The RADOS object store and Ceph filesystem: Part 2
In an earlier article, ADMIN magazine introduced RADOS and Ceph [1] and explained what these tools are all about. In this second article, I will take a closer look and explain the basic concepts that play a role in their development. How does the cluster take care of internal redundancy of the stored objects, for example, and what possibilities exist besides Ceph for accessing the data in the object store?
The first part of this workshop demonstrated how an additional node can be added to an existing cluster using
ceph osd crush add 4 osd.4 1.0 pool=default host=daisy
assuming that daisy is the hostname of the new server. This command integrates the host daisy in the cluster and gives it the same weight (1,0) as all the other nodes. Removing a node from the cluster configuration is as easy as adding one. The command for that is:
ceph osd crush remove osd.4
The pool=default parameter for adding the node already refers to an important feature: pools.
Working with Pools
RADOS offers the option of dividing the storage of the entire object store into individual fragments called pools. One pool, however, does not correspond to a contiguous storage area, as with a partition; rather, it is a logical layer consisting of binary data tagged as belonging to the corresponding pool. Pools allow configurations in which individual users can only access specific pools, for example. The pools metadata , data , and rbd are available in the default configuration. A list of existing pools can be called up with rados lspools (Figure 1).
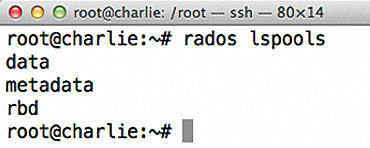 Figure 1: Listing all current pools in RADOS.
Figure 1: Listing all current pools in RADOS.
If you want to add another pool to the configuration, you can use the
rados mkpool <Name>
command, replacing <Name> with a unique name. If an existing pool is no longer needed,
rados rmpool <Name>
removes it.
Inside RADOS
One of the explicit design goals for RADOS is to provide seamlessly scalable storage. Admins should be able to add any number of storage nodes to a RADOS object store at any time. Redundancy is important, and RADOS takes this into account by managing replication of the data automatically, without the admin of the RADOS cluster having to intervene manually. Combined with scalability, however, this process results in a problem for RADOS that other replication solutions don’t have: How to distribute data optimally in a large cluster.
Conventional storage solutions generally “only” make sure data is copied from one server to another, so in the worst case, a failover can be executed. Usually, such solutions only run within one cluster with two, or at most three, nodes. The possibility of adding more nodes is ruled out from the beginning.
With RADOS, theoretically, any number of nodes could be added to the cluster, and for each one, the object store must ensure that its contents are available redundantly within the whole cluster. Not the least of developers’ problems is dealing with “rack awareness.” If you have a 20-node cluster with RADOS in your data center, you will ideally have it distributed over different multiple compartments or buildings for additional security. For that setup to work properly, the storage solution must know where each node is and where and how which data can be accessed. The solution RADOS developers – above all RADOS guru Sage A. Weil – came up with consists of two parts: placement groups and the Crush map.
Placement Groups
Three different maps exist within a RADOS cluster: the MONmap, which is a list of all monitoring servers; the OSDmap, in which all physical Object Storage Devices (OSDs) are found; and the Crush map. OSDs themselves contain the binary objects – that is, the data actually saved in the object store.
Here is where placement groups (PGs) come into play: From the outside, it seems as if the allocation of storage objects to specific OSDs occurs randomly. In reality, however, the allocation is done by means of the placement groups. Each object belongs to such a group. Simply speaking, a placement group is a list of different objects that are placed in the RADOS store. RADOS computes which placement group an object belongs to by using the name of the object, the desired replication level, and a bitmask that determines the sum of all PGs in the RADOS cluster.
The Crush Map
The Crush map, which is the second part of this system, contains information about where each placement group is found in the cluster – that is, on which OSD (Figure 2). Replication is always executed at the PG level: All objects of a placement group are replicated between different OSDs in the RADOS cluster.
