Hadoop for All
Every company, from a small online store to a multinational group, collects detailed data about daily events. The events range from purchase transactions, through the effect of marketing initiatives, to the company’s social media activities. This huge volume of unstructured data – big data – promises to deliver valuable insights and abundant material for decision making. If you want to benefit from this information, you have to face the challenge of big data.
SQL, NoSQL, Hadoop
Conventional big data solutions still lug around the legacy of an ecosystem built around a database – whether SQL or NoSQL. Astronomical licensing costs take them virtually out of the reach of medium-sized enterprises, especially if high-availability features are desired.
The biggest bottleneck in these solutions is often the database, because it typically will only scale beyond the boundaries of individual servers with considerable administrative overhead. Conventional data analysis methods and relational databases can reach their limits. Even some cloud solutions do not scale without mandatory downtime. One possible way out of this dilemma is Hadoop.
Apache Hadoop is a framework for distributed processing of, in particular, unstructured data on computer clusters. Hadoop makes it possible to run computational processes at low cost, whether on-premises on commodity hardware, at a data center, or in the virtualized environment of a cloud service provider.
Hadoop Features
Access to an ordinary relational database relies on queries in one of the many dialects of SQL (Structured Query Language). If you need to access non-relational databases, other languages besides SQL are possible (hence the term NoSQL). Hadoop does not fall into these two categories, because it simply does not use a database; it is this distinction that lends Hadoop its flexibility and robustness.
Hadoop consists of two basic components: the Hadoop Distributed File System (HDFS) and a distributed, modularized data processing framework: Hadoop uses MapReduce 1.x, whereas Hadoop 2.x relies on either MapReduce or its successor YARN (discussed later).
The role of HDFS is to provide the most efficient, fastest possible fail-safe storage of the data. HDFS is not a “clusterized” filesystem but a distributed one: It runs on multiple nodes in a network – but without an expensive SAN solution. HDFS is therefore very cost efficient.
The data processing framework talks to the filesystem, which manages the resources and monitors the execution of the commands sent by a Hadoop-compatible application on the framework. These commands form jobs, and jobs are implemented as individual, tiny Java applications.
Thanks to this architecture, workloads can be spread across multiple nodes of a computer cluster, and the cluster itself can be reconfigured even while performing jobs. This approach results in several important advantages. For example, Hadoop scores points with its ability to scale as needed, without downtime. This elasticity is useful not only if the amount of data sharply increases or decreases but also if deadlines make temporary provisioning of additional computational resources desirable.
As the load on the active nodes increases, additional nodes can be started automatically, for example, using Amazon API AWS autoscaling. In this case, the cloud uses CloudWatch to monitor the load on the individual instances. Once the conditions set by the administrator are met, AWS automatically launches new server instances that are integrated into the Hadoop cluster, registered with the resource manager, and then finally able to take on jobs.
Hadoop also works in a very resource-friendly way; instead of copying large amounts of data back and forth across the network between different nodes, as is the case with many RDBMSs, it sends comparatively small instructions exactly to where the required data already exists. In a database running on multiple servers, the data typically is stored separately from the software logic and on different instances. In contrast, in a Hadoop cluster, both data and the data processing logic exist on each machine. This setup means that the framework can run individual jobs very efficiently: on the instance holding the required data in each case. The redundancy resulting from distributed data processing also improves the robustness of the cluster.
A variety of free and commercial tools exist to enhance Hadoop with additional capabilities. For example, with the Apache Hive open source application, you can convert SQL queries into MapReduce jobs and address Hadoop as a (distributed!) SQL database.
Highly Sought Skills
If you follow developments in the US IT job market as a benchmark for future trends, you will find that the need for Hadoop skills is skyrocketing (Figure 1). This is little wonder, because the framework has many practical applications. In Germany, too, job offers relating to big data with Hadoop are on the increase. For example, recruiter Hays AG is looking for Java developers, software architects, and system administrators with Apache Hadoop skills for different locations throughout Germany. JobLeads GmbH tried to recruit nearly a hundred Hadoop-savvy IT professionals in the same period on behalf of unspecified customers.
