The RADOS Object Store and Ceph Filesystem
Cloud computing is, without a doubt, the IT topic of our time. No issue pushes infrastructure managers with large-scale enterprises as hard as how to best implement the cloud. The IaaS principle is quite simple: The goal is to provide capacity to users in the form of computational power and storage in a way that means as little work as possible for the user and that keeps the entire platform as flexible as possible.
Put more tangibly, this means customers can request CPU cycles and disk space as they see fit and continue to use both as the corresponding services are needed. For IT service providers, this means defining your own setup to be as scalable as possible: It should be possible to accommodate peak loads without difficulty, and if the platform grows – which will be the objective of practically any enterprise – a permanent extension should also be accomplished easily.
In practical terms, implementing this kind of solution will tend to be more complex. Scalable virtualization environments are something that is easy to achieve: Xen and KVM, in combination with the current crop of management tools, make it easy to manage virtualization hosts. Scale out also is no longer an issue: If the platform needs more computational performance, you can add more machines that integrate seamlessly with the existing infrastructure.
Things start to become more interesting when you look at storage. The way IT environments store data has remained virtually unchanged in the past few years. In the early 1990s, data centers comprised many servers with local storage, all of which suffered from legacy single points of failure. As of the mid-1990s, Fibre Channel HBAs and matching SAN storage entered the scene, offering far more redundancy than their predecessors, but at a far higher price. People who preferred a lower budget approach turned to DRBD with standard hardware a few years ago, thus avoiding what can be hugely expensive SANs. However, all of these approaches share a problem: They do not scale out seamlessly.
Scale Out and Scale Up
Admins and IT managers distinguish between two basic types of scalability. Vertical scalability (scale up) is based on the idea of extending the resources of existing devices, whereas horizontal scalability (scale out) relies on adding more resources to the existing set (Figure 1). Databases are a classic example of a scale-out solution: Typically, slave servers are added to support load distribution.
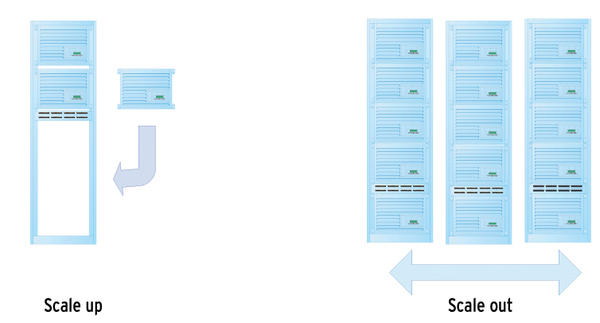 Figure 1: Two kinds of scalability.
Figure 1: Two kinds of scalability.
Scale out is completely new ground when it comes to storage. Local storage in servers, SAN storage, or servers with DRBD will typically only scale vertically (more disks!), not horizontally. When the case is full, you need a second storage device, and this will not typically support integration with the existing storage to provide a single unit, thus making maintenance far more difficult. In terms of SAN storage, two SANs just cost twice as much as one.
Object Stores
If you are planning a cloud and thinking about seamlessly scalable storage, don't become despondent at this point: Authors of the popular cloud applications are fully aware of this problem and now offer workable solutions known as object stores.
Object stores follow a simple principle: All servers that become part of an object store run software that manages and exports the server’s local disk space. All instances of this software collaborate on the cluster, thus providing the illusion of a single, large data store. To support internal storage management, the object store software does not save data in its original format on the individual storage nodes, but as binary objects. Most exciting is that the number of individual nodes joining forces to create the large object store is arbitrary. You can even add storage nodes on the fly.
Because the object storage software also has internal mechanisms to handle redundancy, and the whole thing works with standard hardware, a solution of this kind combines the benefits of SANs or DRBD storage and seamless horizontal scalability. RADOS has set out to be the king of the hill in this sector, in combination with the matching Ceph filesystem.