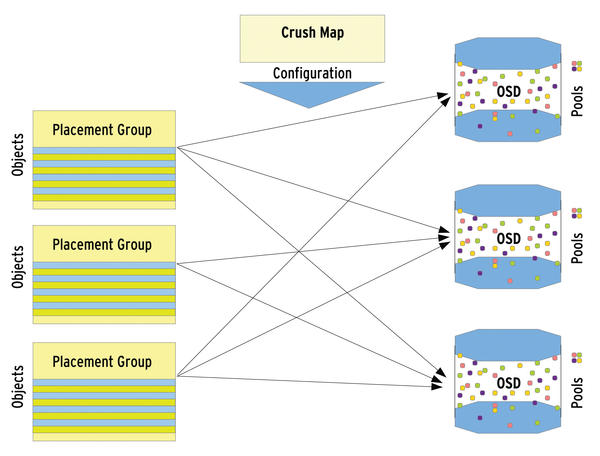 Figure 2: The elements of the RADOS universe, whose interaction is controlled by the Crush map.
Figure 2: The elements of the RADOS universe, whose interaction is controlled by the Crush map.
The Crush map got its name from the algorithm it uses: Controlled Replication under Scalable Hashing. The algorithm was developed by Weil specifically for such tasks in RADOS. Weil highlights one feature of Crush in particular: In contrast to hash algorithms, Crush remains stable when many storage devices leave or join the Cluster simultaneously. The rebalancing that other storage solutions require creates a lot of traffic with correspondingly long waiting periods. Crush-based clusters, on the other hand, transfer just enough data between storage nodes to achieve a balance.
Manipulating Data Placement
Of course, the admin also has a word to say about what data lands where. Practically all parameters that pertain to replication in RADOS can be configured by the admin, including, for example, how often an object should exist within an RADOS cluster (i.e., how many replicas of it should be made). Of course, the admin is also free to manipulate the allocation of the replicas to the OSDs. Thus, RADOS can take into account where specific racks are. Rules for replication specified by the admin control distribution of the replicas from placement groups to different OSD groups. A group can, for example, include all servers in the same data center room, another group in another room, and so on.
Administrators can define how the replication of data in RADOS is done by manipulating the corresponding Crush rules. The basic principle is the neither the allocation of the placement groups nor the results of the Crush calculations can be influenced directly. Instead, replication rules are set for each pool; subsequently, distribution of the placement groups and their positioning by means of the Crush map are done by RADOS.
By default, RADOS includes a rule that two replicas of each object must exist per pool. The number of replicas is always set for each pool; a typical example would be to raise this number to three, as is done here:
ceph osd pool set data size 3
To make the same change for the test pool, data would be replaced by test . Whether the cluster subsequently actually does what the admin expects can be investigated with ceph -v .
The use ceph in this kind of operation is certainly comfortable, but it does not provide the full range of functions. In the example, the pool continues to use the default Crush map, which does not consider properties such as the rack where the server is. If you want to distribute replicas according to such properties, you have to create your own Crush map.
A Crush Map of Your Own
With your own Crush map, you as administrator can have the objects in your pools distributed any way you want. crushtool is a valuable utility for this purpose because it creates corresponding templates. The following example creates a Crush map for a setup consisting of six OSDs (i.e., individual storage devices in servers) distributed over three racks:
crushtool --num_osds 6 -o crush.example.map --build host straw 1 rack straw 2 root straw 0
The --num_osds 6 parameter specifies that the cluster has six individual storage devices at its disposal. The --build option introduces a statement with three three-part parameters that follow the <Name> <Internal Crush Algorithm> <Number> syntax.
<Name> can be chosen freely; however, it is wise to choose something meaningful. host straw 1 specifies that one replica is allowed per host, and rack straw 2 tells RADOS that two servers exist per rack. root straw 0 refers to the number of racks and determines that the replicas should be distributed equally on all available racks.
Subsequently, if you want to see the resulting Crush map in plain text, you can enter
crushtool -d crush.example.map -o crush.example
The file with the map in plain text will then be called crush.example (Listing 1).
