If you still haven’t found the time to learn how to install, configure, and maintain a database, you might be interested in a cloud solution that promises “zero management.”
Xeround sells itself as the “zero-management database.” Managing databases consumes thousands of hours every year, becoming yet another time sink to sys admins and developers alike. Management includes everything from installation through upgrades, checking on server health and disk space, and scaling and managing these things at scale – something that every one of us could learn, given a few books and the time if we could find it.
Fully Managed
Fully managed databases (DBs) aren’t new, and Xeround isn’t the first, but it has focused on the things that cause plenty of pain. Keeping a DB running and scaling it. After housing, powering, and securing the physical machines, configuring them is the next task that can distract from actually building an app. Although you might have edge case requirements that need specially honed and tweaked database servers, chances are … you don’t really.
In most cases, you can do a lot with a good standard config file and focus your efforts on the architecture of the app using these standard configs. Once you’ve given up your grip on the config files and the SSH into the box, you can focus on the app again. It’s okay to make apps and not be a slave to sys admin duties all the time.
Xeround
Xeround was introduced to me while talking to a prospective client. They reeled off a list of cloud services, and I nodded. Then, they mentioned using Xeround, and I quickly googled, scanned the Xeround homepage, and I thought, “Cool. Less to worry about.”
Xeround bills itself as “A ridiculously simple, seriously powerful cloud database.” In this blog, I want to look at how it does that. Xeround runs on AWS and Rackspace. You choose the size, launch the instance, and you get an instance to connect to.
After you have signed up and logged in, you are in the DB Instance Manager panel, where you can hit Create New to create a new database. The free account doesn’t come with scalable databases, but you will quickly get the idea: Xeround gives you a few end points to connect to, which are sent in an email after the launch of the database:
DNS Name = ec2-11-22-33-44.eu-west-1.compute.amazonaws.com, Port = 3158 DNS Name = ec2-22-33-44-55.eu-west-1.compute.amazonaws.com, Port = 3158 DNS Name = ec2-33-44-55-66.eu-west-1.compute.amazonaws.com, Port = 3158
Connect to these just like you would any other MySQL server,
mysql -u test -ptest -h ec2-11-22-33-44.eu-west-1.compute.amazonaws.com -P 3158
and pipe in your data with:
mysql -u test -ptest -h ec2-11-22-33-44.eu-west-1.compute.amazonaws.com -P 3158 < my-database.sql
If you need to move data from an existing DB to a Xeround DB, a simple trick is:
mysqldump my-database | mysql -u test -ptest -h ec2-11-22-33-44.eu-west-1.compute.amazonaws.com -P 3158
This makes switching to Xeround as a database for a live app, as a database in development, or just as an interim test simply a matter of changing the username, password, host, and port in your application.
Start Free
The free account runs on a shared environment and is limited to five connections. This isn’t going to be enough for most live environments but would certainly be enough for basic testing to see whether latency or connection issues arise. Larger packages start at US$ 17/month or US$ 75/month. When comparing this with something like EC2, in which one of the smallest services you could actually use in production starts at around US$ 70/month, it’s easy to see how the Xeround managed database makes sense. Before you have the cash or time to manage your own MySQL servers, this service can get you a long way.
Autoscaling is available in all supported providers. You can set monitoring and scaling thresholds based on CPU, memory, and number of transactions. These allow scaling on the basis of what’s going on in the DB at any time.
Start it GUI-Free
Provisioning is important. For me, the API is critical to anything having the title “cloud.” Provisioning databases dynamically can be really useful if you have an app that wants one database per instance (i.e., isn’t multitenant) or in development environments in which you’re creating, editing, and destroying databases frequently.
The API provides you with the ability to create DB instances and drop them. For any running instance, you can get its info and change the instance’s passwords.
These are fairly basic API calls, and I would liked to have seen others for changing the scaling rules and getting the health of an instance. It’s nice to manipulate the scaling behavior programatically rather than have to log in to the UI all the time.
Heruko, a service that I’ve talked about before, is supported via an addon. To spin up Xeround alongside Heruko, just enter
heroku addons:add xeround:free
and configure the DB URL with
heroku config:add ec2-11-22-33-44.eu-west-1.compute.amazonaws.com
which you’ll get by email after launching the instance.
You can find more information about Heruko integration with Xeround on their website.
In either guise, being able to spin up and delegate the running of the DB servers to someone else will save a heap of time.
Rackspace MySQL Server
Other cloud database options are available. Rackspace recently announced a database service based on the OpenStack framework. At first glance, this looks very similar to the Xeround system, providing the APIs to list and manage a database instance, manage users, and enable root access.
This private beta is by inviation only at present, and they say they’re working on “storage scaling, configuration management, backups/restores, and much more” – I’ll be nagging them for details, and I’ll post the details as soon as I hear.
RDS from Amazon
A service that’s been around for sometime is Amazon’s RDS (relational database service). As in launching EC2 instances, you spin up an RDS instance either via the AWS console or via the API. To spin up an RDS instance in the console, just log in, navigate to the RDS tab and click Launch Instance. After following instructions, you end up with a running MySQL server.
The RDS service is mature, supporting more options than most simple “managed MySQL” services. You can enable multi-AZ (multi-availability zone) by simply clicking the option, or you can use the Read Replica feature once your RDS instance is running.
The multi-AZ mode means you’re running two instances in two separate availability zones. If one zone dies, you can pick up from the second zone’s database. Beyond this, Read Replicas allow you to make a second, replica database that can be really useful for nightly reporting, back-office ordering systems, or just scaling up the hosting. To enable this in the AWS console, just log in and click Create Read Replica in the listing of RDS instances.
The options for replicas are, of course fewer than for the master. You can set the size, name, and AZ. With this, you could spread your read instances over all AZs within a geographical region, or you could create a reporting instance each week using the biggest instance to crunch through the week’s data.
Xeround vs. RDS
Xeround raises the point that RDS isn’t really elastic. In fairness, they don’t called it elastic, but if that’s what you’re looking for, RDS isn’t going to give it to you out of the box. Elastic means self-scaling: It’ll just provide you with the computing power you need. Scaling RDS works in increments, just as on EC2. You can have a micro, or a large, or an extra large. At each step you decide how many instances you need, rather than how much computing power.
Therefore, RDS is more like scaling old physical boxes than a pure service that hides the issues of scaling completely. In contrast, Xeround has focused on scaling transparently, keeping the matter of how it’s done in their corner rather than yours.
WhySQL Anyway?
Now that you’ve heard about the options for good old relational databases, what about the growing number of NoSQL options? If you’re trying to address the problem of scaling a database to huge levels, chances are it’s going to be scaling in two ways over the next few months and years: number of records and structure of data.
Relational databases like MySQL are great for structuring data, but NoSQL reverses the role of the database from dictating the structure to following it. Many NoSQL libraries hide the structure completely, so adding a new field can simply be done when you start using the database abstraction objects:
p = Person.find(123) p.is_special = true p.save
Libraries like MongoMapper in Ruby or Shanty in PHP connect to MongoDB, completely removing the need for maintaining the database’s structure in the traditional sense.
There’s a growing body of information on running NoSQL databases in the cloud including a recent whitepaper from Amazon, as well as plenty of other NoSQL systems. But what if you still don’t want to deal with the scaling problems yourself?
MongoHQ provides fully hosted MongoDB. As for every self-respecting service these days, there's a free tier called their sandbox tier that lets you launch a Mongo database. The interface allows you to create collections and manage database users and backups.
Two options come from Amazon. SimpleDB provides a similar key-value storage, and this has been around for some time. SimpleDB scales to internet-scale number of records, so for truly massive numbers of simple key-value data, this is a good option.