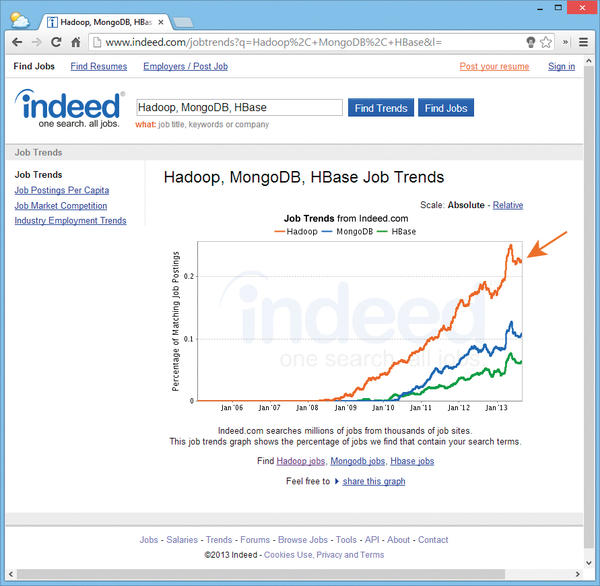 Figure 1: Trends on the US labor market promise Hadoop-savvy IT professionals a bright future.
Figure 1: Trends on the US labor market promise Hadoop-savvy IT professionals a bright future.
According to a study by IDC, the worldwide market for Hadoop has an annual growth rate of 60 percent. However, the same study also stated that this rate of growth is limited almost exclusively to the use of Hadoop as elastic and cheap distributed mass storage.
Although Hadoop is a world leader in the field of data analysis, it is precisely this functionality that often seems to lie fallow in practical applications. Hadoop users with lower development capacities understandably tend keep their growing datasets on the low-cost HDFS and use external, but less powerful solutions to handle data analysis. The reason for this is obvious: MapReduce in Hadoop 1.x is perceived by many as too complicated and not sufficiently flexible. Hadoop 2.x seeks to remedy the situation and help achieve wider dissemination of the powerful big data framework.
Applications and Examples
Practical applications of Hadoop are very diverse. They include: analyzing web clickstream data to optimize conversion rates, evaluating sensor data of machinery for the optimization of production processes, analyzing server logfiles for improved security, making forecasts on the basis of geolocation data, data mining of social media activities for a better understanding of the target audience, statistical processing of search indexes and RFID data – the list never ends.
Banks and insurance companies use applications based on Hadoop to rate clients on the basis of their financial history using pattern recognition algorithms. This approach helps financial institutions put a stop to credit card abuse, among other things, and better assess the creditworthiness of their customers in the scope of risk management.
In e-commerce and online and mobile advertising, Hadoop is used to compute product recommendations. The behavior of a visitor in your own webshop and on social media serves as the basis for exploring the visitor’s preferences. Data centers, telcos, and web hosting providers use Hadoop-based solutions to identify bottlenecks or errors in networks at an early stage by evaluating network traffic statistics. Another example is algorithms for analyzing the meaning of text messages. Some e-commerce providers and telecommunications service providers use this technique to evaluate customer requests.
Solutions based on Hadoop also let you combine several different data sources and thus create multidimensional analyses.
One of the pioneers in the use of Hadoop for multidimensional data analysis is the gaming industry. After all, casinos are particularly vulnerable: Fraud occurs, and they can lose a lot of money in a few minutes. Analytics solutions for big data have proven their value in fraud detection and in exploring the target audience. Thanks to big data, casino operators can create granular customer profiles. The Flamingo Hotel of Caesars Entertainment in Las Vegas alone employs 200 big data analysts. Specialized analytics solutions for the gaming industry, such as Kognitio, are based on Hadoop.
Game chips, customer loyalty cards, and even liquor bottles in bars like Aria Hotel and Casino are equipped with RFID tags. This technology makes it possible to track activities in real time. Casinos consistently analyze all these acquired values as finely granulated data. “Casinos employ the most talented cryptographers, computer security experts and game theorists” says John Pironti, the chief information risk strategist with data protection specialists Archer Technologies.