Listing 1: Crush Map for Six Servers in Two Racks
001 # begin crush map
002
003 # devices
004 device 0 device0
005 device 1 device1
006 device 2 device2
007 device 3 device3
008 device 4 device4
009 device 5 device5
010
011 # types
012 type 0 device
013 type 1 host
014 type 2 rack
015 type 3 root
016
017 # buckets
018 host host0 {
019 id -1 # do not change unnecessarily
020 # weight 1.000
021 alg straw
022 hash 0 # rjenkins1
023 item device0 weight 1.000
024 }
025 host host1 {
026 id -2 # do not change unnecessarily
027 # weight 1.000
028 alg straw
029 hash 0 # rjenkins1
030 item device1 weight 1.000
031 }
032 host host2 {
033 id -3 # do not change unnecessarily
034 # weight 1.000
035 alg straw
036 hash 0 # rjenkins1
037 item device2 weight 1.000
038 }
039 host host3 {
040 id -4 # do not change unnecessarily
041 # weight 1.000
042 alg straw
043 hash 0 # rjenkins1
044 item device3 weight 1.000
045 }
046 host host4 {
047 id -5 # do not change unnecessarily
048 # weight 1.000
049 alg straw
050 hash 0 # rjenkins1
051 item device4 weight 1.000
052 }
053 host host5 {
054 id -6 # do not change unnecessarily
055 # weight 1.000
056 alg straw
057 hash 0 # rjenkins1
058 item device5 weight 1.000
059 }
060 rack rack0 {
061 id -7 # do not change unnecessarily
062 # weight 2.000
063 alg straw
064 hash 0 # rjenkins1
065 item host0 weight 1.000
066 item host1 weight 1.000
067 }
068 rack rack1 {
069 id -8 # do not change unnecessarily
070 # weight 2.000
071 alg straw
072 hash 0 # rjenkins1
073 item host2 weight 1.000
074 item host3 weight 1.000
075 }
076 rack rack2 {
077 id -9 # do not change unnecessarily
078 # weight 2.000
079 alg straw
080 hash 0 # rjenkins1
081 item host4 weight 1.000
082 item host5 weight 1.000
083 }
084 root root {
085 id -10 # do not change unnecessarily
086 # weight 6.000
087 alg straw
088 hash 0 # rjenkins1
089 item rack0 weight 2.000
090 item rack1 weight 2.000
091 item rack2 weight 2.000
092 }
093
094 # rules
095 rule data {
096 ruleset 1
097 type replicated
098 min_size 2
099 max_size 2
100 step take root
101 step chooseleaf firstn 0 type rack
102 step emit
103 }
104
105 # end crush mapOf course, the names of the devices and hosts (device0 , device2 , … and host1 , host2 , …) must be adapted to the local conditions. Thus, the name of the device should correspond to the device name in ceph.conf (in this example: osd.0 ), and the hostname should agree with the hostname of the server.
Distributing Replicas on the Racks
The replication is defined in line 101 of Listing 1 by step chooseleaf firstn 0 type rack , which determines that replicas are to be distributed on the racks. To achieve a distribution per host, rack would be replaced by host . The min_size and max_size parameters (lines 98 and 99) seem inconspicuous; however, especially in combination with ruleset 1 (line 96), they are very important for RADOS to use the rule created. Which ruleset from the Crush map RADOS will use is specified for each pool; for this, RADOS not only matches names, but also the min_size and max_size parameters, which refer to the number of replicas.
In concrete terms, this means: If RADOS is supposed to process a pool according to ruleset 1, which uses two replicas, then the rule in the example would apply. However, if the admin has used the command as explained above to specify that three replicas should exist for the objects in the pool, then RADOS would not apply the rule. To be less specific, it is recommended to set min_size to 1 and max_size to 10 – this rule would then apply for all pools that use ruleset 1 and require from one to 10 replicas.
On the basis of this example, admins will be able to create their own Crush maps, which must subsequently find their way back into RADOS.
Extending the Existing Crush Map
Practice has shown that it is useful to extend an existing Crush map with new entries instead of building a new one from scratch. The following command will give access to the Crush map currently in use:
ceph osd getcrushmap -o crush.running.map
This command will save the Crush map in binary format in crush.running.map . This file can be decoded with
crushtool -d crush.running.map -o crush.map
which transfers the plain text version to crush.map . After editing, the Crush map must be encoded again with
crushtool -c crush.map -o crush.new.map
before it can be sent back to the RADOS cluster with
ceph osd setcrushmap -i crush.new.map
Ideally, for a newly created pool to use the new rule, it would be set accordingly in ceph.conf ; the new rule would simply become the standard value. If the new ruleset from the example has the ID 4 in the Crush map (ruleset 4 ), then the line
osd pool default crush rule = 4
would help configuration block [osd] . Additionally,
osd pool default size = 3
can be used to determine that new pools should always be created with three replicas.