The newer DynamoDB requires a little more setup than the other services I’ve been looking at because “Amazon DynamoDB ... reserves sufficient hardware resources and appropriately partitions your data over multiple servers to meet your throughput requirements.” This means you have to define your throughput requirements – that’s the work.
After creating the DynamoDB table, which you can do using the SDK URL or via the AWS console, creating the table is a matter of naming it and setting the primary key and the read/write capacity units. The last option – the capacity units – allows AWS to guarantee your response times, so an additional option is required: the email that is alerted when there are more reads or writes than expected.
With these options created, you’ll need to hook up the SDK in your preferred language or use the AWS Explorer for Eclipse. This is one difference to the Xeround and MongoDB options: You have to speak via an SDK, so if you’re bound to your MySQL or Mongo terminal, this might upset you. If you’re dealing with Internet-scale data, you probably have other things to worry about, though.
More To Play With
Databases aren’t the domain of DB admins any more. They are services that you can buy and start using in minutes. Before you fire up another server or instance to run MySQL or your favorite database, consider the cloud database options. Give them a spin – it can take just minutes.
I started writing this post just playing with Xeround, but I have a feeling this one is going to evolve into its own little series, because who wouldn’t want to give up managing databases?
In my first story on database as a service (DBaaS), I spoke to Xeround and Standing Cloud about how they implement and deliver their software as a service (SaaS). Although they come from different parts of the SaaS market, they had one thing in common: They’re finding different ways of doing what’s been done before in the hope it works better at the (cloud) Internet scale.
This is all part of an ongoing project I have, to understand why it’s worth bothering with SaaS at each level. Sure, there’s hype, but is it actually worth it?
This time, it’s EnterpriseDB who are a slightly different case, as we’ll see. They’ve taken an existing product that they already support in the enterprise market and they’ve deployed it to the cloud.
Their proposition: point-and-click simplicity but running both on the premises and in the cloud. They differ because they’re pitching to two separate markets. The traditional, highly expert DB admin and the new cloud market, where ease of deployment and “it just works” matter.
Back in the Kitchen
As usual, I’m back in my kitchen with Skype fired up, and I’m talking to Karen Padir from EnterpriseDB.
EnterpriseDB was founded on the principle that Oracle database prices are too high. To combat this, EnterpriseDB built upon PostgreSQL, an open source program with a reputation as a strong relational database preferred by many database admins. The thought was that they could go into the Fortune 500 market offering PostgreSQL with a few extras and added support to lure the blue chip firms away from their Oracle habit.
Although this worked, they then tweaked the recipe. A little more than three years ago they had a change of CEO and decided that luring Oracle users might not be the only way. Maybe they could offer something more to the Postgres users of the world.
And this is where the new product line came in. They have a series of products from their solutions pack, Enterprise manager, to the new cloud product. The cloud product differs because it isn’t simply a hosted version of their other products that run on-premises.
The cloud product supplies the “just works” aspect that on-premises products traditionally don’t. (Note I said “traditionally” … things are changing.)
“Developers are becoming sysadmins. Developers are becoming database administrators. They’re just assuming certain things are being taken care of for them and they don’t have to spend their time looking at and learning these tools to make it work right,” said Karen.
Those assumptions are a big part of running Anything-as-a-Service. It has to just work for two reasons:
- In the cloud, it’s more difficult to tweak and configure services. There’s a limit to how far down the stack you can get, so tweaking some config file or running filesystem optimizations just aren’t options. It’s much better that the service works in a best-practice way out of the box. This is almost saying it should have the lowest common denominator config, but it’s more accurate to say that it has to work for the majority of cases.
- It’s what people expect. If it’s on the cloud and a service, then it should have solved the problems for you. That’s why it’s a service and not consultancy.
The latter of these two is a more powerful market force. Cloud services are expected to work straightaway, which hugely reduces the procurement process and time spent on contracts. Often, it’s just filling in a form. All this puts pressure on the service to work. Just work. Straightaway.
The barriers haven’t disappeared, but if you’re frustrated with something that you spent four years of your budget on and is using up 4Us of space, you’ll think twice about it compared with something you can shut down this afternoon or migrate next week. The biggest barrier to change for the user is rewriting their software, and that is less that four years of a budget.
But EnterpriseDB doesn’t see people using the cloud exclusively. The cloud product might be the choice for some people some of the time, but the on-premises solution will still be needed for a different set of people.
What’s This Cloud Thing For Anyway?
“People will still download products," said Karen. "They’ll download and play with them, but more and more people are doing their experimenting and their playing with things in a cloud environment. And, so what you expect to work in the cloud can be very different from when you download a piece of software onto your server and start running with it and playing with it from there.”
Karen went on to explain that they have three audiences:
- The traditional band of install-configure-protect: They like to see their software running on their own metal.
- The cloud-native: They’ll try it in the cloud and punch in their credit card details a couple of hours before the app goes into production. Think student, hacker, start-up, and, increasingly, corporate people outside the IT department who just want to get the thing done.
- The experimenter: SaaS is still where people expect to try things out. Any product that can be used via an API or a web browser should have a trial I can use just by entering my email address. Ask any more than that, and you’re pretending it’s more complex than it is.
This ease of use is translating back to the on-premises world: “[after] the launch of our Postgres+ database – we launched it at the end of January – within the first days of our launch, we have customers looking and asking, ‘I want the downloadable version of that’,” said Karen.
The SaaS world is forcing the on-premises software world to rethink what “user friendly” means. It’s more than just stamping it on the packaging
Karen continued: “People say, ‘… I’m not on the cloud but I love [this] and I want all these nice point-and-click setup buttons. All this add failover and adding disks. I want to be able to do all these things to my database without having to worry about it, but I’m not on a cloud.’”
The cloud “just works” functionality is expected now, even if the software is running on-premises.
The Continuum of On-Premises to Cloud
To understand how people choose where to deploy, Karen described a continuum. Starting (in no particular direction) from dedicated hardware, through virtualization of your on-premises hardware, and then into the cloud in its various guises. The common thought is that you move from one end – the heavy hardware – to the other – the light cloud services. But, said Karen, “… I don’t think people will move along the continuum that way. They won’t necessarily start on traditional hardware and end up in the cloud.”
People will be in more than one stage of the continuum, so as SaaS fits into their work, it’ll fit differently, depending on what problem needs to be solved. The on-premises database may well stay there for years, but the short-run reporting projects require database server power that is best bought by the hour.
Choice Can Be Good
EnterpriseDB’s Postgres Plus Cloud has a surprising number of options for a DBaaS. Comparing this with Xeround, RDS, Rackspace Cloud, and other products, you can tune it through the interface to a greater degree.
Because the instances are launched on Amazon Web Service (AWS), you can ssh in and configure them there. Backup configuration comes standard.
“Cluster healing mode” is a simple checkbox option, meaning you have nothing to configure to determine whether you’ll heal the master with a new master or existing replica. Autoscaling thresholds are built in to the interface.
A list of dozens of config options hide beneath the Configurations tab at the bottom of the page, including autovacuum times, checkpoint values, and other standard configuration choices. Other cloud databases do allow some control at this level, but not often through the user interface.
What made EnterpriseDB decide to include the config options rather than going with the trend of “just works, don’t fiddle”? The history of the product gives the background needed:
“We employ a number of commiters of the Postgres community,” said Karen. “These are highly sophisticated database architects who are writing the database internals. So, there are certain things that they expect to tune and play with as they’re using the database.”
This sounds like more control than most platform-as-as-service (PaaS) products offer, but this is exactly why EnterpriseDB consciously made the choice to say, “You know what? That’s OK because the way our product exists today you don’t have to worry about it.”