How RADOS Works
RADOS (reliable autonomic distributed object store, although many people mistakenly say “autonomous”) has been under development at DreamHost, led by Sage A. Weil, for a number of years and is basically the result of a doctoral thesis at the University of California, Santa Cruz. RADOS implements precisely the functionality of an object store as described earlier, distinguishing between three different layers to do so:
- Object Storage Devices (OSDs). An OSD in RADOS is always a folder within an existing filesystem. All OSDs together form the object store proper, and the binary objects that RADOS generates from the files to be stored reside in the store. The hierarchy within the OSDs is flat: files with UUID-style names but no subfolders.
- Monitoring servers (MONs): MONs form the interface to the RADOS store and support access to the objects within the store. They handle communication with all external applications and work in a decentralized way: There are no restrictions in terms of numbers, and any client can talk to any MON. MONs manage the MONmap (a list of all MONs) and the OSDmap (a list of all OSDs). The information from these two lists lets clients compute which OSD they need to contact to access a specific file. In the style of a Paxos cluster, MONs also ensure RADOS’s functionality in terms of respecting quorum rules.
- Metadata servers (MDS): MDSs provide POSIX metadata for objects in the RADOS object store for Ceph clients.
What About Ceph?
Most articles about RADOS just refer to Ceph in the title, causing some confusion. Weil described the relationship between RADOS and Ceph as two parts of the same solution: RADOS is the “lower” part and Ceph the “upper” part. One thing is for sure: The best looking object store in the world is useless if it doesn’t give you any options for accessing the data you store in it.
However, it is precisely these options that Ceph offers for RADOS: It is a filesystem that accesses the object store in the background and thus makes its data directly usable in the application. The metadata servers help accomplish this task by providing the metadata required for each file that Ceph accesses in line with the POSIX standard when a user requests a file via Ceph.
Because DreamHost didn’t consider until some later stage of development that RADOS could be used as a back end for tools other than filesystems, they generated confusion regarding the names of RADOS and Ceph. For example, the official DreamHost guides refer simply to “Ceph” when they actually mean “RADOS and Ceph.”
First RADOS Setup
Theory is one thing, but to gain some understanding of RADOS and Ceph, it makes much more sense to experiment on a “live object.” You don’t need much for a complete RADOS-Ceph setup: Three servers with local storage will do fine. Why three? Remember that RADOS autonomically provides a high-availability option. The MONs use the PAXOS implementation referred to earlier to guarantee that there will always be more than one copy of an object in a RADOS cluster. Although you could turn a single node into a RADOS store, this wouldn’t give you much in the line of high availability. A RADOS cluster comprising two nodes is even more critical: In a normal case, the cluster would have a quorum, but the failure of a single node would then make the other node useless because RADOS needs a quorum, and by definition, one can’t make a quorum. In other words, you need three nodes to be on the safe side, so the failure of single node won’t be an issue.
Incidentally, nothing can stop you from using virtual machines with RADOS for your experiments – RADOS doesn’t have any functions that require specific hardware features.
Finding the Software
Before experimenting, you need to install RADOS and Ceph. Ceph, which is a plain vanilla filesystem driver on Linux systems (e.g., ext3 or ext4), made its way into the Linux kernel in Linux 2.6.34 and is thus available for any distribution with this or a later kernel version (Figure 2). The situation isn’t quite as easy with RADOS; however, the documentation points to prebuilt packages, or at least gives you an installation guide, for all of the popular distributions. Note that although the documentation refers to “ceph,” the packages contain all of the components you need for RADOS. After installing the packages, it’s time to prepare RADOS.
 Figure 2: After loading the ceph kernel module, the filesystem is available on Linux. Ceph was first introduced in kernel 2.6.34.
Figure 2: After loading the ceph kernel module, the filesystem is available on Linux. Ceph was first introduced in kernel 2.6.34.
