
Lead Image © lassedesignen, 123RF
Building a virtual NVMe drive
Pretender
Often, older or slower hardware remains in place while the rest of the environment or world updates to the latest and greatest technologies; take, for example, Non-Volatile Memory Express (NVMe) solid state drives (SSDs) instead of spinning magnetic hard disk drives (HDDs). Even though NVMe drives deliver the performance desired, the capacities (and prices) are not comparable to those of traditional HDDs, so, what to do? Create a hybrid NVMe SSD and export it across an NVMe over Fabrics (NVMeoF) network to one or more hosts that use the drive as if it were a locally attached NVMe device (Figure 1).
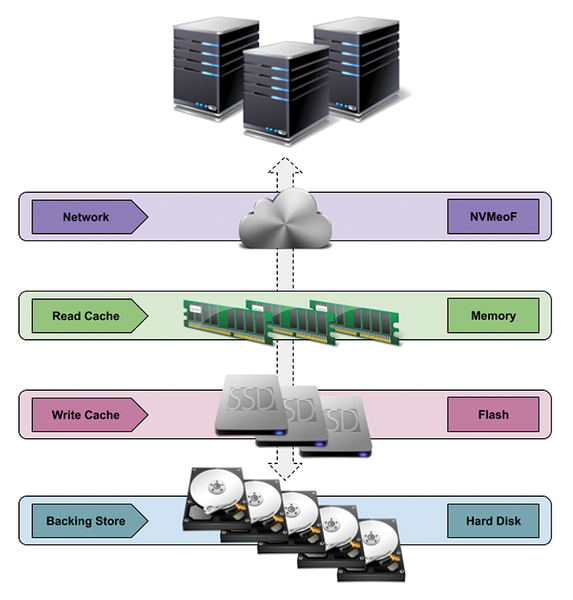 Figure 1: Virtual NVMe drive configuration.
Figure 1: Virtual NVMe drive configuration.
The implementation will leverage a large pool of HDDs at your disposal – or, at least, what is connected to your server – and place them into a fault-tolerant MD RAID implementation, making a single large-capacity volume. Also, within MD RAID, a small-capacity and locally attached NVMe drive will act as a write-back cache for the RAID volume. The use of RapidDisk modules [1] to set up local RAM as a small read cache, although not necessary, can sometimes help with repeatable random reads. This entire hybrid block device will then be exported across your standard network, where a host will be able to attach to it and access it as if it were a locally attached
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Creating Virtual SSDs

An economical and high-performing hybrid NVMe SSD is exported to host servers that use it as a locally attached NVMe device.
-
Unleashing Accelerated Speeds with RAM Drives
 Enable and share performant block devices across a network of compute nodes with the RapidDisk kernel RAM drive module.
Enable and share performant block devices across a network of compute nodes with the RapidDisk kernel RAM drive module. -
Rethinking RAID (on Linux)

Configure redundant storage arrays to boost overall data access throughput while maintaining fault tolerance.
-
Tuning ZFS for Speed on Linux
 The ZFS filesystem and volume manager simplifies data storage management and offers advanced features that allow it to perform in mission-critical or high-performance environments.
The ZFS filesystem and volume manager simplifies data storage management and offers advanced features that allow it to perform in mission-critical or high-performance environments. -
Rethinking RAID (on Linux)
 Configure redundant storage arrays to boost overall data access throughput while maintaining fault tolerance.
Configure redundant storage arrays to boost overall data access throughput while maintaining fault tolerance.