The 4K Limit for Ext3 and Ext4
If you complete a RADOS installation and use ext3 or ext4 as the filesystem, you might run into a snare: In these filesystems, the XATTR attributes (i.e., the extended file attributes) are limited to a maximum of 4KB, and the XATTR entries from RADOS regularly take up just that. If no preventive measures are taken, this setup could, in the worst case, cause ceph-osd to crash or spit out cryptic error messages like (Operation not supported ).
This problem can be remedied using an external file to save the XATTR entries. To do so, the line
filestore xattr use omap = true ; for ext3/4 filesystem
must be inserted into the [osd] entry in ceph.conf (Figure 3). In this way, you can protect the cluster against possible problems.
 Figure 3: Special care is needed when operating RADOS with ext3 or ext4.
Figure 3: Special care is needed when operating RADOS with ext3 or ext4.
Alternative: The RADOS Block Device
In the first part of this workshop [1], I took an in-depth look at the Ceph filesystem, which is a front end for RADOS. Ceph is not, however, the only way to access the data deposited in a RADOS store – the RADOS block driver (RBD) is an alternative. With rbd , objects in RADOS can be addressed as if they were on a hard disk.
This functionality is especially helpful in the context of virtualization because presenting a block device to KVM as a hard disk saves the virtualization a detour over container formats like qcow2. Additionally, using rbd is very easy – an rbd pool is already included that admins can take advantage of. For example, to create an rbd drive with a size of 1GB, you only need to use the command
rbd create test --size 1024
Subsequently, the block device can be used on any host with an rbd kernel module, which is now part of the mainline kernel and is found on practically every system. Because ceph.conf from the first part of this workshop has already specified that users must authenticate themselves to gain access to the RADOS services, that is also true for rbd . Note that login credentials can be called with:
ceph-authtool -l /etc/ceph/admin.keyring
Then, on a machine that has loaded rbd , you can type
echo "IP addresses of the MONs, separated by commas name=admin,secret=Authkeyrbd test" > /sys/bus/rbd/add
to activate the RBD drive.
Conclusions
RADOS lets administrators replace two-node storage with seamlessly scalable RADOS-based storage. Currently, the project developers plan to turn version 0.48 into version 1.0, which will then receive the official “Ready for Enterprise” stamp. Because the previous version 0.47 has already been released, the enterprise version may be expected soon. Next, I turn to security with CephX.
Info
[1] “RADOS and Ceph” by Martin Loschwitz, ADMIN, Issue 09, pg. 28
The Author
Martin Gerhard Loschwitz is Principal Consultant at hastexo, where he is intensively involved with high-availability solutions. In his spare time, he maintains the Linux cluster stack for Debian GNU/Linux.
Related content
-
The RADOS object store and Ceph filesystem: Part 2
 In the second part of this workshop on RADOS and Ceph, we cover the inner workings of RADOS and how to avoid pitfalls.
In the second part of this workshop on RADOS and Ceph, we cover the inner workings of RADOS and how to avoid pitfalls. -
The RADOS object store and Ceph filesystem
 Scalable storage is a key component in cloud environments. RADOS and Ceph enter the field, promising to support seamlessly scalable storage.
Scalable storage is a key component in cloud environments. RADOS and Ceph enter the field, promising to support seamlessly scalable storage. -
The RADOS Object Store and Ceph Filesystem

Scalable storage is a key component in cloud environments. RADOS and Ceph enter the field, promising to support seamlessly scalable storage.
-
Fixing Ceph performance problems
 Ceph is powerful and efficient, but wrong settings or faulty hardware can cause the decentralized object store to stumble.
Ceph is powerful and efficient, but wrong settings or faulty hardware can cause the decentralized object store to stumble. -
What's new in Ceph
 Ceph and its core component RADOS have recently undergone a number of technical and organizational changes. We take a closer look at the benefits that the move to containers, the new setup, and other feature improvements offer.
Ceph and its core component RADOS have recently undergone a number of technical and organizational changes. We take a closer look at the benefits that the move to containers, the new setup, and other feature improvements offer.