I am convinced that over the next few years we will see the end of server admins and, to an extent, developers. If you take into account investment in new projects, time to turn around current projects, and peoples’ unwillingness to throw away what they have invested time and money in, it looks like the shift will be in around five years.
In a little departure from my normal posts, I want to talk about PaaS and how we’ll all be out of a job.
A little while ago, I was at work and got an email linking to Standing Cloud, who have taken what several cloud providers offer and wrapped it up in a platform – well, actually, lots of platforms.
You can run on AWS, Rackspace, GoGrid, and several other cloud hosting providers, but the nice thing about their platform is you fire up preconfigured instances set up with any one of a wide range of open source apps on around 10 cloud providers – and you need no technical knowledge to do so.
The march of infrastructure and provisioning toward the user is exactly where Standing Cloud is taking us. Instead of the tedious provision of instances via the IT department or through the person who owns the AWS account, the end user with almost no technical knowledge can fire up an instance and get to work within minutes.
Choose the last five project that annoyed you because they were distractions from what you really wanted to do. Someone wants a WordPress site. Someone else needs a test build of Magento. SugarCRM is being looked at by the Marketing Department and the Marketing Director wants to review it.
Instead of this setup time going to the devops team (which is what we all are now, even if just a little bit), marketing directors can spin up instances themselves. Now, your marketing director might not feel comfortable doing this right now, but soon it’ll feel like signing up for any other site.
And that’s what Standing Cloud feels like to me.
To get started, sign in with your Google, Yahoo, or Facebook ID, and you’re presented with a list of just over 102 apps.
Launching an app is a matter of selecting it, deciding which cloud to deploy to, then starting it. This is convention over configuration to a high degree; you stick with their convention and while configuration is available, you might as well be launching your own instances on EC2.
For example, we have been testing things on a vanilla installation of the Concrete 5 CMS for a prospective client, and instead of installing it manually, we simply start up an instance via Standing Cloud and we’re done. Same goes for Drupal. Instead of going to all the effort of installing something that you might not use or need, you fire up an instance and try it out.
One of my favorites, OpenVBX gives you a cloud-based phone system. Neat.
To get going with OpenVBX, just log in, select start with a test drive before selecting OpenVBX from the apps. Pick a version (a reassuring bit of detail here, so you can see which version works for you).
Next up are the data centers/locations. Because you launch the instance, you confirm all the details and spin it up. This is the kind of thing you could automate, build in Rails in a short time, or just offload onto any other human in your company, saving you time to spend more time on Stack Overflow.
Once it’s running, you wait for it to launch. It’ll appear a few moments later in My Applications with all the usual login data – web login info plus the SSH details.
Having just created your first OpenVBX server, you can start patching calls, linking them up with your API, and generally being productive without the pain of anything at the server level. If you haven’t tried OpenVBX, it works with Twilio and hooks into their service to provide routed calls, voicemail, and interaction with external APIs.
Something for the First-Timer
Installing OpenVBX from source on a server takes maybe 30 minutes if you’re a tech and have a server running or a machine image ready. But that’s not the point and that’s not the case PaaS solves.
With Standing Cloud, all this effort can be delegated to a non-tech in the marketing department, IT procurements, or whoever. They don’t have to wait for you to get around to it. But, for the ever impatient nerd, you can ssh into the instance and get under the hood.
What else does it give you? (Or help you avoid dealing with?)
Aside from deployments from Git and managing backups and recovery (and who doesn’t want to give that up?), you can scale. Scaling is done either in a fairly basic way by resizing the machine or across multiple web heads using load balancers.
To see how they did scaling on AWS and Rackspace doesn’t take long. Standing Cloud enables you to resize instances, and it looks like all they’re doing is calling out to AWS and Rackspace to resize the instances. To resize an instance on AWS, for example, you just stop it, resize it to a bigger or smaller instance type, and start it up again. Standing Cloud provides a wrapper around this with an app to boot.