Karen continued: “We have hundreds of users in our hosted service, and when we interview them … the common theme we get is that it seems too easy. [They say,] ‘I worry that I did something wrong because it just keeps running and I don’t have any issues. I didn’t have to do anything.’ So there’s that, that it’ll just work, but then also we do allow you the ability to ssh into the machine (your AWS instance); you can add additional components, do more things than just set it up and work away.”
As someone who often prefers to start with a setup that just works, this sounds great. But the option of tweaking if it turns out the defaults don’t work is a double-edged sword: I can tweak, but I can mess it up as well.
For the database admins this is built for, control sounds ideal. The contrast that strikes me is with other DBaaS products, which pretty much give you any database so long as it’s black, to paraphrase Henry Ford.
MapReduce, NoSQL and Why Stick with SQL Anyway?
Suppose you have a heap of data and you want to plough through it with MapReduce at Hadoop speed. EnterpriseDB offers a MapReduce adaptor.
However, if you were going to implement NoSQL or processing of data on the scale that MapReduce and Hadoop offer and you need a rewrite, why wouldn’t you just migrate to Riak or any of the other NoSQL engines?
In answer, Karen said, “Most people aren’t going to migrate their application to a database that has a completely different data store on the back end because that’s a whole application rewrite.”
Despite the number of new apps and startups appearing, there’s a still a heap of legacy code out there. As I found talking to Xeround, the slowest moving part in many organizations is the codebase.
“So,” said Karen, “I think it has to do with: What is your application trying to do? What are the skills that you have? … Because at the end of the day, most developers know how to write SQL, and if you’re taking an application that already exists, it’s just the flexibility you have to change the application.”
People are doing this in steps, but they want to start by having both worlds.
“I want to be able to take my data that’s stored in Hadoop and put it in my relational database and be able to use some of my tools that I already have to run queries – more structured queries on that data – and vice versa,” said Karen. “I have data that’s in my relational database and I want to put it in my Hadoop cluster.”
So, again, database is a requirement rather than a technology. Instead of installing Oracle or MySQL, architects are choosing several database technologies to solve each of the problems they have. However, because other database technologies offer a few more features, you get a feature-race to satisfy developers that the database platform they’re running on offers everything they need.
Future of PaaS
EnterpriseDB has made the move from a few products to a cloud service, which coexist. These products solve different problems and, unlike the other people I’ve spoken to (so far – more to come), DBaaS is just one way that the database problem can be solved.
Even though EnterpriseDB is clearly positioning themselves at the database admin end of the market, with the configuration options and the ability to tweak, users do still expect it to work out of the box.
DBaaS has one strong argument in its favor: Chances are they have better database admins and better defaults than you because that’s what the DBaaS provider does. For companies replacing their self-maintained database hardware or services, DBaaS removes a chunk of the admin. If you get to the tipping point at which the defaults just aren’t good enough, bring it back in-house, but don’t give yourself unnecessary pain by doing that from the beginning.
“Amazon and HP have lots of people who are completely dedicated to the security of their systems and keeping them up and running [compared with] a small company with a small data center that just happens to think they’re secure because nobody knows about them,” added Karen.
Most CTOs and developers have a lot of experience with database management, but many of them don’t have a great deal of expertise when compared with the concentrated expertise used in the management of EnterpriseDB, Amazon’s RDS, Rackspace’s up-coming cloud database, and other DBaaS options. Even on security, Karen noted, “We have two additional products …. Both of these combined help protect you against SQL injection attacks and other bad things that can happen to your data.”
Outsourcing the detail and management of your database sounds like a good idea. I for one am always in favor of paying someone else if they can do it better. so I concentrate on my product.
But outsourcing can go wrong. Data is the most important part of your company, and if you are outsourcing the control of it, you need to know what control is left to you, and you need to test the expertise of the platform or the support.
Anecdotally, the company I work for just migrated a lot of hosting to Rackspace-managed cloud to reduce the pointless sys admin tasks the developers were having to do. Although they enjoyed the management and problem solving, and although this stuff was all essential to our service, they were spending their time doing something they didn’t have to do.
“Pointless” sys admin tasks are very pointful tasks, but they are not what differentiates us from our competition. The ability to recover from backups is pretty basic and not what our devops team needs to spend its time on.
This move is no silver bullet. We had to learn Rackspace’s support limits, and we tested at every stage. The most boring and menial tasks up to complex performance issues were sent their way so that, just like a new member of the dev team we know how the service performs.
DBaaS is the same. It isn’t a silver bullet, it’s a new member of your stack, and it might do some stuff well, but you have to understand where its expertise ends.
More DBaaS
Next time, I’ll look at all the MySQL-as-a-service offerings I can find. If you know of one or are one, tweet me – I’d like to hear about it.
I live near the South Downs, a beautiful part of England – all fields, chalk pits, cottages, country pubs – apart from the parts that are motorways, factories, and airports. But this isn’t San Francisco or even Silicon Roundabout, and sometimes I crave some of this nerdy action.
So I Skyped a few people to talk about their products – products I’ve used in production or just played with. This time, instead of telling you how to install it, I thought I’d find out how these guys solved the problem that matters in the cloud: keeping something running all the time and at scale.
Cloud means so many things, it’s almost meaningless. Stuff-as-a-service is so overused it’s become almost a dead phrase. We have milk-delivery-as-a-service and I went to beer-as-a-service this afternoon.
What’s really interesting is how the -as-a-service people build what they build. How they turn machines, operating systems, scripts, and applications into a service that’s better than simply installing the thing and how they bundle a mix of doing-it-at-scale with doing it differently.
Anyone can install something with apt-get and friends, so what makes using someone else’s installation and configuration on the cloud better than installing it yourself?
I’m going to go beyond the press release and beyond the tutorial to find out a little bit about what makes some of these services go. After I looked at Xeround, a cloud database-as-a-service (DBaaS), a couple of months ago, I looked into more DBaaS providers. However, before I get to that, I want to introduce a new concept that was sent my way.
In my kitchen, with laptop perched and Skype running, I talked to David Jilk, CEO of Standing Cloud, which I wrote about recently.
Jilk got in touch with the idea of “Model-Driven Deployment.” His whitepaper peddles the idea that, rather than think of operating at scale as spinning up instances that are configured by someone automating what would normally be done by a human, think of it as a model.
Cloud management systems like Scalr and RightScale and the tools in AWS or Rackspace allow you to automate much of the OS setup with scripts, and this is often missed by firms moving into the cloud. Thinking of an instance as a model – as in OOP – gives you a more structured way of describing and communicating it.
I asked Jilk whether this doesn’t just boil down to scripts. Before his direct answer, “Of course it is just scripting,” he provides a little insight into model-driven deployment:
It is precisely a lot of scripting; however, scripts can be written well or poorly, and they can be designed as software or as hacks. We think the right way to do this is to start to think about the process of deployment not as simply automating something that you would type, but as something that you would build with levels of abstraction, just as you would with models in software.
And, you know, there are various companies doing things with MDD and DevOps that think in similar ways. If you look at Chef and their concept of recipes, where you can combine existing recipes together into larger ones – the idea of modules. You don’t necessarily have to think about what’s inside every time.
Chef, Puppet, RightScale, Scalr, and all the other cloud management tools encourage you to distill your configuration down to scripts. But, as Jilk says, scripts can be done well or badly, and that’s what makes the difference.
“We’ve been moving … away from pure base and PowerShell scripts to Python,” he says, “although there are no particular constraints on which language you use, … so long as it can perform systems operations.”
The problem with the field – automating operating systems and getting OSs to do automated stuff at scale – is that it’s new.
“It’s a toddler,” Jilk says. “I don’t think there are tools that help very much with the building of the actual model.” So whereas tools like Chef and Puppet help deploy the same thing millions of times, nothing exists to help design and build up the model – the abstraction.