Security technologies such as video surveillance or RFID tracking produce huge amounts of data. Relevant data are never discarded because they are just too valuable, and this is where Hadoop enters the game – as a distributed filesystem. While casinos are experimenting with these innovations, companies in other industries are trying to apply their experiences to their own business.
On the basis of Hadoop, tailor-made solutions can be programmed to manage data assets more efficiently. An example of this is Red Bull Media House GmbH’s Media Asset Management (Figure 2). Germany’s ADACOR Hosting GmbH from Essen tested multiple solutions for media asset management on behalf of the Austrian company. The task was to create a central repository of content, such as video clips, photos and audio files, in various formats and at various quality levels so that customers could quickly and easily access this data at any time from anywhere.
 Figure 2: The media asset management platform of Austria’s Red Bull Media House GmbH is based on HDFS.
Figure 2: The media asset management platform of Austria’s Red Bull Media House GmbH is based on HDFS.
The requirements included elastic scalability without maintenance windows, minimal downtime for hardware glitches, data replication, fast data delivery, ease of management, and a better cost-benefit ratio than standard solutions such as EMC storage could offer. The shortlist included, among other options, NFS, GlusterFS, Lustre, Openfiler, CloudStore, and finally HDFS.
As an initial approach, NFS was investigated as a very popular, stable, and proven filesystem in the Unix world. NFS disappointed ADACOR with its poor performance and lack of features such as data replication. The resulting application would have had to handle distributed storage management itself. The overhead would have been just too great.
The second candidate under the microscope was GlusterFS. ADACOR Hosting GmbH already had some good experience with this filesystem in a different context, especially in terms of performance. As the number of nodes in a GlusterFS cluster increases, so does the maximum data throughput. What disqualified GlusterFS in the eyes of the testers was its very high administrative overhead and impractical scalability with mandatory downtime.
Lustre impressed in terms of performance, scalability, and convenient administration, but this solution also lacked robust replication at the time of implementation. Openfiler dropped out of the shortlist, because the system took several days to complete a rebuild of only 3TB of data. CloudStore was rejected by ADACOR because of a lack of stability. Only HDFS impressed across the board and most closely met the customer’s requirements.
Big Data: A Question of Flexibility
A myth that stubbornly persists in the IT industry is that big data is only usable or affordable for large enterprises. Midcaps almost all self-evidently and firmly believe you cannot even think about big data unless you have petabytes of data. Nothing could be further from the truth. Even if you “only” have datasets of 10 or 50TB, Hadoop is still a useful solution. Big data is not about a certain amount of data but about the lack of data structure.
Actually, the question is not whether a company qualifies for big data. Many companies face a very different challenge: a data management problem. A proprietary data warehouse will quickly reach the capacity limits of a single machine, which is how isolated data silos initially emerged. If you want to gain actionable insights from data, you need a distributed cluster filesystem like HDFS, which grows with the requirements, and a framework like Hadoop.
For midcaps, no factual or financial reasons exist for not using big data. Admittedly, the most vocal users of Hadoop include some of the biggest names in IT, social media, and the entertainment industry, including Amazon Web Services, AOL, Apple, eBay, Facebook, Netflix, and HP. However, Hadoop 2.2.x is especially appealing for smaller companies with tight budgets: It is easy to program, free, platform independent, and open source.
The biggest challenge to using Hadoop is by no means financial; rather, it stems from a lack of know-how. The first step is to leverage the low-budget data processing capabilities and rugged data protection with Hadoop. After the company has begun to reap the benefits of these cost reductions, it can then expand its own data analysis activities. Only at this stage does it make sense to employ data scientists to pursue more challenging questions using data analysis solutions based on Hadoop.
Next-Gen MapReduce
The changes in Hadoop 2.2.0 are profound and thoughtful. The innovations are based on modularization of the engine. This bold step is designed to enrich the Hadoop ecosystem, adding plugins and other enhancements. It also promises additional flexibility for the Hadoop administrator. For example, the admin can already replace some built-in algorithms with external modules to benefit from extended functionality. This is true of, for example, shuffle and sort. These modules can be used in parallel and even combined with the built-in algorithms.