All this works perfectly for trying out apps and small- and medium-scale hosting, and it would suit a lot of internal apps that IT departments need to provision.
Some apps can be spun up on multitier architecture launched last October and is still in alpha. Their multitier platform can run on nine different cloud providers and run more than 10 applications. To get this running, you configure the web and database tiers, setting the number and size of the nodes you need. All this is pretty easy to configure, with the caveat that it’s easy to spend too much or underspec your machines.
Now for my “and finally” bit …
And Finally
Why does this matter for those of us who love the nuts and bolts and would prefer to configure the servers ourselves? Two big reasons. First, it’s nice to see another architecture described using the practices we know about. Standing Cloud’s site describes their launch sequence as:
- We start with a clean server image from the cloud provider of your choice. Once the server is active, we run a series of scripts that get the server ready to host one of our 90+ supported applications and platforms. The steps are different depending on which stack the application requires.
This translates to: Keep the image clean and use config management and automated builds to get the software running. Do not fill up your images with anything that’s going to change or isn’t completely generic. The OS and basic requirements are pretty much all your need.
A nice line from the same page gives insight into how your configuration needs to change as your cloud instances change:
- We then mathematically apply some configuration tweaks to Apache, PHP, and in some cases MySQL based on the size of the server that was allocated.
Read this as: Your config matters, so don’t just throw the same config up everywhere. Memory limits, query cache sizes, and the like need to be configured based on the instance size, memory, and CPU.
This has been a much less technical post. But it’s an important one. Cloud doesn’t mean we nerds get more stuff to play with, it means we get less to do because the provisioning, configuration, and management of apps is moving closer and closer to the person who makes the decision.
Like Heruko, this is PaaS, but this platform is closer to something like SalesForce or Basecamp because it can take no technical knowledge to get the thing going, even if technical knowledge might help expend it.
I can see a day when starting a new CMS or CRM project requires the business owner just to punch in their credit card details to a service’s registration form. From then on, most stuff will be handled for them.
Until then, it’s a race to see who can build it first. And that’s going to be fun.
Imagine what projects you’ve done this year that could be delivered if the CMS, CRM, Blog, or database could be turned on and just delivered to your user. And what does this mean for infrastructure teams and developers?
In the short term, cheat. Use Standing Cloud and similar PaaS systems as shortcuts. In the long term, maybe you can build the PaaS that does your whole job through point and click.
Get a better picture – load test the cloud. Load testing is never finished. I’ve spent a good couple of days testing something only to find it slow down when in production, so when do you decide: “That’s it. Ship it”? Is there something lurking in there that’s going to hurt you on the first day in production?
Too often, I’ve seen people get hung up on one or two load times as an indicator of their entire app, so here I’m going to look first at those numbers and then I’ll look at using a curve to describe your app’s performance. Things always look better when they have a graph, don’t they?
In this post, I’m going to stop short of testing POST requests and interaction through lots of screens – that will be for another day. This time, I’ll look at thinking beyond the load time on a couple of screens to viewing the range of page performance your users get.
Siege
Here’s the scene: You have an app ready to ship and you want to know how it’ll behave when it gets the 2 million hits the marketing guy is sure it deserves. To do this, you work out what the peak number of concurrent users will be and blast it with that number.
A tool like siege creates a set number of requests in one of a few modes. By default, it behaves like a normal user, delaying between hits, but it can also be set to benchmark the site by not delaying between hits.
For example (sorry, owners of example.com!),
siege -c 30 http://www.example.com
creates 30 concurrent users to hit the site. The stats you get back are useful:
Lifting the server siege... done. Transactions: 422 hits Availability: 100.00 % Elapsed time: 11.79 secs Data transferred: 2.47 MB Response time: 0.22 secs Transaction rate: 35.79 trans/sec Throughput: 0.21 MB/sec Concurrency: 7.85 Successful transactions: 437 Failed transactions: 0 Longest transaction: 2.59 Shortest transaction: 0.07
Now don’t fall into the trap of measuring everything with one number. Don’t look at the Availability line and think a number near 100 percent means everything is fine. It isn’t. You need to look at the outliers, the longest transaction, failed transactions, and unavailability to find out how bad it’ll be for some users.