Preparing the OSDs
RADOS needs OSDs. As I mentioned earlier, any folder on a filesystem can act as an OSD; however, the filesystem must support extended attributes. The RADOS authors recommend Btrfs but also mention XFS as an alternative for anyone who is still a bit wary of using Btrfs. For simplicity’s sake, I will assume in the following examples that you have a directory named osd.ID in /srv on three servers, where ID stands for the server’s hostname in each case. If your three servers are named alice , bob , and charlie , you would have a folder named /srv/osd.alice on server alice , and so on.
If you will be using a local filesystem set up specially for this purpose, be sure to mount it in /srv/osd.ID . Finally, each of the hosts in /srv also needs a mon.ID folder, where ID again stands for the hostname.
In this sample setup, the central RADOS configuration in /etc/ceph/ceph.conf might look like Listing 1.
Listing 1: Sample /etc/ceph/ceph.conf
[global] auth supported = cephx keyring = /etc/ceph/$name.keyring [mon] mon data = /srv/mon.$id [mds] [osd] osd data = /srv/osd.$id osd journal = /srv/osd.$id.journal osd journal size = 1000 [mon.a] host = alice mon addr = 10.42.0.101:6789 [mon.b] host = bob mon addr = 10.42.0.102:6789 [mon.c] host = charlie mon addr = 10.42.0.103:6789 [osd.0] host = alice [osd.1] host = bob [osd.2] host = charlie [mds.a] host = alice
The configuration file defines the following details: each of the three hosts provides an OSD and a MON server; host alice is also running an MDS to ensure that any Ceph clients will find POSIX-compatible metadata on access. Authentication between the nodes is encrypted: The keyring for this is stored in the /etc/ceph folder and goes by the name of $name.keyring , where RADOS will automatically replace name with the actual value later.
Most importantly, the nodes in the RADOS cluster must reach one another directly using the hostnames from your ceph.conf file. This could mean adding these names to your /etc/hosts file. Additionally, you need to be able to log in to all of the RADOS nodes as root later on for the call to mkcephfs , and root needs to be able to call sudo without an additional password prompt on all of the nodes. After fulfilling these conditions, the next step is to create the keyring to support mutual authentication between the RADOS nodes:
mkcephfs -a -c /etc/ceph/ceph.conf -k /etc/ceph/admin.keyring
Now you need to ensure that ceph.conf exists on all the hosts belonging to the cluster (Figure 3). If this is the case, you just need to start RADOS on all of the nodes: Typing
/etc/init.d/ceph start
will do the trick. After a couple of seconds, the three nodes should have joined the cluster; you can check this by typing
ceph -k /etc/ceph/admin.keyring -c /etc/ceph/ceph.conf health
which should give you the output shown in Figure 4.
 Figure 3: To discover which Ceph services are running on a host, type ps. In this example, the host is an OSD, MON, and MDS.
Figure 3: To discover which Ceph services are running on a host, type ps. In this example, the host is an OSD, MON, and MDS.
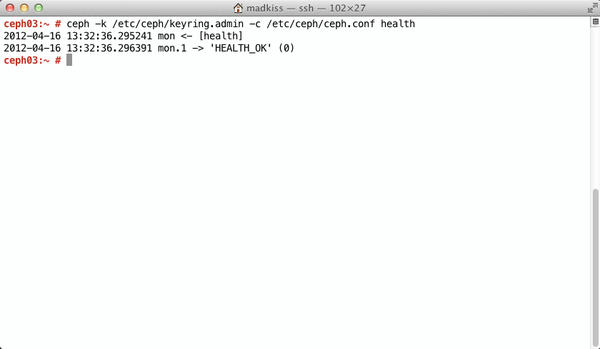 Figure 4: Ceph has its own health options that tell you whether the RADOS Paxos cluster is working properly.
Figure 4: Ceph has its own health options that tell you whether the RADOS Paxos cluster is working properly.
