« Previous 1 2 3 Next »
Storage Spaces Direct with different storage media
Colorful Mix
Automated Configuration
When you use the Enable-ClusterStorageSpacesDirect cmdlet [2], PowerShell creates an automated configuration based on the hardware grouped in S2D. For example, the cmdlet creates the storage pool and the appropriate storage tiers when SSDs and traditional HDDs are added to the system. In such a configuration, the NVMe part is used for hot data storage, while SSDs and HDDs are available for storing less frequently used data (cold data).
To use S2D in production environments, you need network cards that support RDMA. In test environments, virtual servers, virtual hard disks, and virtual network cards can also be used without special hardware. Once the storage is set up, create one or more storage pools in the Failover Cluster Manager in the Storage | Pools area (Figure 2). These include the various volumes of the cluster nodes. The PowerShell syntax is shown in Listing 1.
Listing 1
Creating New Storage Pools
> New-StoragePool -StorageSubSystemName <FQDN of the Subsystems> -FriendlyName <StoragePoolName> -WriteCacheSizeDefault 0 -FaultDomain-AwarenessDefault StorageScaleUnit -ProvisioningTypeDefault Fixed -ResiliencySettingNameDefault Mirror -PhysicalDisk (Get-StorageSubSystem -Name <FQDN of the Subsystems> | Get-PhysicalDisk)
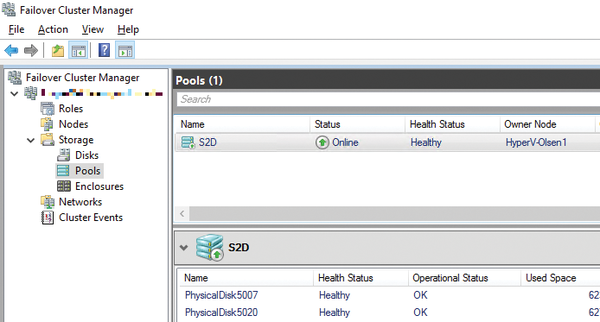 Figure 2: In the Failover Cluster Manager, the physical hard disks of the cluster nodes can be combined into a single Storage Spaces Direct.
Figure 2: In the Failover Cluster Manager, the physical hard disks of the cluster nodes can be combined into a single Storage Spaces Direct.
The cluster does not initially have a shared data store. Once you have created the cluster and activated S2D, the necessary storage pool is created and then the storage spaces are created. Next, you use the storage pool to create virtual hard disks, also known as "storage spaces." The cluster manages the underlying storage structure; therefore, file servers and Hyper-V hosts do not need to know on which physical disks the data is actually stored.
Distributing Data by Storage Tiers
You can also create your own storage tiers within S2D. Windows detects and automatically stores frequently used files in the SSD/NVMe area of the storage space. Less frequently used files are offloaded to slower hard disks. Of course, you can also control manually what kind of files should be available on the fast disks.
In Windows Server 2016, you can use three storage tiers: NVMe, SSD, and HDD. However, you can also create different combinations of these three volume types and define corresponding storage tiers. The commands for this are:
> New-StorageTier -StoragePoolFriendlyName Pool -FriendlyName SSD-Storage -MediaType SSD > New-StorageTier -StoragePoolFriendlyName Pool -FriendlyName HDD-Storage -MediaType HDD
As soon as the storage pool is available in the cluster, you can create new virtual hard disks – the storage spaces – using the context menu of the pools in the Failover Cluster Manager. The wizards also let you specify the availability and storage layout of the new storage space, which is based on the created storage pool. On the basis of the storage space, then, create a new volume, just as in a conventional storage pool. In turn, you can add volumes to the cluster through the context menu (e.g., to store your VM data).
Reliability of S2D
S2D is protected against host failure. Given the right number of cluster nodes, several can fail without affecting S2D. Entire enclosures or racks – or even entire data centers – can fail if the data can be replicated between a sufficient number of cluster nodes, and you can rely on storage replication under certain circumstances.
In Windows Server 2016, you can also use storage replication to replicate an entire S2D directly to other clusters and data centers. A TechNet blog post [3] explains how the fail-safe mechanism for S2D and the associated virtual hard disks work.
