
Lead Image © jala, Fotolia.com
Build storage pools with GlusterFS
Diving In
Software-defined storage, which until recently was the preserve of large storage solution vendors, can be implemented today with open source and free software. As a bonus, you can look forward to additional features that are missing in hardware-based solutions. GlusterFS puts you in a position to create a scalable, virtualized storage pool made up of regular storage systems grouped to form a network RAID and with different methods of defining a volume to describe how the data is distributed across the individual storage systems.
Regardless of which volume type you choose, GlusterFS creates a common storage array from the individual storage resources and provides it to clients in a single namespace (Figure 1). The clients also can be applications, such as cloud software, that use the GlusterFS server storage back end for virtual systems. In contrast to other solutions of this kind, GlusterFS requires no dedicated metadata servers to find a file in the storage pool. Instead, a hash algorithm is used that allows any storage node to identify a file in the storage pool. This is a huge advantage over other storage solutions, because a metadata server is often a bottleneck and a single point of failure.
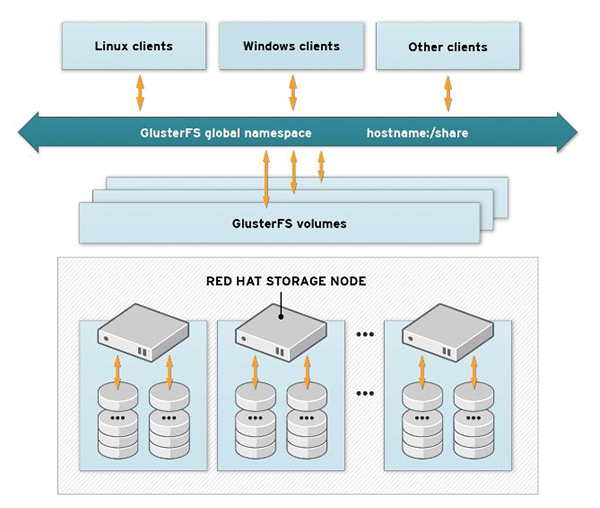 Figure 1: Client systems access the desired GlusterFS volume via a single namespace. (Red Hat CC BY-SA 3.0
Figure 1: Client systems access the desired GlusterFS volume via a single namespace. (Red Hat CC BY-SA 3.0Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
GlusterFS Storage Pools

GlusterFS stores data across the network and can be used as a storage back end in cloud environments.
-
GlusterFS

Sure, you could pay for cloud services, but with GlusterFS, you can take the idle space in your own data center and create a large data warehouse quickly and easily.
-
Comparing Ceph and GlusterFS
 Many shared storage solutions are currently vying for users’ favor; however, Ceph and GlusterFS generate the most press. We compare the two competitors and reveal the strengths and weaknesses of each solution.
Many shared storage solutions are currently vying for users’ favor; however, Ceph and GlusterFS generate the most press. We compare the two competitors and reveal the strengths and weaknesses of each solution. -
Red Hat Storage Server 2.1
 If you believe Red Hat's marketing hype, the company has no less than revolutionized data storage with version 2.1 of its Storage Server. The facts tell a rather different story.
If you believe Red Hat's marketing hype, the company has no less than revolutionized data storage with version 2.1 of its Storage Server. The facts tell a rather different story. -
Red Hat Storage Server 2.1

If you believe Red Hat’s marketing hype, the company has no less than revolutionized data storage with version 2.1 of its Storage Server. The facts tell a rather different story.