The key new features in version 2.2.0 include the introduction of YARN (Yet Another Resource Negotiator) as an optional replacement for MapReduce. MapReduce in Hadoop 1.x (Figure 3) is not optimal for all workloads. It achieves its best performance where duties can be clearly distributed and parallelized. Many shortcomings of MapReduce are things of the past, however, following the introduction of YARN.
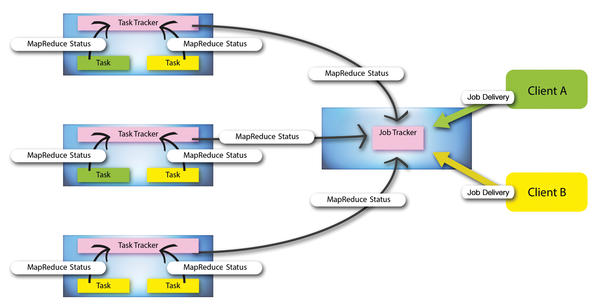 Figure 3: Hadoop 1.x relies on hard partitioning of the existing resources in the cluster, which in turn results in less than optimal use of the available capacity. Jobs that could not be distributed by Map() and Reduce() ran accordingly slower.
Figure 3: Hadoop 1.x relies on hard partitioning of the existing resources in the cluster, which in turn results in less than optimal use of the available capacity. Jobs that could not be distributed by Map() and Reduce() ran accordingly slower.
YARN is a development of MapReduce version 2 (MRv2). YARN is based directly on HDFS and assumes the role of a distributed operating system for resource management for big data applications (Figure 4).
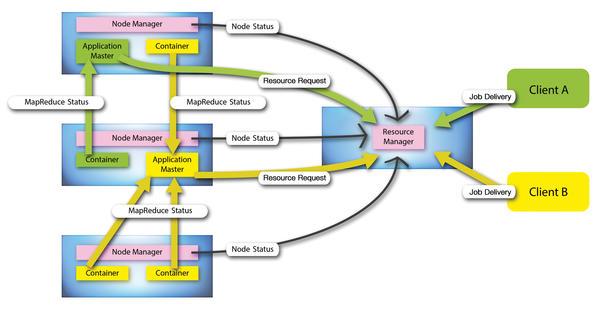 Figure 4: The architecture of Hadoop 2.x: Resource management by YARN is based on logical units of resource containers; requesting resources is now separated from the application logic.
Figure 4: The architecture of Hadoop 2.x: Resource management by YARN is based on logical units of resource containers; requesting resources is now separated from the application logic.
Thanks to YARN, you can use Hadoop 2.2.x to interweave interactive workloads, real-time workloads, and automated workloads (see the box “Big Data Applications with Support for YARN”).

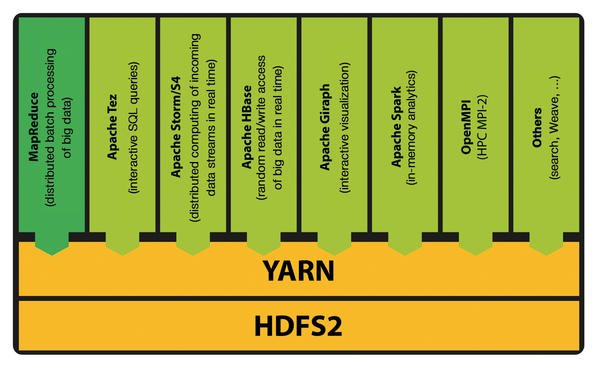 Figure 5: Applications with support for YARN in Hadoop 2.x: MapReduce is now a module in user space and is binary-compatible with legacy applications from Hadoop 1.x.
Figure 5: Applications with support for YARN in Hadoop 2.x: MapReduce is now a module in user space and is binary-compatible with legacy applications from Hadoop 1.x.
Additionally, YARN is backward-compatible with MapReduce at the API level (hadoop-0.20.205); at the same time, it improves Hadoop’s compatibility with other projects by the Apache Software Foundation. If you insist on using the legacy version of MapReduce, you can now load it as a module. This should not be necessary, however, because MapReduce applications are binary-compatible between the two generations of Hadoop.