By default, high availability is enabled when creating a storage pool. The FaultDomainAwarenessDefault option and its StorageScaleUnit default value play an important role. I will return to the "fault domain" later. You can display the value for each storage pool at any time by typing:
> Get-StoragePool -FriendlyName <Pool-Name> | FL FriendlyName, Size, FaultDomainAwarenessDefault
Virtual disks (i.e., the storage spaces in the storage pool of the S2D environment) inherit high availability from the storage pool in which they are created (Figure 3). You can also view the high availability value of storage spaces with PowerShell:
> Get-VirtualDisk -FriendlyName <VirtualDiskName> | FL FriendlyName, Size, FaultDomainAwareness, ResiliencySettingName
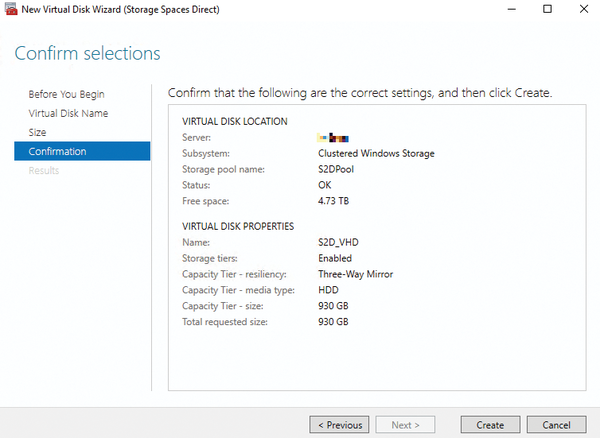 Figure 3: Virtual hard disks, also known as storage spaces, are created on the basis of the storage pool that extends across the cluster's various physical hard disks.
Figure 3: Virtual hard disks, also known as storage spaces, are created on the basis of the storage pool that extends across the cluster's various physical hard disks.
A virtual hard disk comprises extents of 1GB, so a hard disk with 100GB comprises 100 extents. If you create a virtual hard disk with the "mirrored" high availability setting, the individual extents of the virtual disk are copied and stored on different cluster nodes.
Depending on the number of nodes used, two or three copies of the extents can be distributed to the data stores of the various cluster nodes. If you back up a 100GB virtual disk by creating triple copies, the disk requires 300 extents. Windows Server 2016 tries to distribute the extents as evenly as possible. For example, if extent A is stored on nodes 1, 2, and 3, and extent B, on the same virtual hard disk, is copied to nodes 1, 3, and 4, then a virtual hard disk and its data and extents are distributed across all the nodes in the entire cluster.
Microsoft also offers the option of building an environment for S2D with just three hosts, which is of interest for small businesses or in test environments. With four hosts, the technology supports mirrored resiliency. If you want parity-based resiliency, four or more hosts are required. S2D is protected against host failure by default.
Windows Server 2016 works with "fault domains," which are groups of cluster nodes that share a single point of failure. A fault domain can be a single cluster node, cluster nodes in a common rack or housing, or all cluster nodes in a data center. You can manage the fault domains with the new Get, Set, New, and Remove cmdlets of the ClusterFaultDomain command. For example, to display information on existing fault domains, you can use:
> Get-ClusterFaultDomain > Get-ClusterFaultDomain -Type Rack > Get-ClusterFaultDomain -Name "server01.contoso.com"
You can also work with different types. For example, the following commands are available to create your own fault domains:
> New-ClusterFaultDomain -Type Chassis -Name "Chassis 007" > New-ClusterFaultDomain -Type Rack -Name "Rack A" > New-ClusterFaultDomain -Type Site -Name "Shanghai"
You can also link fault domains or subordinate fault domains to other fault domains:
> Set-ClusterFaultDomain -Name "server01.contoso.com" -Parent "Rack A" > Set-ClusterFaultDomain -Name "Rack A", "Rack B", "Rack C", "Rack D" -Parent "Shanghai"
In larger environments, you can also specify the fault domains in an XML file and then integrate them into the system. You can also use the new Get-ClusterFaultDomainXML cmdlet; for example, to save the current fault domain infrastructure in an XML file, enter:
> Get-ClusterFaultDomainXML | Out-File <Path>
You can also customize XML files and import them as a new infrastructure:
> $xml = Get-Content <Path> | Out-String Set-ClusterFaultDomainXML -XML $xml
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Storage pools and storage spaces in Windows
 Storage spaces and storage pools combine a variety of storage technologies into a single logical unit, ensuring high availability and a choice of resiliency capability.
Storage spaces and storage pools combine a variety of storage technologies into a single logical unit, ensuring high availability and a choice of resiliency capability. -
Storage cluster management with LINSTOR
 LINSTOR is a toolkit for automated cluster management that takes the complexity out of DRBD management and offers a wide range of functions, including provisioning and snapshots.
LINSTOR is a toolkit for automated cluster management that takes the complexity out of DRBD management and offers a wide range of functions, including provisioning and snapshots. -
Clusters with Windows Server 2012 R2
 With Windows, you can create a highly available cluster at the click of a button. The cluster will even handle fully automated, non-disruptive software upgrades.
With Windows, you can create a highly available cluster at the click of a button. The cluster will even handle fully automated, non-disruptive software upgrades. -
Manage Windows Server storage with PowerShell
 Numerous tools are available to manage the hard drive inventory of Windows servers, but they fall short when it comes to comprehensive automation, which is where PowerShell can help.
Numerous tools are available to manage the hard drive inventory of Windows servers, but they fall short when it comes to comprehensive automation, which is where PowerShell can help. -
Build storage pools with GlusterFS
 GlusterFS stores data across the network and can be used as a storage back end in cloud environments.
GlusterFS stores data across the network and can be used as a storage back end in cloud environments.