Building a Virtual NVMe Drive
Often, older or slower hardware remains in place while the rest of the environment or world updates to the latest and greatest technologies; take, for example, Non-Volatile Memory Express (NVMe) solid state drives (SSDs) instead of spinning magnetic hard disk drives (HDDs). Even though NVMe drives deliver the performance desired, the capacities (and prices) are not comparable to those of traditional HDDs, so, what to do? Create a hybrid NVMe SSD and export it across an NVMe over Fabrics (NVMeoF) network to one or more hosts that use the drive as if it were a locally attached NVMe device (Figure 1).
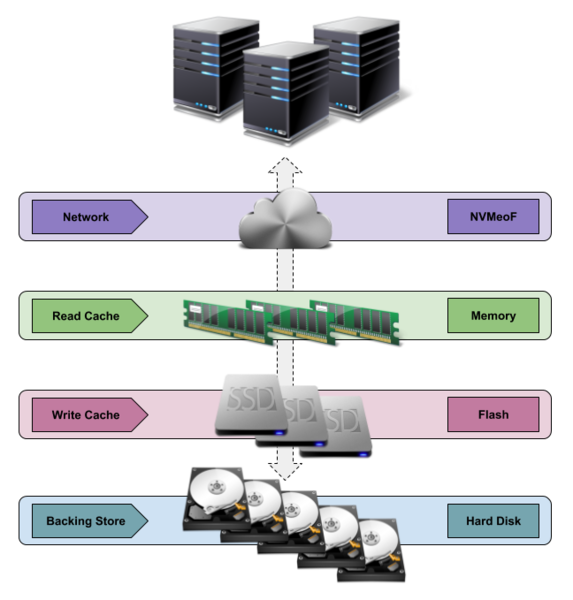 Figure 1: Virtual NVMe drive configuration.
Figure 1: Virtual NVMe drive configuration.
The implementation will leverage a large pool of HDDs at your disposal – or, at least, what is connected to your server – and place them into a fault-tolerant MD RAID implementation, making a single large-capacity volume. Also, within MD RAID, a small-capacity and locally attached NVMe drive will act as a write-back cache for the RAID volume. The use of RapidDisk modules to set up local RAM as a small read cache, although not necessary, can sometimes help with repeatable random reads. This entire hybrid block device will then be exported across your standard network, where a host will be able to attach to it and access it as if it were a locally attached volume.
The advantage of having this write-back cache is that all the write requests will land on the faster storage medium and not need to wait until it persists to the slower RAID volume before returning back to the application, which will dramatically improve write performance.
Before continuing, though, you need to understand a couple of concepts: (1) As it relates to the current environment, an initiator or host will be the server connecting to a remote block device – specifically, an NVMe target. (2) The target will be the server exporting the NVMe device across the network and to the host server.
A Linux 5.0 or later kernel is required on both the target and initiator servers. The host needs the NVMe TCP module and the target needs the NVMe target TCP module built and installed:
CONFIG_NVME_TCP=m CONFIG_NVME_TARGET_TCP=m
Now, a pile of disk drives at your disposal can be configured into a fault-tolerant RAID configuration and collectively give you the capacity of a single large drive.