The most important change in YARN compared with the classic MapReduce is allocation of the two job tracker functions – resource management and time management/workload monitoring – to two separate daemons: the global ResourceManager (RM) and the job-specific ApplicationMaster (AM).
The ResourceManager comprises two components: the scheduler and the application manager. The scheduler is responsible for allocating resources to different active applications but is not responsible for monitoring the workloads. The scheduler takes into account both the resource requirements of individual applications as well as the capacity limitations of the cluster.
In the current version, the scheduler, unfortunately, can only manage one resource: memory. In future versions of YARN, it will be possible to allocate CPU cycles, storage, and network bandwidth to the cluster’s individual applications.
Resources are allocated by partitioning resource containers. These are virtual compute entities in a cluster node, and a node can possess several such containers. The application manager (the second basic component in the Resource Manager besides the scheduler) accepts workload orders. To do this, the application manager initiates the process of setting up the first resource container for the ApplicationMaster and launches it (or reboots it after a crash). The application-specific ApplicationMaster requests the necessary resource containers from the scheduler (the scheduler is part of the ResourceManager) and begins to monitor them.
HDFS has two types of server or cluster nodes: NameNodes and DataNodes. NameNodes manage the metadata, and the actual data blocks are kept on the DataNodes. A separate NodeManager is responsible for each node in the cluster (i.e., each single machine). It monitors the use of container resources and reports the current activities of the respective nodes to the ResourceManager/Scheduler.
The new architecture allows for significant cost savings (Figure 5). Yahoo estimates the improvements achieved in node utilization to be 60 to 150 percent per day. Yahoo tested YARN with 365PB of data with 400,000 jobs on 40,000 cluster nodes and a total computation time of 10 million hours. A high-availability implementation of the YARN ResourceManager is planned for a future release.
HDFS2
HDFS has always been considered reliable. During use at Yahoo on 20,000 nodes in 10 clusters, HDFS errors were only responsible for the loss of 650 data blocks out of a total of 329 million in 2009. Since then, the Apache Foundation has worked intensively on improving the reliability of HDFS.
Despite its reliability, HDFS in Hadoop v1 had a clear single point of failure: the NameNode, which is the control center for managing access to data via metadata. Although NameNodes were redundant, they could only be operated in an active/passive node architecture. If an active NameNode failed, the administrator had to adjust the configuration manually. Thus, the failure of a single NameNode could potentially take down the whole HDFS; all active write processes and jobs in the queue were canceled with an error message.
The implementation of mission-critical workloads that need to run interactively in real time was thus very problematic.
The Hadoop developers identified the problem and came up with a solution: the high-availability NameNode (HA NameNode). The HA NameNode waits on the bench and can step in when needed for the active NameNode. In Hadoop 2.0, this failover can still only be triggered through manual intervention by the Hadoop administrator.
HDFS Federation
To scale the name service horizontally, Hadoop uses 2.2.0 Federation with several completely independent NameNodes and namespaces. The NameNodes remain independent by not coordinating their work. All NameNodes independently access a common pool of DataNodes. Each of these DataNodes registers with all the NameNodes in the cluster, periodically sending a heartbeat signal and block reports and accepting commands. An implementation of symlinks was planned for this release but canceled at the last minute.
HDFS Snapshots
Snapshots of the HDFS filesystem also make their debut in Hadoop 2.x. These are non-writable copies of the filesystem that capture its state at a defined time (point-in-time copies).
No DataNodes are copied for an HDFS snapshot. The snapshot only captures the list of data blocks and the size of the files. The process has no negative effect on other I/O operations. Changes are recorded in reverse chronological order, so the current data can be accessed directly. HDFS2 computes the data status for the snapshot by subtracting changes from the current state of the filesystem.