If your shortest transaction is 0.01seconds but your longest is 30 seconds, you will be hit. Hard. I don’t mean your server will be hit, I mean you’ll be hit by that marketing guy when his campaign worked but your servers didn’t. (As he sees it.)
For example, if your app’s page relies on five hits on the web stack (assuming you pushed all static assets to S3 or something static), the probability that each user is affected by a 1 percent failure rate (i.e., 100 percent minus availability) increases because scaling that 1 percent of failed hits doesn’t mean just 1 percent of users.
(On a side note: you should urge your developers to degrade their app gracefully so that if the Ajax calls fail, the user still has a good experience or at least a decent error message. Even so, focus on keeping those servers up.)
So, how do you find out what it’s like for more users?
Some other basic options you should use are -t, which sets the time your site is put under siege. Don’t skimp on this because apps behave different after a prolonged battering, as caches build up and the cache system misses more than it hits. Run it for a good 20 or 30 minutes and see what starts to melt first.
siege -t 600 -b http://www.example.com
For debugging --get should be used. This works like --save-headers in wget, so you can make sure you’re getting back what you expect.
Don’t assume short response means everything is completely fine. It has to be the right kind of response. A brilliant “gotcha” I’ve seen is someone benchmarking a server that is spitting out 404s like there’s no tomorrow because the app crashed after 20 concurrent hits.
With the -f option, you can pass a file of URLs to be tested, which can be used for getting down to the really problematic parts of your app. Give it those pages you hate the most:
# simple homepage http://www.mynewapptotest.com/ # A page that's never cached: http://www.mynewapptotest.com/no-cache-here.php # A page that processes POST data http://www.mynewapptotest.com/login.php POST user=dan&pass=hello-there # Some search pages http://www.mynewapptotest.com/search?q=find+me
To run this, pass the file to siege:
siege -f urls.txt
So, that’s a few users, some URLs and some post data. Now I’ll take it up a notch.
The -b option benchmarks the server. There’s no delay between hits on the server so the only limit is your computer’s memory and connection to the web. Unfortunately, they can be limiting, so how can you create a really good benchmark?
Microarmy
You need a microarmy. Before this was written and in the days before AWS, you would grab all the servers you could from various data centers and batter each server. Then, when AWS came about, you’d spin up a dozen servers and use Capistrano to attack your little cluster.
But stand on the shoulders, as they say: You can deploy 100 vicious little siege slaves in “106 seconds.”
On with looking at the numbers …
If you are planning to plot the results, you almost certainly don’t want to write down the results each time. The siege log by default is held in /usr/local/var/siege.log and contains all the data recorded on each of the tests run. Of course, you can copy this into a Google doc or a spreadsheet to give yourself a nice-looking graph.
Date & Time, Trans, Elap Time, Data Trans, Resp Time, Trans Rate, Throughput, Concurrent, OKAY, Failed 2012-01-09 20:49:17, 8108, 414.12, 4, 0.78, 19.58, 0.01, 15.18, 8175, 72 2012-01-09 20:49:30, 68, 2.38, 0, 0.45, 28.57, 0.00, 12.76, 85, 0 2012-01-09 21:09:21, 84, 4.84, 0, 0.29, 17.36, 0.00, 5.09, 90, 0 2012-01-09 21:09:47, 80, 4.51, 0, 0.36, 17.74, 0.00, 6.38, 90, 0 2012-01-09 21:10:00, 92, 4.42, 0, 0.35, 20.81, 0.00, 7.22, 100, 0 2012-01-09 21:12:15, 78, 4.38, 0, 0.33, 17.81, 0.00, 5.92, 85, 0
Now for another tool.
ab
I used siege for a long time but then found I wasn’t getting a real picture of the end-user’s experience. I was looking at availability with fewer than 200 concurrent benchmark users and thinking, “looks good for most hits.” I needed a more detailed picture of what was happening for the users. I was doing exactly what I started talking about: using one number to describe the experience of a wide range of users.