Configuring the Target Server
To begin, list the drives of your local server machine (Listing 1). In this example, the four drives sdb to sde in lines 12, 13, 15, and 16 will be used to create the NVMe target. Each drive is 7TB, which you can verify with the blockdev utility:
$ sudo blockdev --getsize64 /dev/sdb 7000259821568
Listing 1: Server Drives
01 $ cat /proc/partitions 02 major minor #blocks name 03 04 7 0 91228 loop0 05 7 1 56008 loop1 06 7 2 56184 loop2 07 7 3 91264 loop3 08 259 0 244198584 nvme0n1 09 8 0 488386584 sda 10 8 1 1024 sda1 11 8 2 488383488 sda2 12 8 16 6836191232 sdb 13 8 64 6836191232 sde 14 8 80 39078144 sdf 15 8 48 6836191232 sdd 16 8 32 6836191232 sdc 17 11 0 1048575 sr0
With the parted utility, you can create a single partition on each entire HDD:
$ for i in sdb sdc sdd sde; do sudo parted --script /dev/$i mklabel gpt mkpart primary 1MB 100%; done
An updated list of drives will display the newly created partitions just below each disk drive (Listing 2). The newly created partitions now have 1s attached to the drive names (lines 13, 15, 18, 20). The drive size has not changed much from the original:
$ sudo blockdev --getsize64 /dev/sdb1 7000257724416
Listing 2: New Partitions
01 $ cat /proc/partitions 02 major minor #blocks name 03 04 7 0 91228 loop0 05 7 1 56008 loop1 06 7 2 56184 loop2 07 7 3 91264 loop3 08 259 0 244198584 nvme0n1 09 8 0 488386584 sda 10 8 1 1024 sda1 11 8 2 488383488 sda2 12 8 16 6836191232 sdb 13 8 17 6836189184 sdb1 14 8 64 6836191232 sde 15 8 65 6836189184 sde1 16 8 80 39078144 sdf 17 8 48 6836191232 sdd 18 8 49 6836189184 sdd1 19 8 32 6836191232 sdc 20 8 33 6836189184 sdc1 21 11 0 1048575 sr0
If you paid close attention, you'll see an NVMe device resides among the list of drives, which will be the device you will use for the write-back cache of your RAID pool. It is not a very large volume (about 256GB):
sudo blockdev --getsize64 /dev/nvme0n1 250059350016
Next, create a single partition on the NVMe drive and verify that the partition has been created:
$ sudo parted --script /dev/nvme0n1 mklabel gpt mkpart primary 1MB 100% $ cat /proc/partitions | grep nvme 259 0 244198584 nvme0n1 259 2 244197376 nvme0n1p1
The next step is to create a RAID 5 volume to encompass all of the HDDs (see also the "RAID 5" box). This configuration will use one drive’s worth of capacity to hold the parity data for both fault tolerance and data redundancy. In the event of a single drive failure, then, you can continue to serve data requests while also having the capability to restore the original data to a replacement drive.
RAID 5
A RAID 5 array stripes chunks of data across all the drives in a volume, with parity calculated by an XOR algorithm. Each stripe holds the parity to the data within its stripe; therefore, the parity data does not sit on a single drive within the array but, rather, is distributed across all of the volumes.
 Figure 2: The data and parity layout of a typical RAID 5 volume.
Figure 2: The data and parity layout of a typical RAID 5 volume.
If you were to do the math, you have four 7TB drives with one drive’s worth of capacity hosting the parity, so the RAID array will produce (7 × 4) - 7 = 21TB of shareable capacity.
Again, the RAID configuration uses the NVMe device partitioned earlier as a write-back cache and write journal. Note that this NVMe device does not add to the RAID array’s overall capacity.
To create the RAID 5 array, use the mdadm utility:
$ sudo mdadm --create /dev/md0 --level=5 --raid-devices=4 --write-journal=/dev/nvme0n1p1 --bitmap=none /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.
Next, verify that the RAID configuration has been created (Listing 3). You will immediately notice that the array initializes the disks and zeros out the data on each to bring it all to a good state. Although you can definitely use it in this state, overall performance will be affected.
Listing 3: Verify RAID
$ cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid5 sdd1[5] sde1[4] sdc1[2] sdb1[1] nvme0n1p1[0](J) 20508171264 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [UU_U] [>....................] recovery = 0.0% (5811228/6836057088) finish=626.8min speed=181600K/sec
Also, you probably do not want to disable the initial resync of the array with the --assume-clean option, even if the drives are right out of the box. Better you should know your array is in a proper state before writing important data to it. This operation will definitely take a while, and the bigger the array, the longer the initialization process. You can always take that time to read through the rest of this article or just go get a cup of coffee or two or five. No joke, this process takes quite a while to complete.
When the initialization process has been completed, a reread of the same /proc/mdstat file will yield the following (or similar), as shown in Listing 4.