The operation usually does not require any additional memory (unless writes occur in parallel). To allow snapshots, the administrator uses the following command with superuser privileges:
hdfs dfsadmin -allowSnapshot <path-to-snapshot-capable-directory>
The directory tree in question can then be grabbed as a snapshot using the owner’s user rights, as follows:
hdfs dfs -createSnapshot <path-to-snapshot-capable-directory>[<snapshotName>]
Or, you can use the Java API.
To mark the path to the snapshots, the HDFS2 developers have created a .snapshot object. If this string appears in the HDFS filesystem of your Hadoop installation, you must definitely rename the objects in question before upgrading; otherwise, the upgrade fails.
Distributions
An entire ecosystem of specialized solutions has emerged around Hadoop. Apache’s Hadoop distribution primarily addresses providers of big data tools that build their own (commercial) solutions. This category includes, among others, Cloudera, Hortonworks, IBM, SAP, and EMC.
For mission-critical use of Hadoop, a Hadoop distribution with 24/7 support by a service provider such as Cloudera or Hortonworks can actually be beneficial. However, these providers make you pay quite handsomely for this privilege. If you do not need a service-level agreement, you can instead choose the free versions of these distributions. Additionally, Hadoop distributions have been specially created for small to mid-sized companies, such as Stratosphere by the Technical University of Berlin.
Stratosphere
Stratosphere combines easy installation with ease of use and high performance. The platform also scales to large clusters, uses multicore processors, and supports in-memory data processing. It also features advanced analytics functionality and lets users program jobs in Java and Scala.
Stratosphere is developed under the leadership of Professor Volker Markl from TU Berlin’s Department of Database Systems and Information Management (DIMA). Stratosphere runs both on-premises and in the cloud (e.g., on Amazon EC2).
Hadoop Services
Growth-oriented midcaps can choose from a wide range of Hadoop services. Amazon offers Elastic MapReduce (EMR), an implementation of Hadoop with support for Hadoop 2.2 and HBase 0.94.7, as well as the MapR M7, M5, and M3 Hadoop distributions by MapR Technologies. The service targets companies, researchers, data analysts, and developers in the fields of web indexing, data mining, logfile analysis, machine learning, financial analysis, scientific simulation, and bioinformatics research.
For customers who want to implement HBase, Elastic MapReduce with M7 provides seamless splits without compression, immediate error recovery, timing recovery, full HA, mirroring, and consistent low latency. This version does involve some additional costs, however. Google (with Compute Engine) and Microsoft (with Azure) have their own implementations of Hadoop.
Using Hadoop as a service in the cloud means less capital outlay on hardware and avoids delays in the deployment of infrastructure and other expenses. Amazon EMR is a good example because of its clear pricing structure. In EMR, you can only set up a Hadoop cluster temporarily so that it automatically dissolves after analyzing your data, thus avoiding additional charges. Prices start at US$ 0.015/hour per instance for the EMR service, plus the EC2 costs for each instance of the selected type (from US$ 0.06 per instance), which are also billed on an hourly basis.
Thus, you would pay US$ 1.50 for one hour with 100 instances for Hadoop (100 x US$ 0.015) and up to US$ 6.00 for up to 100 instances that run on-demand (100 x US$ 0.06). The bottom line is that you are billed for US$ 7.50 per hour for 100 small instances. To keep costs down even further, you could reserve these instances for up to three years.
Numbering
Hadoop developers have not done themselves any great favors with their choice of version numbers. If you identify remarkable development steps with a version number change in the second decimal place – say, from version 0.20 to version 0.23 – you should not be surprised if users take very little note of your progress.
Version 0.20 designates the first generation Hadoop (v1.0, Figure 6).
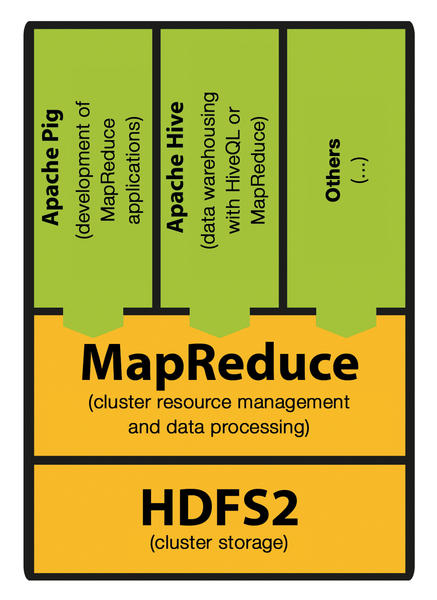 Figure 6: Just for comparison’s sake: In Hadoop 1.x, all applications were dependent on the use of MapReduce.