So, what does the future hold for deploying “models” of servers or services? The future of encapsulating the behavior of a service? Are modern OSs up to it, or will a native cloud OS emerge?
“What you describe is exactly where things are going to be headed,” Jilk responds, “but it’s very far off. We’ve got a long way to go. We’re still fighting the battle of model-driven deployment vs. virtual appliances, and you’re talking about a pure software view of what a system is. Of course, it is software. We can provision virtual machines via an API call. What shall we call it now? A server allocation? But it’s all software. The whole Internet – including the infrastructure – is software.”
But we’re not there yet. We’re still left running regular expressions on config files on the server’s disk. How old fashioned will this sound in 15 years?
If It Looks Like a Duck, It Isn’t a Duck: It’s NoSQL
There are two ways of offering a low-level cloud service – even a hosting service. Either you wrap up an existing piece of software in the comfort of someone else dealing with the problems for you, or it’s a completely new way of providing the old service. Instead of giving you pages, queries, etc. in the old way, someone finds a way to give you the old stuff in a new and magic way that scales, is more resilient, and is just better than before.
This leads to the next interesting question. What should the server contain? There are two ways of providing a cloud service: a scaled-up, optimized, and supported version of the existing software or a completely new piece of software that looks and behaves like the old one.
Suppose you want to solve the problem of MySQL in the cloud. Services like RDS from Amazon can spin up managed MySQL instances in minutes and provide you with fully hosted MySQL, but maybe a MySQL server isn’t the answer to the MySQL scaling problem. Maybe something that looks like MySQL and behaves like MySQL doesn’t need to be MySQL.
That’s what Xeround gives you, whereas, if you fire up RDS, it is MySQL, Oracle, or Microsoft SQL Server. However, Xeround manages to sell MySQL behavior without running any services.
Xeround doesn’t run MySQL servers behind an API. No MySQL admin is sitting there making sure it’s scaled properly. There’s a heap of NoSQL.
Xeround provides you with a MySQL interface backed by a completely custom driver. But that’s not how it started, as Razi Sharir from Xeround explained:
Xeround was founded back in 2005 with a different premise. Looking to becoming a world leader in telco internal operations and services, it hit the road in 2005, and it was going fairly well along these lines. Running live in a telco is probably the highest recognition you can get for robustness and around a piece of software, oftentimes referred to as telco “grade” or “certification.”
But that wasn’t enough for Xeround:
Around late 2009, the company decided that time to market in a telco environment was too long for a small startup to handle and [we decided] to see what else can be done with [the technology]. Not surprisingly, the cloud came up.
By repurposing the technology, Xeround is about to offer something that MySQL admins have spent years trying to simplify. Instead of working in terms of masters, slaves, and replication, they solve it in a “super simplistic manner” with a NoSQL database that is able to run the required queries at scale. Their DBaaS runs any queries and scales elastically and at high availability.
This is how we ended up from telco guys to cloud guys. The core of the technology is the same that was used in telco … but we’ve upgraded on the front end to extend the SQL coverage, as well as the service side to enable us to run in the wider public cloud across multiple providers.
So, the trick, in a nutshell, from a product perspective: Underneath the hood is no simple database. The closest thing you can think of could be Hadoop. Hadoop, the filesystem, and some algorithms on top of it so we can support any NoSQL beyond that.
According to Sharir, MySQL and other relational DB engines wouldn’t be able to handle the same kind of scale. So, with NoSQL use growing, why wouldn’t developers just switch to NoSQL, such as CouchDB, Mongo, or one of the other large-scale databases designed to solve exactly this system: Internet-level database traffic?
You can see the problems by considering the scenario of a firm that has to solve the problem of scale in their MySQL-driven app. Problems of scaling in databases come down to bottlenecks in the queries, inefficient SQL, and bad indexes, among other things. Some problems can be replaced by simply moving from one database to another – swapping out MySQL for Mongo for session data can be done quickly because the data is self-contained, compared with highly structured data about accounts, transaction history, and the like.
In the past, I’ve seen a project’s performance turned around in an afternoon by using NoSQL for one problem; however, this isn’t replacing MySQL or the relational database, it’s supplementing it. The project of fully replacing MySQL in an existing, in-production product with NoSQL isn’t something many development teams are going to take on.
But, Sharir continues, there’s something else:
CouchDB and other NoSQL DBs are good solutions and do a great job for what they were designed for, but what they were designed for doesn’t support any transactional nor any relational capability, which means most of the commercial applications won’t be able to use them as a core engine. If you’re running any application that does basic credit card or other basic transactions and you want make sure your two- and/or three-phase commit went through, there’s no real way to do it with a simple DB, is there?
All of the NoSQL guys are very good for simple, basic operations on large data sets that scale and are highly available, but when it comes to real applications in the cloud, I don’t quite see it happening.
Do It Yourself?
Moving to cloud isn’t the issue anymore, but how you do it matters.
“So typically,” said Sharir, “when users move to the cloud, the first thing they get hit on is the availability thing because their machines disappear and they don’t have the slightest idea how to bring them back, how to scale them, or how to build them … multiple replicas … this and that.”
This is a huge challenge. I’ve written about some of the tools that can help you, but the mindset is different, and if you don’t have the time to invest in those skills, what do you do?
You can spin things up, but too often this is only to watch them crash later on. What companies like Xeround are doing is building up that skill and management for you.
“The other thing, when they’re on the cloud, is when the first time a major campaign comes in, the traffic comes, and the instance’s aren’t strong enough to handle the load,” said Sharir.
Doing database architecture these days has become more like a patchwork. You don’t chose one big solution, but bring together many.
The paradox that Xeround presents is: You have something that looks like MySQL, but under the hood it’s NoSQL. Why, then, don’t they expose the NoSQL API so you have the relational, traditional perspective on your data and have the cool new NoSQL view as well? Maybe one day.
Reinvent Everything?
Xeround is a really cool answer to an old problem, but reinvention isn’t the only way to solve these problems.
Next time, I’ll cover a service that gives you Postgres at scale and with management, taking more hours away from systems administration, and I’ll look at what you can learn from the choice of big-architecture cloud providers.
I am convinced that over the next few years we will see the end of server admins and, to an extent, developers. If you take into account investment in new projects, time to turn around current projects, and peoples’ unwillingness to throw away what they have invested time and money in, it looks like the shift will be in around five years.
In a little departure from my normal posts, I want to talk about PaaS and how we’ll all be out of a job.
A little while ago, I was at work and got an email linking to Standing Cloud, who have taken what several cloud providers offer and wrapped it up in a platform – well, actually, lots of platforms.
You can run on AWS, Rackspace, GoGrid, and several other cloud hosting providers, but the nice thing about their platform is you fire up preconfigured instances set up with any one of a wide range of open source apps on around 10 cloud providers – and you need no technical knowledge to do so.
The march of infrastructure and provisioning toward the user is exactly where Standing Cloud is taking us. Instead of the tedious provision of instances via the IT department or through the person who owns the AWS account, the end user with almost no technical knowledge can fire up an instance and get to work within minutes.
Choose the last five project that annoyed you because they were distractions from what you really wanted to do. Someone wants a WordPress site. Someone else needs a test build of Magento. SugarCRM is being looked at by the Marketing Department and the Marketing Director wants to review it.
Instead of this setup time going to the devops team (which is what we all are now, even if just a little bit), marketing directors can spin up instances themselves. Now, your marketing director might not feel comfortable doing this right now, but soon it’ll feel like signing up for any other site.
And that’s what Standing Cloud feels like to me.
To get started, sign in with your Google, Yahoo, or Facebook ID, and you’re presented with a list of just over 102 apps.
