've heard about Amazon Web Services, but have you tried it? This article shows how to configure a web server and mirrored back-end database for a small-to-midsized business environment.
Sure you've heard about Amazon Web Services, but have you tried it? This article shows how to configure a web server and mirrored back-end database for a small-to-midsized business environment. -
Take your pick from a variety of AWS databases
 We look at the variety of databases available in Amazon Web Services – from relational, to NoSQL, to data warehouses for petabyte data volumes.
We look at the variety of databases available in Amazon Web Services – from relational, to NoSQL, to data warehouses for petabyte data volumes. -
Moving HPC to the cloud
 HPC has a unique set of requirements that might not fit into standard clouds. However, plenty of commercial options, including cloud-like services, provide the advantages of real HPC without the capital expense of buying hardware.
HPC has a unique set of requirements that might not fit into standard clouds. However, plenty of commercial options, including cloud-like services, provide the advantages of real HPC without the capital expense of buying hardware.