Apache Benchmark – ab – is a similar tool, and the syntax follows what you’ve seen so far for siege:
ab -n500 -c10 http://www.example.com/
A heap of options are offered with ab, such as outputting results to a CSV file and adding arbitrary headers. Once you issue this command, you get output similar to siege, but it gives you a very useful result on how many were served and in what percentile.
Percentage of the requests served within a certain time (ms) 50% 1988 66% 2212 75% 2931 80% 3267 90% 3721 95% 4278 98% 5990 99% 6521 100% 6521 (longest request)
Web users are looking for consistency, so you should expect most of the responses to be around the same time. If you have too much variation over too large a time difference, your site will look erratic. Everything on websites is about consistency. If you can be consistent at one second, then do so if the alternative is 20 percent of users getting under a second and the rest getting 10 seconds.
Now I’m getting to something really useful, which will tell you more about your users’ experience than two or three response times. The next option to look at is -e my-output.csv, which will output a more detailed version of this report to a file that you can plot:
ab -e my-output.csv -n 100 -c 10 http://example.com/
Unlike taking an average, which can be heavily skewed toward lots of good results and hide a couple of really bad ones, this gives you the data for each percentile. So, although the first 1 percent of response times might be a snappy 500ms, if the top 1 percent is more than 10 seconds, you can see something to worry about. This is especially true for complex apps that use several Ajax requests or web sockets, in which case one in 50 connections being slow could end up affecting more users. The lower the point at which the response times increase rapidly, the more worrying because this means more of your users are seeing a slow site.
Sticking with the command line because it’s comfy there, push this data into gnuplot. If you strip off the first line of the file, you can plot it in gnuplot with:
set datafile separator "," plot 'my-output.csv' with lines
This can tell you much more about the behavior of your app than the response rate maximum load time.
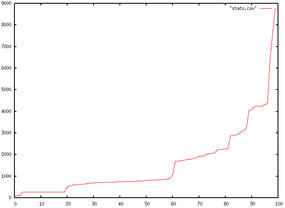
Figure 1: CSV file from ab -e in gnuplot.
Figure 1 is an example with response times on the y-axis and percentiles of users on the x-axis. You can see the response times climbing slowly and then rocketing as the server isn’t able to deliver the responses. Finally, when you reach a certain point, you hit the limit at which the server is simply not available.
With this chart, you can run some really interesting tests and get some telling data out out of the system.
To turn this into a script, you pull in a little sed magic:
ab -e output.csv -n 10 -c 5 http://www.i-am-going-to-test-this.com/ sed 1d output.csv > stats.csv echo ‘set datafile separator “,”; plot “stats.csv”’ | gnuplot -persist
Increasing the number of current users (the -n flag) step by step gives you a series of graphs of the performance behavior of your app. So now, instead of one number saying 95 percent of hits will be OK, you can see the behavior changing as the number of users increases. Instead of picking a random concurrency number to benchmark, you can find the problem points and tackle them.
Back in the Cloud
Now I’ll bring all this back to the cloud. When you’re designing and testing your cloud architecture, you need to consider failure and the effect of failure. Load testing isn’t just seeing how much traffic you can cope with but seeing how much traffic a degraded cluster can cope with.
What happens if you kill half the web heads but the load stays the same? By plotting the response times rather than taking a single number and by gradually changing the number of concurrent users, you get a much better picture of what your users will be writing on Facebook when your site slows down.
And, you get to redesign your cloud architecture as if you’d already suffered the failure.