Launching an app is a matter of selecting it, deciding which cloud to deploy to, then starting it. This is convention over configuration to a high degree; you stick with their convention and while configuration is available, you might as well be launching your own instances on EC2.
For example, we have been testing things on a vanilla installation of the Concrete 5 CMS for a prospective client, and instead of installing it manually, we simply start up an instance via Standing Cloud and we’re done. Same goes for Drupal. Instead of going to all the effort of installing something that you might not use or need, you fire up an instance and try it out.
One of my favorites, OpenVBX gives you a cloud-based phone system. Neat.
To get going with OpenVBX, just log in, select start with a test drive before selecting OpenVBX from the apps. Pick a version (a reassuring bit of detail here, so you can see which version works for you).
Next up are the data centers/locations. Because you launch the instance, you confirm all the details and spin it up. This is the kind of thing you could automate, build in Rails in a short time, or just offload onto any other human in your company, saving you time to spend more time on Stack Overflow.
Once it’s running, you wait for it to launch. It’ll appear a few moments later in My Applications with all the usual login data – web login info plus the SSH details.
Having just created your first OpenVBX server, you can start patching calls, linking them up with your API, and generally being productive without the pain of anything at the server level. If you haven’t tried OpenVBX, it works with Twilio and hooks into their service to provide routed calls, voicemail, and interaction with external APIs.
Something for the First-Timer
Installing OpenVBX from source on a server takes maybe 30 minutes if you’re a tech and have a server running or a machine image ready. But that’s not the point and that’s not the case PaaS solves.
With Standing Cloud, all this effort can be delegated to a non-tech in the marketing department, IT procurements, or whoever. They don’t have to wait for you to get around to it. But, for the ever impatient nerd, you can ssh into the instance and get under the hood.
What else does it give you? (Or help you avoid dealing with?)
Aside from deployments from Git and managing backups and recovery (and who doesn’t want to give that up?), you can scale. Scaling is done either in a fairly basic way by resizing the machine or across multiple web heads using load balancers.
To see how they did scaling on AWS and Rackspace doesn’t take long. Standing Cloud enables you to resize instances, and it looks like all they’re doing is calling out to AWS and Rackspace to resize the instances. To resize an instance on AWS, for example, you just stop it, resize it to a bigger or smaller instance type, and start it up again. Standing Cloud provides a wrapper around this with an app to boot.
All this works perfectly for trying out apps and small- and medium-scale hosting, and it would suit a lot of internal apps that IT departments need to provision.
Some apps can be spun up on multitier architecture launched last October and is still in alpha. Their multitier platform can run on nine different cloud providers and run more than 10 applications. To get this running, you configure the web and database tiers, setting the number and size of the nodes you need. All this is pretty easy to configure, with the caveat that it’s easy to spend too much or underspec your machines.
Now for my “and finally” bit …
And Finally
Why does this matter for those of us who love the nuts and bolts and would prefer to configure the servers ourselves? Two big reasons. First, it’s nice to see another architecture described using the practices we know about. Standing Cloud’s site describes their launch sequence as:
- We start with a clean server image from the cloud provider of your choice. Once the server is active, we run a series of scripts that get the server ready to host one of our 90+ supported applications and platforms. The steps are different depending on which stack the application requires.
This translates to: Keep the image clean and use config management and automated builds to get the software running. Do not fill up your images with anything that’s going to change or isn’t completely generic. The OS and basic requirements are pretty much all your need.
A nice line from the same page gives insight into how your configuration needs to change as your cloud instances change:
- We then mathematically apply some configuration tweaks to Apache, PHP, and in some cases MySQL based on the size of the server that was allocated.
Read this as: Your config matters, so don’t just throw the same config up everywhere. Memory limits, query cache sizes, and the like need to be configured based on the instance size, memory, and CPU.
This has been a much less technical post. But it’s an important one. Cloud doesn’t mean we nerds get more stuff to play with, it means we get less to do because the provisioning, configuration, and management of apps is moving closer and closer to the person who makes the decision.
Like Heruko, this is PaaS, but this platform is closer to something like SalesForce or Basecamp because it can take no technical knowledge to get the thing going, even if technical knowledge might help expend it.
I can see a day when starting a new CMS or CRM project requires the business owner just to punch in their credit card details to a service’s registration form. From then on, most stuff will be handled for them.
Until then, it’s a race to see who can build it first. And that’s going to be fun.
Imagine what projects you’ve done this year that could be delivered if the CMS, CRM, Blog, or database could be turned on and just delivered to your user. And what does this mean for infrastructure teams and developers?
In the short term, cheat. Use Standing Cloud and similar PaaS systems as shortcuts. In the long term, maybe you can build the PaaS that does your whole job through point and click.
Get a better picture – load test the cloud. Load testing is never finished. I’ve spent a good couple of days testing something only to find it slow down when in production, so when do you decide: “That’s it. Ship it”? Is there something lurking in there that’s going to hurt you on the first day in production?
Too often, I’ve seen people get hung up on one or two load times as an indicator of their entire app, so here I’m going to look first at those numbers and then I’ll look at using a curve to describe your app’s performance. Things always look better when they have a graph, don’t they?
In this post, I’m going to stop short of testing POST requests and interaction through lots of screens – that will be for another day. This time, I’ll look at thinking beyond the load time on a couple of screens to viewing the range of page performance your users get.
Siege
Here’s the scene: You have an app ready to ship and you want to know how it’ll behave when it gets the 2 million hits the marketing guy is sure it deserves. To do this, you work out what the peak number of concurrent users will be and blast it with that number.
A tool like siege creates a set number of requests in one of a few modes. By default, it behaves like a normal user, delaying between hits, but it can also be set to benchmark the site by not delaying between hits.
For example (sorry, owners of example.com!),
siege -c 30 http://www.example.com
creates 30 concurrent users to hit the site. The stats you get back are useful:
Lifting the server siege... done. Transactions: 422 hits Availability: 100.00 % Elapsed time: 11.79 secs Data transferred: 2.47 MB Response time: 0.22 secs Transaction rate: 35.79 trans/sec Throughput: 0.21 MB/sec Concurrency: 7.85 Successful transactions: 437 Failed transactions: 0 Longest transaction: 2.59 Shortest transaction: 0.07
Now don’t fall into the trap of measuring everything with one number. Don’t look at the Availability line and think a number near 100 percent means everything is fine. It isn’t. You need to look at the outliers, the longest transaction, failed transactions, and unavailability to find out how bad it’ll be for some users.
If your shortest transaction is 0.01seconds but your longest is 30 seconds, you will be hit. Hard. I don’t mean your server will be hit, I mean you’ll be hit by that marketing guy when his campaign worked but your servers didn’t. (As he sees it.)
For example, if your app’s page relies on five hits on the web stack (assuming you pushed all static assets to S3 or something static), the probability that each user is affected by a 1 percent failure rate (i.e., 100 percent minus availability) increases because scaling that 1 percent of failed hits doesn’t mean just 1 percent of users.
(On a side note: you should urge your developers to degrade their app gracefully so that if the Ajax calls fail, the user still has a good experience or at least a decent error message. Even so, focus on keeping those servers up.)
So, how do you find out what it’s like for more users?
Some other basic options you should use are -t, which sets the time your site is put under siege. Don’t skimp on this because apps behave different after a prolonged battering, as caches build up and the cache system misses more than it hits. Run it for a good 20 or 30 minutes and see what starts to melt first.
siege -t 600 -b http://www.example.com
For debugging --get should be used. This works like --save-headers in wget, so you can make sure you’re getting back what you expect.