Using Ceph to Mount the Filesystem
To mount the newly created filesystem on another host on one of the RADOS nodes, you can use the normal mount command – the target host is one of the MON servers (i.e., alice in this example) with a MON address set to 10.42.0.101:6789 in ceph.conf . Because Cephx authentication is being used, I need to identify the login credentials automatically generated by Ceph before I can mount the filesystem. The following command on one of the RADOS nodes outputs the credentials:
ceph-authtool -l /etc/ceph/admin.keyring
The mount process then follows:
mount -t ceph 10.0.0.1:6789:/ /mnt/osd -vv -o name=admin,secret=mykey
where mykey needs to be replaced by the value for key that you determined with the last command. The mountpoint in this example is /mnt/osd , which can be used it as a normal directory from now on.
The Crush Map
RADOS and Ceph use a fair amount of magic in the background to safeguard the setup against any kind of failure, starting with the mount. Any of the existing MON servers can act as a mountpoint; however, this doesn’t mean communications are only channeled between the client and this one MON. Instead, Ceph on the client receives the MON and OSDmaps from the MON server it contacts and then references them to compute which OSD is best to use for a specific file before going on to handle the communication with this OSD.
The Crush map is another step for improving redundancy. It defines which hosts belong to a RADOS cluster, how many OSDs exist in the cluster, and how to distribute the files over these hosts for best effect. The Crush map makes RADOS rack-aware, allowing admins to manipulate the internal replication of RADOS in terms of individual servers, racks, or security zones in the data center. The setup shown for the example here also has a rudimentary default Crush map. If you want to experiment with your own Crush map, the Ceph wiki gives you the most important information for getting started.
Extending the Existing Setup
How do you go about extending an existing RADOS cluster, by adding more nodes to increase the amount of available storage? If you want to add a node named daisy to the existing setup, the first step would be to define an ID for this node. In this example, IDs 0 through 3 are already assigned, and the new node would have an ID of 4, so you need to type:
ceph osd create 4
Then you need to extend the ceph.conf files on the existing cluster nodes, adding an entry for daisy. On daisy, you also need to create the folder structure needed for daisy to act as an OSD (i.e., the directories in /srv , as in the previous examples). Next, copy the new ceph.conf to the /etc/ceph folder on daisy.
Daisy also needs to know the current MON structure – after all, she will need to register with an existing MON later on. This means daisy needs the current MONmap for the RADOS cluster. You can read the MONmap on one of the existing RADOS nodes by typing
ceph mon getmap -o /tmp/monmap
(Figure 5), and then use scp to copy it to daisy (this example assumes you are storing the MONmap in /tmp/monmap on daisy). Now, you need to initialize the OSD directory on daisy:
ceph-osd -c /etc/ceph/ceph.conf -i 4 --mkfs --monmap /tmp/monmap --mkkey
If the additional cluster node uses an ID other than 4 , you need to modify the numeric value that follows -i .
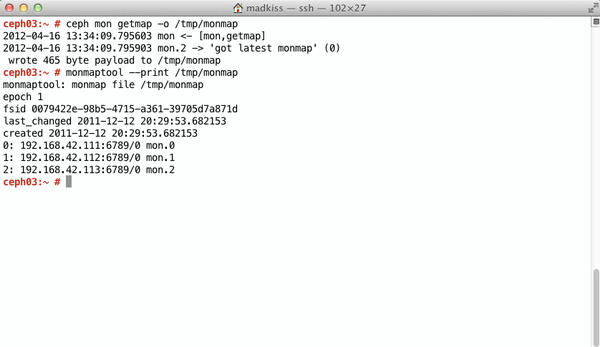 Figure 5: The MONmap contains information about MONs in the RADOS cluster. New OSDs rely on this information.
Figure 5: The MONmap contains information about MONs in the RADOS cluster. New OSDs rely on this information.
Finally, you need to introduce the existing cluster to daisy. In this example, the last command created a /etc/ceph/osd.4.keyring file on daisy, which you can copy to copy one of the existing MONs with scp . Following this,
ceph auth add osd.ID osd 'allow *' mon 'allow rwx' -i /etc/ceph/osd.4.keyring
on the same node adds the new OSD to the existing authentication structure (Figure 6). Typing /etc/init.d/ceph on daisy launches RADOS, and the new OSD registers with the existing RADOS cluster. The final step is to modify the existing Crush map so the new OSD is used. In this example, you would type
ceph osd crush add 4 osd.4 1.0 pool=default host=daisy
to do this. The new OSD is now part of the existing RADOS/Ceph cluster.
