The YARN Invitation
The Big Data world has heard continued news about the introduction of Apache Hadoop YARN. YARN is an acronym for “Yet Another Resource Negotiator” and represents a major change in the design of Apache Hadoop. Although most HPC users might believe they don’t need another scheduler or support for big data MapReduce problems, the continued growth of YARN may change that opinion. If anything, YARN could represent a bridge between traditional HPC and the Big Data world.
Hadoop version 1 offers an ecosystem of tools and applications that is based on the data-parallel MapReduce paradigm: MapReduce jobs can operate on very large files using the Hadoop parallel filesystem (HDFS). As opposed to many HPC clusters in which storage and compute are done on separate servers, Hadoop combines the two processes and attempts to move computation to servers that contain the appropriate data. Although MapReduce has been shown to be very powerful, the ability to operate on data stored within HDFS using other non-MapReduce algorithms has long been a goal of the Hadoop developers. Indeed, YARN now offers new processing frameworks, including MPI, as part of the Hadoop infrastructure.
Please note that existing “well oiled” HPC clusters and software are under no threat from YARN. Later, I’ll cover some fundamental design differences that define different use cases for YARN and traditional HPC schedulers (SLURM, Grid Engine, Moab, PBS, etc.) On the other hand, YARN does offer the exciting possibility of bringing HPC methods, ideas, and performance to the vast stores of institutional data sitting in HDFS (and other parallel filesystems).
Hadoop 101
Although Apache Hadoop versioning can be a bit confusing, the most recent version (as of June 6, 2013) of Hadoop YARN is 2.0.5-alpha (Note: The software is more stable than the “alpha” tag might indicate). Hadoop version 1 is also continuing to be developed (without YARN), which is available as release 1.2.0. There are some other Hadoop releases that could cause confusion when you’re ready to download, but in general, the 0.20.X branch is version 1, and the 0.23.X branch is version 2.
To understand what YARN is and why it is needed, some background on Hadoop may be helpful. A discussion on Hadoop, MapReduce, and YARN from an HPC perspective can be found in a previous article, Is Hadoop the New HPC?
Version 1 of Hadoop has two core components. The first is HDFS, which is part of all Hadoop distributions. Note, however, that HDFS is not explicitly tied to Hadoop and can, in theory, be used by other applications in a serial or parallel fashion. The second component is the monolithic MapReduce process, which contains both the resource management and the data processing elements needed for parallel execution. The Hadoop Version 1 MapReduce process is shown in Figure 1.
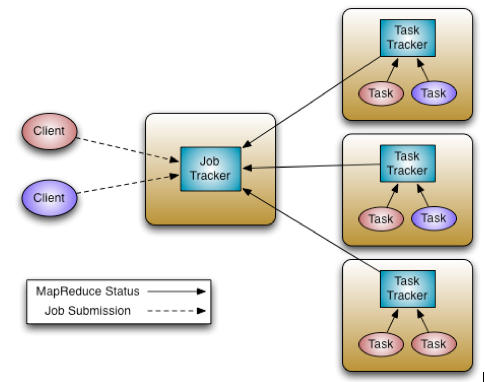 Figure 1: Hadoop version 1, MapReduce architecture (courtesy Apache Hadoop).
Figure 1: Hadoop version 1, MapReduce architecture (courtesy Apache Hadoop).
A master process called the JobTracker is the central scheduler for all MapReduce jobs in the cluster and is similar to the master daemon of an HPC scheduler (e.g. sge_qmaster in Grid Engine or pbs_server in Torque). Nodes have a TaskTracker process that manages tasks on the individual nodes. The TaskTrackers, which are similar to node daemons in HPC clusters (e.g. sge_execd in Grid Engine or pbs_mom in Torque) communicate with and are controlled by the JobTracker. Similar to most resource managers, the JobTracker has two pluggable scheduler modules, Capacity and Fair .
The JobTracker is responsible for managing the TaskTrackers on worker server nodes, tracking resource consumption and availability, scheduling individual job tasks, tracking progress, and providing fault tolerance for tasks. Similar to many HPC nodes, the TaskTracker is directed by the JobTracker and is responsible for launch and tear down of jobs and provides task status information to the JobTracker. The TaskTrackers also communicate through heartbeats to the JobTracker: If the JobTracker does not receive a heartbeat from a TaskTracker, it assumes it has failed and takes appropriate action (e.g., restarts jobs).