Don’t assume short response means everything is completely fine. It has to be the right kind of response. A brilliant “gotcha” I’ve seen is someone benchmarking a server that is spitting out 404s like there’s no tomorrow because the app crashed after 20 concurrent hits.
With the -f option, you can pass a file of URLs to be tested, which can be used for getting down to the really problematic parts of your app. Give it those pages you hate the most:
# simple homepage http://www.mynewapptotest.com/ # A page that's never cached: http://www.mynewapptotest.com/no-cache-here.php # A page that processes POST data http://www.mynewapptotest.com/login.php POST user=dan&pass=hello-there # Some search pages http://www.mynewapptotest.com/search?q=find+me
To run this, pass the file to siege:
siege -f urls.txt
So, that’s a few users, some URLs and some post data. Now I’ll take it up a notch.
The -b option benchmarks the server. There’s no delay between hits on the server so the only limit is your computer’s memory and connection to the web. Unfortunately, they can be limiting, so how can you create a really good benchmark?
Microarmy
You need a microarmy. Before this was written and in the days before AWS, you would grab all the servers you could from various data centers and batter each server. Then, when AWS came about, you’d spin up a dozen servers and use Capistrano to attack your little cluster.
But stand on the shoulders, as they say: You can deploy 100 vicious little siege slaves in “106 seconds.”
On with looking at the numbers …
If you are planning to plot the results, you almost certainly don’t want to write down the results each time. The siege log by default is held in /usr/local/var/siege.log and contains all the data recorded on each of the tests run. Of course, you can copy this into a Google doc or a spreadsheet to give yourself a nice-looking graph.
Date & Time, Trans, Elap Time, Data Trans, Resp Time, Trans Rate, Throughput, Concurrent, OKAY, Failed 2012-01-09 20:49:17, 8108, 414.12, 4, 0.78, 19.58, 0.01, 15.18, 8175, 72 2012-01-09 20:49:30, 68, 2.38, 0, 0.45, 28.57, 0.00, 12.76, 85, 0 2012-01-09 21:09:21, 84, 4.84, 0, 0.29, 17.36, 0.00, 5.09, 90, 0 2012-01-09 21:09:47, 80, 4.51, 0, 0.36, 17.74, 0.00, 6.38, 90, 0 2012-01-09 21:10:00, 92, 4.42, 0, 0.35, 20.81, 0.00, 7.22, 100, 0 2012-01-09 21:12:15, 78, 4.38, 0, 0.33, 17.81, 0.00, 5.92, 85, 0
Now for another tool.
ab
I used siege for a long time but then found I wasn’t getting a real picture of the end-user’s experience. I was looking at availability with fewer than 200 concurrent benchmark users and thinking, “looks good for most hits.” I needed a more detailed picture of what was happening for the users. I was doing exactly what I started talking about: using one number to describe the experience of a wide range of users.
Apache Benchmark – ab – is a similar tool, and the syntax follows what you’ve seen so far for siege:
ab -n500 -c10 http://www.example.com/
A heap of options are offered with ab, such as outputting results to a CSV file and adding arbitrary headers. Once you issue this command, you get output similar to siege, but it gives you a very useful result on how many were served and in what percentile.
Percentage of the requests served within a certain time (ms) 50% 1988 66% 2212 75% 2931 80% 3267 90% 3721 95% 4278 98% 5990 99% 6521 100% 6521 (longest request)
Web users are looking for consistency, so you should expect most of the responses to be around the same time. If you have too much variation over too large a time difference, your site will look erratic. Everything on websites is about consistency. If you can be consistent at one second, then do so if the alternative is 20 percent of users getting under a second and the rest getting 10 seconds.
Now I’m getting to something really useful, which will tell you more about your users’ experience than two or three response times. The next option to look at is -e my-output.csv, which will output a more detailed version of this report to a file that you can plot:
ab -e my-output.csv -n 100 -c 10 http://example.com/
Unlike taking an average, which can be heavily skewed toward lots of good results and hide a couple of really bad ones, this gives you the data for each percentile. So, although the first 1 percent of response times might be a snappy 500ms, if the top 1 percent is more than 10 seconds, you can see something to worry about. This is especially true for complex apps that use several Ajax requests or web sockets, in which case one in 50 connections being slow could end up affecting more users. The lower the point at which the response times increase rapidly, the more worrying because this means more of your users are seeing a slow site.
Sticking with the command line because it’s comfy there, push this data into gnuplot. If you strip off the first line of the file, you can plot it in gnuplot with:
set datafile separator "," plot 'my-output.csv' with lines
This can tell you much more about the behavior of your app than the response rate maximum load time.
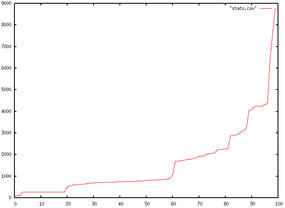
Figure 1: CSV file from ab -e in gnuplot.
Figure 1 is an example with response times on the y-axis and percentiles of users on the x-axis. You can see the response times climbing slowly and then rocketing as the server isn’t able to deliver the responses. Finally, when you reach a certain point, you hit the limit at which the server is simply not available.
With this chart, you can run some really interesting tests and get some telling data out out of the system.
To turn this into a script, you pull in a little sed magic:
ab -e output.csv -n 10 -c 5 http://www.i-am-going-to-test-this.com/ sed 1d output.csv > stats.csv echo ‘set datafile separator “,”; plot “stats.csv”’ | gnuplot -persist
Increasing the number of current users (the -n flag) step by step gives you a series of graphs of the performance behavior of your app. So now, instead of one number saying 95 percent of hits will be OK, you can see the behavior changing as the number of users increases. Instead of picking a random concurrency number to benchmark, you can find the problem points and tackle them.
Back in the Cloud
Now I’ll bring all this back to the cloud. When you’re designing and testing your cloud architecture, you need to consider failure and the effect of failure. Load testing isn’t just seeing how much traffic you can cope with but seeing how much traffic a degraded cluster can cope with.
What happens if you kill half the web heads but the load stays the same? By plotting the response times rather than taking a single number and by gradually changing the number of concurrent users, you get a much better picture of what your users will be writing on Facebook when your site slows down.
And, you get to redesign your cloud architecture as if you’d already suffered the failure.
Sure the cloud is great for managing failure, but what if a whole data center goes down?
Failure in the cloud usually means that an instance disappears. As I've described in the past, this can be due to anything from a physical failure to a problem with the cloud infrastructure itself. Dealing with failure means you have to be able to bring back the entire environment on a different infrastructure, and do it easily. You'll see this written all over the place but how can you do it?
First, let's look at what kinds of failure can occur. After a recent cloud outage, cloud architects filled twitter with the the wise observation that failure can occur at the instance, data-center, region, or cloud level. You need to plan for failure at all these levels.
The instance that's running at the moment might fail, and you should be OK with this, but planning for this kind of failure should be a matter of launching the same kind of instance and installing the required OS, apps, and code to get your site running again.
A failure at this level is annoying but isn't a huge problem. All the network connections, data, and API capabilities still exist where they were before the instance failed, so getting the same environment up and running again doesn't require any change in your plan.
The data center level is also dealt with for you by the cloud provider. They should be running multiple data-centers, and failure of anything in a single location shouldn't matter; as for the instance failure, a failure at the data-center level shouldn't often concern you. The environment to re-launch a similar instance is the same.
That said, some cloud providers are smaller, and if a data center fails for them, it's going to have an impact on how you can recover... which leads us to the nastier levels of failure.
A failure at the geographical region is significantly nastier. This has happened twice for Amazon, and I have experienced problems with other providers.
The first failure AWS experienced was caused by a networking issue
(see http://aws.amazon.com/message/65648/)
exacerbated by what was termed a re-mirroring storm, but the effect was simple: an entire geographical region was unavailable to AWS customers wanting to launch new instances.