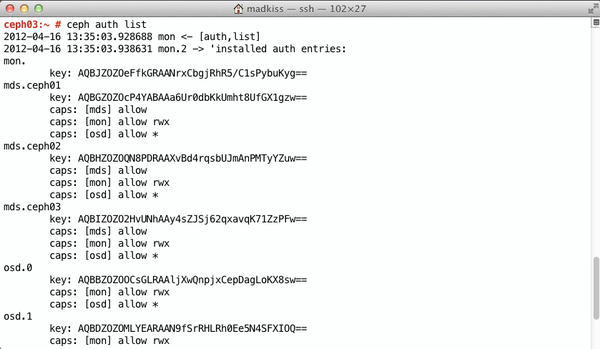 Figure 6: Typing “ceph auth list” tells Ceph to reveal the keys that a MON instance already knows and what the credentials allow the node to do.
Figure 6: Typing “ceph auth list” tells Ceph to reveal the keys that a MON instance already knows and what the credentials allow the node to do.
Conclusions
It isn’t difficult to set up the combination of RADOS and Ceph. But this simple configuration doesn’t leverage many of the exciting features that RADOS offers. For example, the Crush map functionality gives you the option of deploying huge RADOS setups over multiple racks in the data center while offering intelligent failsafes. Because RADOS also offers you the option of dividing its storage into individual pools of variable sizes, you can achieve more granularity in terms of different tasks and target groups.
Also, I haven’t looked at the RADOS front ends beyond Ceph. After all, Ceph is just one front end of many; in this case, it supports access to files in the object store via the Linux filesystem. However, more options for accessing the data on RADOS exist. The RADOS block device, or rbd for short, is a good choice when you need to support access to files in the object store at the block device level. For example, this would be the case for virtual machines that will typically accept block devices as a back end for virtual disks, thus avoiding slower solutions with disk images. In this way, you can exploit RADOS’s potential as an all-encompassing storage system for large virtualization solutions while solving another problem in the context of the cloud.
Speaking of the cloud, besides rbd , librados provides various interfaces for HTTP access – for example, a variant compatible with Amazon’s S3 and a Swift-compatible variant. A generic REST interface is also available. As you can see, RADOS has a good selection of interfaces to the world outside.
At the time of writing, the RADOS Ceph components were still pre-series, but the developers were looking to release version 1.0, which could already be available as officially stable and “enterprise-ready.” For more on RADOS and Ceph, see part 2 of this article.
Related content
-
RADOS and Ceph: Part 2

In this second article on scalable storage in cloud environments, we cover the inner workings of RADOS and how to avoid pitfalls.
-
Fixing Ceph performance problems
 Ceph is powerful and efficient, but wrong settings or faulty hardware can cause the decentralized object store to stumble.
Ceph is powerful and efficient, but wrong settings or faulty hardware can cause the decentralized object store to stumble. -
Troubleshooting and maintenance in Ceph
 We look into some everyday questions that administrators with Ceph clusters tend to ask: What do I do if a fire breaks out or I run out of space in the cluster?
We look into some everyday questions that administrators with Ceph clusters tend to ask: What do I do if a fire breaks out or I run out of space in the cluster? -
Ceph Maintenance

We look into some everyday questions that administrators with Ceph clusters tend to ask: What do I do if a fire breaks out or I run out of space in the cluster?
-
What's new in Ceph
 Ceph and its core component RADOS have recently undergone a number of technical and organizational changes. We take a closer look at the benefits that the move to containers, the new setup, and other feature improvements offer.
Ceph and its core component RADOS have recently undergone a number of technical and organizational changes. We take a closer look at the benefits that the move to containers, the new setup, and other feature improvements offer.