One key feature of Hadoop is the use of a simple redundancy model. Most Hadoop clusters are constructed from commodity hardware (x86 servers, Ethernet, and hard drives). Hardware is assumed to fail and thus processing and storage redundancy are part of the top-level Hadoop design. Because the MapReduce process is “functional” in nature, data can only move in one direction. For instance, input files cannot be altered as part of the MapReduce process. This restriction allows for a very simple computation redundancy model in which dead processes on failed nodes can be restarted on other servers with no loss of results (execution time may be extended, however). Moreover, HDFS can be configured easily with enough redundancy so that loosing a node or rack of nodes will not result in job failure or data loss. This “non-stop design” has been a hallmark of Hadoop clusters and is very different from most HPC systems that accept the occasional hardware failure and subsequent job termination.
The monolithic MapReduce design is not without issues, however. As Hadoop clusters have grown in size, pressure on the JobTracker increases with regard to scalability, cluster utilization, system upgrades, and support for workloads other than MapReduce. These issues have been the rationale for Yet Another Resource Negotiator for Hadoop clusters.
YARN Framework Architecture
When designing YARN, the obvious change was to separate resource management from data processing. That is, MapReduce had to be decoupled from workload management. As part of the decoupling, it would also be possible to create other data processing frameworks that could run on Hadoop clusters. These changes, from Hadoop version 1 to Hadoop version 2, are shown below in Figure 2.
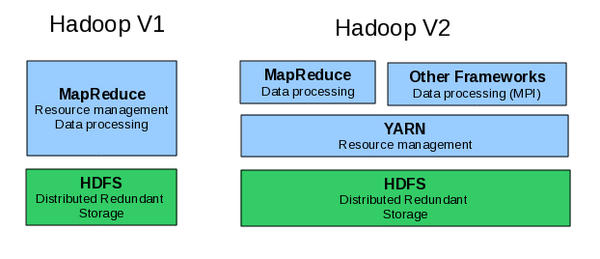 Figure 2: Hadoop version 2 splits the scheduling and data processing tasks.
Figure 2: Hadoop version 2 splits the scheduling and data processing tasks.
MapReduce has now become “just another framework” that is managed by YARN. Great effort, however, has gone into keeping the YARN MapReduce functionality backward compatible with existing Hadoop version 1 MapReduce jobs. Existing MapReduce programs and applications, such as Pig and Hive, will continue to run under YARN without any code changes. Also note that HDFS remains an “independent” core component and can be used by either Hadoop version 1 or version 2. An update of HDFS is expected later this year.
The job of YARN is scheduling jobs on a Hadoop cluster. Breaking out scheduling from data processing required a more complex relationship between jobs and servers. As such, YARN introduces a slew of new components: a ResourceManager, an ApplicationMaster, application Containers, and NodeManagers. The ResourceManager is a pure scheduler. Its sole purpose is to manage available resources among multiple applications on the cluster. As with version 1, both Fair and Capacity scheduling options are available.
The ApplicationMaster is responsible for accepting job submissions, negotiating resource Containers from the ResourceManager, and tracking progress. ApplicationMasters are specific to and written for each type of application. For example, YARN includes a distributed Shell framework that runs a shell script on multiple nodes on the cluster. The ApplicationMaster also provides the service for restarting the ApplicationMaster Container on failure.
ApplicationMasters request and manage Containers , which grant rights to an application to use a specific amount of resources (memory, CPU, etc.) on a specific host. The idea is similar to a resource slot in an HPC scheduler. The ApplicationMaster, once given resources by the ResourceManager, contacts the NodeManager to start individual tasks. For example, using the MapReduce framework, these tasks would be mapper and reducer processes. In other frameworks, the tasks are different.
The NodeManager is the per-machine framework agent that is responsible for Containers, monitoring their resource usage (CPU, memory, disk, network), and reporting back to the ResourceManager.
Figure 3 shows the various components of the new YARN design, with two ApplicationMasters running within the cluster, one of which has three Containers (the red client) and one that has one Container (the blue client). Note that the ApplicationMasters run on cluster nodes and not as part of the ResourceManager, thus reducing the pressure on a central scheduler. Also, because ApplicationMasters have dynamic control of Containers, cluster utilization can be improved.
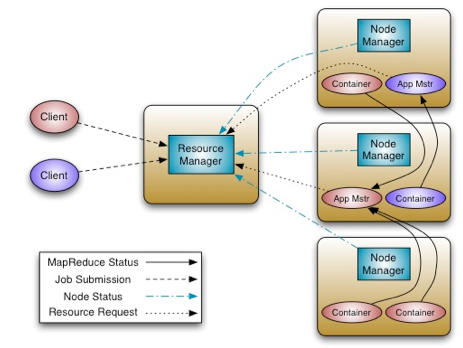 Figure 3: Hadoop version 2, YARN architecture (courtesy Apache Hadoop).