The second occurred in the EU region and was caused by a power failure, but the effect was the same: an entire geographical region was unavailable for some important operations for a time.
Expert cloud architects must plan for this level of failure, but how do they do it? How do you build on top of things that might fail to the point that the system never fails?
Let's pretend an entire region goes down. This is a failure that many people don't plan for, nor is it one that many are able to plan for when they start out.
Amazon offers Elastic Block Store (EBS) storage volumes that are are separate from the instance and, according to Amazon “persist independently from the life of the instance.” You can use EBS to back up a snapshot of the instance.
Suppose you have an instance running on AWS in the EU. It is EBS-backed, so you can make a snapshot of it to move it.
First, set the availability zone in which the new volume must be created:
ec2-create-volume --snapshot snap-abc123ab --availability-zone us-east-1
But this solution wouldn't have helped earlier this year, when a failure occurred in the US East region. To prevent a regional failure, also always back your data up to a region where it doesn't run normally. Backing up into the same region where your instance are currently running is like keeping your backups on the same disk.
When your region fails, and your sites are instantly down, what can you do?
You need to launch a new instance with all your data on it in a different region. On AWS you simply switch to another region and start a similarly size instance, as long as you have made sure that everything you need to run your app exists somewhere else.
The checklist is:
- Make sure the code and data exist outside of the region you're running in. Also, be sure the Amazon Machine Image (AMI) you're using is available in other regions.
- Setting a low TTL on your DNS can help you make changes in the event of all out failure, but you might also want to get a third-party load balancer to insulate you from the failure of an entire cloud.
- Work through a complete list of failure paths, providing solutions for every failure scenario. What happens when an instance fails? Where do you recover it? What happens when the region fails? How do you get the recent data out of it? What happens when the cloud provider fails -- even if it's just their API? How do you get the data out to start somewhere else?
I've gone from calm, through cautious, to all out paranoid, and I've used the word "failure" too many times, but if you want your site up all the time, design it paranoid.
Heroku is platform as a service (PaaS). Instead of all that infrastructure, servers, and complications, you have a platform that is managed for you.
With the move to cloud computing, particularly cloud hosting, developers often opt for infrastructure as a server rather than PaaS. Why would you go PaaS?
The first reason is that you have less to do. The infrastructure and coordination of resources are managed for you, and on Heroku, they’re managed in a particularly cool way. Everything – from the moment you push to their Git repo – is managed for you, removing the need to configure servers, databases, and all that junk.
Heroku started off hosting just Rails, but now it also hosts Java and Node.js. To get started, you sign up on their site and simply – as is always the way with anything Ruby-ish – install a gem:
gem install heroku
Heroku’s CLI tool is where a lot of the magic happens. Start the magic by creating a new project:
heroku create
Log in at https://api.heroku.com/myapps, and you’ll see some insanely named app: vivid-robots-9999. You can look at the URL for the app, but there isn’t anything there to see yet, so you need to push up a Rails app.
Copy the Git URL from the app’s detail page (e.g., git@heroku.com:vivid-robot-9999.git) and clone it to a local repo:
$ git clone git@heroku.com:vivid-robot-9999.git Cloning into vivid-robot-9999... warning: You appear to have cloned an empty repository.
Create a Rails app, add it to Git, and push:
cd name-of-project/ rails new . git add . git commit -m “Empty rails app” git push origin master
As you push, you’ll see a number of things that Git doesn’t normally say:
-----> Heroku receiving push
-----> Ruby/Rails app detected
-----> WARNING: Detected Rails is not declared in either .gems or Gemfile
Scheduling the install of Rails 2.3.11.
See http://devcenter.heroku.com/articles/gems for details on specifying gems.
-----> Configure Rails to log to stdout
Installing rails_log_stdout... done
-----> Installing gem rails 2.3.11 from http://rubygems.org
Successfully installed activesupport-2.3.11
Successfully installed activerecord-2.3.11
Successfully installed actionpack-2.3.11
Successfully installed actionmailer-2.3.11
Successfully installed activeresource-2.3.11
Successfully installed rails-2.3.11
6 gems installed
-----> Compiled slug size is 4.7MB
-----> Launching... done, v4
http://vivid-robot-9999.heroku.com deployed to Heroku
Rails is a great platform for PaaS because it is inherently self-contained. Dependencies are declared in the Gemfile, from which everything can be installed. Once you push to Heroku, all required gems are installed, and the app is deployed.
Heroku creates a pipeline for the code from the moment you push, so when finished, your app is deployed. If you have ever had to deal with pulling onto other servers, configuring them and wasting all that time, this is going to look like magic.
Hit the URL of your app,
http://vivid-robot-1992.heroku.com/
and, Bam …, you have deployed your app.
Now, I'll create something simple. Because Heroku integrates so nicely with Rails – or, more accurately, with the Git process – it’s worth noting that Rails projects can integrate directly with Heroku. The Rails CMS Refinery has hooks to push directly to Heroku.
Finally, some nice add-ons provide services, such as MongoDB, Redis, on-demand video encoding, and cloud DNS for Heroku. Just like the underlying web servers, proxies, and all that, you don’t manage this. The working platform is what comes as a service.
If you have a Rails projects, push it to Heroku and see if it’ll work there, because it could save you a load of sys admin work.
But what do you lose? Why wouldn’t you use PaaS?
PaaS is very limiting. The problem lots of Java and Python developers had with Google App Engine (and this is from bar conversations, rather than from trawling the web) is that simple things like the filesystem aren’t there anymore. You can’t reconfigure the web server. All those niceties.
But, this is a good thing. Even if you don’t use PaaS, such as Heroku or App Engine, in your day job, experiencing the efficiency of deployment is worth the investment. All code pipelines should be a matter of push-and-deploy, which they often aren’t, simply because you have access to the config, the filesystem, and all those old reliable bits and pieces.
How does PaaS fit in with your stack? Could it replace those big servers you love so much?
Meter’s running - How to avoid spending all your money—
Ever been in a cab, stuck in traffic watching the meter run. You watch each 50-cent increment nudge the fair up dollar by dollar, wondering if it would be quicker to walk.
Cloud hosting is charged the same way, but it’s very easy to take your eye off the meter, fire up dozens of services, store gigabytes of files, and end up spending a fortune.
I’ve left instances sitting around for days and even weeks. Between myself and our lead architect, we somehow forgot about an RDS instance for a few days, racking up charges for a machine that wasn’t even being used.
It doesn’t matter what platform you use: If it’s pay as you go, you’ll want to monitor it to prevent your $1,000-a-month bill turning into $10,000 a month.
In the tradition of programmers being lazy but resourceful, I’ve thrown together a little script using the Ruby cloud computing library fog that shows you which services are running and roughly how much they’re charging in the current hour.
The script simply connects to AWS, finds each of the main chargeable services (I’ve only done EC2, RDS, and S3 so far … feel free to contribute), and uses a table of costs to find the upper limit of costs. Because AWS tiers its price (the second million gigabytes of storage cost less than the first), the estimated costs will probably be higher than you are charged at the end of the month, but it’s better to be safe ….
Write the Script
The first few lines list the instances I use and their costs. Because I’m only working in a couple of regions, I’ve left the costs approximate.
instance_costs = {
't1.micro' => 0.02,
'm1.small' => 0.095,
'c1.medium' => 0.19,
'm2.2xlarge' => 1.14,
'm2.4xlarge' => 2.28
}
Then I list the regions. This could have been dynamic, but I don’t want to check in the [asia??] regions, so I’ve listed them.
regions = [ 'eu-west-1', 'us-west-1' ]
And finally, I need the account details. Because I run multiple accounts for dev, test, and production for multiple clients the account details are in a hash.
accounts = {
'myaccount' => {
'key_id' => 'YOUR-KEY-HERE',
'access_key' => 'YOUR-ACCESS-KEY-HERE'
}
}
The script uses 'fog' [URL], which means you could adapt it to work with GoGrid, Rackspace, or whichever cloud provider you use.