Figure 6: Just for comparison’s sake: In Hadoop 1.x, all applications were dependent on the use of MapReduce.
Whenever you hear people refer to the 0.23 branch (Figure 7), they are talking about Hadoop 2.2.x. The version number 2.2.0 refers to the first release of the second generation with general availability.
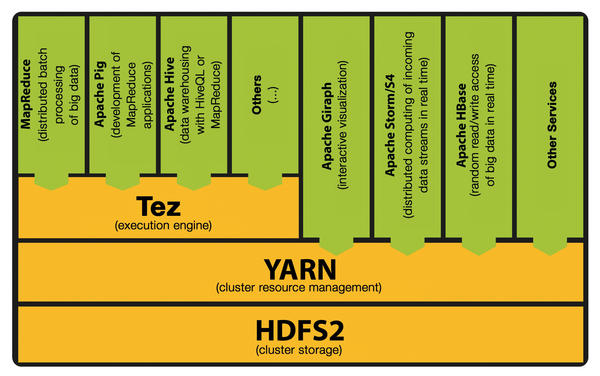 Figure 7: Hadoop 2.x stack with Apache Tez: performance improvements with data processing in cluster memory.
Figure 7: Hadoop 2.x stack with Apache Tez: performance improvements with data processing in cluster memory.
An enterprise-class product that has proven itself in the tough big data daily grind for years should have earned a higher version number. The seemingly minimal generation leap to version 2.2.0 does little justice to the significantly advanced maturity of Hadoop; however, the hesitant numbering does not detract from the quality of Hadoop.
The growing importance of Hadoop is evidenced by the many prominent providers that are adapting their commercial solutions for Hadoop. SAP sells the Intel distribution and the Hortonworks Data Platform for Hadoop. SAP Hana, a data analysis platform for big data, seamlessly integrates with Hadoop. DataStax provides a distribution of Hadoop and Solr with its own NoSQL solution, DataStax Enterprise. Users of DataStax Enterprise use Hadoop for data processing, Apache Cassandra as a database for transactional data, and the Solr search engine for distributed searching. Incidentally, Cassandra lets you run Hadoop MapReduce jobs on a Cassandra cluster.
Conclusions
After four years of development, Hadoop 2.2.0 surprises its users with some groundbreaking innovations. Thanks to its modularity and HA HDFS, the Apache Foundation has succeeded in keeping ahead of the field and even extended its lead.
Because of its significantly improved management of workloads, Hadoop has become much more attractive for midcaps. Large companies have always been able to tailor any additional functions they needed, whereas painstaking development has always overtasked the midcaps. This situation has now finally changed with Hadoop 2.2.0.
Related content
-
Big data tools for midcaps and others
 Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis. -
The New Hadoop

Hadoop version 2 expands Hadoop beyond MapReduce and opens the door to MPI applications operating on large parallel data stores.
-
Is Hadoop the New HPC?

Hadoop has been growing clusters in data centers at a rapid pace. Is Hadoop the new corporate HPC?
-
Is Hadoop the new HPC?
 Hadoop has been growing clusters in data centers at a rapid pace. Is Hadoop the new corporate high-performance computing?
Hadoop has been growing clusters in data centers at a rapid pace. Is Hadoop the new corporate high-performance computing? -
OpenStack Sahara brings Hadoop as a Service
 Apache Hadoop is currently the marketing favorite for Big Data; however, setting up a complete Hadoop environment is not easy. OpenStack Sahara, on the other hand, promises Hadoop at the push of a button.
Apache Hadoop is currently the marketing favorite for Big Data; however, setting up a complete Hadoop environment is not easy. OpenStack Sahara, on the other hand, promises Hadoop at the push of a button.