Figure 3: Hadoop version 2, YARN architecture (courtesy Apache Hadoop).
YARN supports a very general resource model. User applications, through the ApplicationMaster, can request resources with specific requirements, such as the amount of memory, number of cores (and type), and specific hostnames, racknames, and possibly more complex network topologies. Eventually support for disk/network I/O, GPUs, and other resources will be provided as well.
In addition to better scalability, utilization, and user agility, the design of YARN has introduced the possibility of multiple frameworks that go beyond MapReduce. As mentioned, MPI is a logical choice for such a framework; others include Apache Giraph, Spark, Tez, Hadoop Distributed Shell, and others that are under development.
MPI and YARN
The prospect of running MPI jobs under YARN is an enticing proposition. As mentioned, the vast stores of data now living in HDFS can be accessed by non-MapReduce applications like those written in MPI. (Please note, however, that the intimate interface of MapReduce to HDFS is part of the MapReduce framework and is not automatic in other frameworks and must be managed by the user’s application.)
The prospect of running Open MPI under YARN has been investigated by Ralph H. Castain of the Open MPI team. YARN was compared with the SLURM HPC scheduler as a platform for running Open MPI applications. The results heavily favored SLURM because of some of the fundamental design differences between the two approaches to cluster resource utilization.
Hadoop is designed around heartbeat communication between nodes. Unlike most HPC schedulers, there is no global status information on nodes. All status and task assignment is done via the heartbeat connections, which occur 200 times a second. This design also forces N linear launch scaling, whereas SLURM has log N launch scalability, resulting in mush faster start-up times (N being the number of nodes). YARN has no internode communication on start-up, which precludes collective communication for wire-up exchange. Additionally, Hadoop clusters are exclusively Ethernet based with no support for native InfiniBand communication.
Because of these issues, the MR+ (MapReduce Plus) project was started as a way to bring the Hadoop MapReduce classes to general-purpose HPC clusters. In essence, MR+ is designed to eliminate YARN altogether and use existing HPC resource managers to launch and run parallel MapReduce jobs using an MPI framework. MR+, although still under development, provides an effective way for existing HPC clusters to integrate Hadoop MapReduce with other traditional HPC applications.
The YARN heartbeat design, while inefficient for large-scale start-up, has a distinct advantage in terms of hardware failure and job recovery. Recall that in the Hadoop MapReduce design, node failure is expected and managed in real time – jobs do not stop. Recovery in Open MPI and SLURM environments is not as easy because global state information and coordinated action are needed to respond to failures. Thus, a trade-off between easy failure recovery and performance separates the two approaches. Recall that Hadoop clusters have combined nodes that are used for both the filesystem (i.e., HDFS) and processing (e.g., YARN frameworks); thus it requires a cleaner failure model than most HPC clusters where filesystem hardware is separate from computation hardware.
An Invitation
YARN brings new, exciting capabilities to Big Data clusters. In particular, the prospect of running MPI applications on a Hadoop cluster could open up a whole new mode of Big Data processing. To be clear, YARN is not intended as a replacement for existing HPC clusters where entrenched, mature resource managers meet the needs of current technical computing users. YARN can be viewed as an invitation to bring many of the skills and lessons learned in the MPI HPC world to the ever-growing world of Big Data.
If you are interested in testing YARN or learning more, you can visit the official Apache Hadoop YARN site. The Hortonworks site also has a preview of an upcoming book on YARN called Apache Hadoop YARN: Moving Beyond MapReduce and Batch Processing with Apache Hadoop 2 . If you look closely, you may recognize one of the authors.
Related content
-
Big data tools for midcaps and others
 Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis. -
Hadoop for Small-to-Medium-Sized Businesses

Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
-
Is Hadoop the New HPC?

Hadoop has been growing clusters in data centers at a rapid pace. Is Hadoop the new corporate HPC?
-
Is Hadoop the new HPC?
 Hadoop has been growing clusters in data centers at a rapid pace. Is Hadoop the new corporate high-performance computing?
Hadoop has been growing clusters in data centers at a rapid pace. Is Hadoop the new corporate high-performance computing? -
MapReduce and Hadoop

Enterprises like Google and Facebook use the map–reduce approach to process petabyte-range volumes of data. For some analyses, it is an attractive alternative to SQL databases, and Apache Hadoop exists as an open source implementation.