The rest of the script simply loops through the accounts, then through the regions, and shows you how much you’re spending in the current hour and what that might be at the end of the month. It’s easy to forget that $1 an hour is $744 dollars a month.
Run the Script
$ ruby cost-checker.rb For region 'eu-west-1' i-abc123ab....................: $ 0.19 i-def456de....................: $ 0.095 i-hij789hi....................: $ 0.095 Total for account : $ 0.48 Projected monthly for account : $353.40
Pretty useful. If an instance is stopped, it is shown because you won’t be charged for it.
i-aaa111aa....................: $--.-- [stopped]
EC2 isn’t by any means the only way to rack up charges. You need to consider storage (S3, EBS snapshots, and CloudFront), bandwidth, and any other services you’re using. This script should help you keep an eye on the meter.
The script is available on github at https://github.com/danfrost/Cloud-costs. Just clone it and run … then realize how much you should be saving.
Here's a quick tip for managing AWS keys a little differently—
All the tutorials you'll find refer to downloading the generated private key from the AWS console. This is fine for the first 10 times you create instances or cloud setups, but the time will come when you want to use the same key for lots of instances or you want to use your own keys all the time.
AWS has an "import keypair" method than can be reached easily using the AWS CLI tools. This command takes a public key and uploads it to your AWS account so that instances can be launched with it.
If you haven't already installed the AWS CLI tools, grab them from the Amazon EC2 API Tools website and put them in /usr/local/ec2-api-tools/. Add the environment variables:
export EC2_HOME=/path/to/ec2-tools/ export PATH=$PATH:$EC2_HOME/bin export EC2_PRIVATE_KEY=`ls -C $EC2_HOME/pk-*.pem` export EC2_CERT=`ls -C $EC2_HOME/cert-*.pem`
With this installed, you have access to loads of the API that isn't always exposed via GUIs – a nice chance to get under the hood.
Start by generating an ssh key-pair in the usual way:
ssh-keygen
And follow the instructions. This generates two files: the public key, id_rsa, and the private key, id_rsa.pub.
It's the public key that you need to upload, using the ec2-import-keypair command:
ec2-import-keypair dan-key --public-key-file ~/.ssh/id_rsa.pub
Using the ec2-describe-keypairs command, you can see the newly uploaded keypair:
ec2-describe-keypairs KEYPAIR dan-key fc:39:b2:60:90:4c:0f:66:fc:b8:a6:54:af:19:0c:ef KEYPAIR my-key a6:54:af:19:0c:ef:fc:39:0f:66:fc:b8:b2:60:90:4c KEYPAIR your-key fc:39:b2:60:90:4c:af:19:0c:ef:0f:66:fc:b8:a6:54
Instances can now be launched using the key by firing off the ec2-run-instances command:
ec2-run-instances ami-abc123ab -k dan-key
Finally, if you want to generate keys on the fly, the CLI tools can help you do this with the ec2-add-keypair command. This works in reverse to the ec2-import-keypair command by generating the key on AWS and passing the private key back to you:
ec2-add-keypair my-new-key KEYPAIR dangen1 aa:ce:ec:ae:bb:18:f3:cb:cc:ee:95:c3:fe:86:5b:09:f9:ae:18:ff -----BEGIN RSA PRIVATE KEY----- +PgLSIcy+rHHELXhv6bvZGamd2R2u2DFhBo36w9DEjAhocW2hraXMIIEowIBAAKCAQEAhXo2cUYv B8/P/BP0ges6i7VJ9Oj1bDHfILtu805syqwN5J6IBcgvesthq4Xpj4zuIVsCctU5SEIkx9texM+b .... fuy3QFJdl3rM0w/ry1QDRy5WgfZsIpAQZUuCaZgZx2BavviuVcFGrd67RfP6gt2yBk7EhN0gQCN2 X5YHEueK7qLqQYNsX4X9JROKgB0zMdaJvmCqekvoGhQepx5C4TqrDWIOHAwHOw6V6nqZ ----END RSA PRIVATE KEY-----
So, when would you import a key rather than generate one? If you have limited permissions on your local machine or if you want to create instances from a known set of keys, uploading the key makes more sense.
If you have a strong internal security policy and need to keep keys in rotation, uploading the public keys will be better than having any number of keys generated on AWS.
You can find out more about this command at the AWS CLI docs: http://docs.amazonwebservices.com/AWSEC2/latest/CommandLineReference/index.html?ApiReference-cmd-ImportKeyPair.html
The guys at Netflix, who built the ChaosMonkey app I talked about last time, say that, in the move to cloud, you have to be prepared to unlearn everything you know about hosting.
Cloud hosting differs in one important way. You can trace many cloud architectures, applications, and best practices back to this difference. Every time you plan an architecture, it comes back to the same thing.
Cloud instances are transient.
One of the tools to work around instances disappearing is configuration management. Anyone who has run more than a handful of servers will have used config management, whether home-spun or through a tool like Chef or Puppet.
So configuration management isn't really a cloud-specific topic, but it does make things a hell of a lot easier for you.
Configuration management manages the O/S and software stack running on top of each instance. Large data-centers have used this kind of thing for years to update hundreds of servers at once because it saves time. For anyone working with just a few servers, it doesn't make sense to spend time and money on something that you can do in a few minutes manually.
But cloud instances are transient. They will probably die, and when they do, who's going to configure them? Not you, if you have any sense. The config management kicks in, installs all of the required packages, and uses your preferred configuration.
You can use tools such as Chef and Puppet, but to start with, let's do the poor man's configuration using a bash script.
The following script - ok pseudo script - installs Apache, grabs your code from S3, and starts the server up.
apt-get -y install apache2 cd /tmp wget -O your-code.tgz http://my-bucket.s3.amazonaws.com/your-project.tgz mkdir tmp-extract && cd tmp-extract tar xzf your-project.tgz mv * /var/www/vhosts/ service apache2 restart
Once this is done, the instance is up and running with your app.
To inject this into an EC2 instance when it boots up, thereby creating an cloud instance that actually does something, you can make use Ubuntu's CloudInit script.
If you're on AWS, you can punch in the user data on boot up (Figure 1).
CloudInit makes the instance do stuff when it boots up, which is a really good way to get around bundling everything into images all the time.
To use this, just shove the script from above in the “runcmd:" section - e.g.
runcmd:
- apt-get -y install apache2
- cd /tmp
- wget -O your-code.tgz http://my-bucket.s3.amazonaws.com/your-project.tgz
- mkdir tmp-extract && cd tmp-extract
- tar xzf your-project.tgz
- mv * /var/www/vhosts/
- service apache2 restart
Sticking with the poor man's config management system, you can still make things a little nicer by pushing the script to S3 and then downloading it from there:
runcmd:
- wget -O boot-up-script.sh http://my-bucket.s3.amazonaws.com/boot-up-script.sh
- chmod +x boot-up-script.sh && ./boot-up-script.sh
This way you can version the script in git, try it out on a vanilla instance (and isn't cloud all about trying stuff out cheaply). When you're happy, push it up to S3 and all your new instances will start up with the new version.
Soon I'll cover chef and puppet for config management, but these tools rely on your ability to get the app running 100% from a script. There can be no human help in the cloud.
Do you have a home-spun config system like this? Many do. Or are you using a different, off-the-shelf system? I'd like to hear how you've solved this problem.
Until next time...