Listing 4: Reread RAID
$ cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid5 sde1[4] sdd1[3] sdc1[2] sdb1[1] nvme0n1p1[0](J) 20508171264 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU] unused devices: <none>
The newly created block device will be appended to a list of all usable block devices:
$ cat /proc/partitions | grep md 9 0 20508171264 md0
If you recall, the usable capacity was originally calculated at 21TB. To verify this, enter:
$ sudo blockdev --getsize64 /dev/md0 21000367374336
Once the array initialization has completed, change the write journal mode from write-through to write-back and verify the change:
$ echo "write-back" | sudo tee /sys/block/md0/md/journal_mode > /dev/null $ cat /sys/block/md0/md/journal_mode write-through [write-back]
Now it is time to add the read cache. As a prerequisite, you need to ensure that the Jansson development library is installed on your local machine. Clone the rapiddisk Git repository, build and install the package, and insert the kernel modules:
$ git clone https://github.com/pkoutoupis/rapiddisk.git $ cd rapiddisk/ $ make $ sudo make install $ sudo modprobe rapiddisk $ sudo modprobe rapiddisk-cache
Determine the amount of memory you are able to allocate for your read cache, which should be based on the total memory installed on the system. For instance, if you have 64GB, you might be willing to use 8 or 16GB. In my case, I do not have much memory in my system, which is why I only create a single 2GB RAM drive for the read cache:
$ sudo rapiddisk --attach 2048 rapiddisk 6.0 Copyright 2011 - 2019 Petros Koutoupis Attached device rd0 of size 2048 Mbytes
Next, create a mapping of the RAM drive to the RAID volume:
$ sudo rapiddisk --cache-map rd0 /dev/md0 wa rapiddisk 6.0 Copyright 2011 - 2019 Petros Koutoupis Command to map rc-wa_md0 with rd0 and /dev/md0 has been sent. Verify with "--list"
The wa argument appended to the end of the command stands for write-around. In this configuration the read operations, not the write operations, are cached. Remember, the writes are being cached under the reads and onto the NVMe drive attached to the RAID volume. Because the writes are preserved on a persistent flash volume, you have some assurance that if the server were to experience power or operating system failure, the pending write transactions would not be lost as a result of the outage. Once services are restored, it will continue to operate as if nothing had happened.
Now, verify the mapping (Listing 5). The volume will be accessible at /dev/mapper/rc-wa_md0 :
$ ls -l /dev/mapper/rc-wa_md0 brw------- 1 root root 253, 0 Jan 16 23:15 /dev/mapper/rc-wa_md0
Listing 5: Verify Mapping
$ sudo rapiddisk --list rapiddisk 6.0 Copyright 2011 - 2019 Petros Koutoupis List of RapidDisk device(s): RapidDisk Device 1: rd0 Size (KB): 2097152 List of RapidDisk-Cache mapping(s): RapidDisk-Cache Target 1: rc-wa_md0 Cache: rd0 Target: md0 (WRITE AROUND)
Your virtual NVMe is nearly completed; you just need to add the component that turns the hybrid SSD volume into an NVMe-identified volume. To insert the NVMe target and NVMe target TCP modules, enter:
$ sudo modprobe nvmet $ sudo modprobe nvmet-tcp
The NVMe target tree will need to be made available over the kernel user configuration filesystem to provide access to the entire NVMe target configuration environment. To begin, mount the kernel user configuration filesystem and verify that it has been mounted:
$ sudo /bin/mount -t configfs none /sys/kernel/config/ $ mount | grep configfs configfs on /sys/kernel/config type configfs (rw,relatime)
Next, create an NVMe target test directory under the target subsystem and change into that directory (this will host the NVMe target volume plus its attributes):
$ sudo mkdir /sys/kernel/config/nvmet/subsystems/nvmet-test $ cd /sys/kernel/config/nvmet/subsystems/nvmet-test
Because this is a test environment, you do not necessarily care which initiators (i.e., hosts) connect to the exported target:
$ echo 1 | sudo tee -a attr_allow_any_host > /dev/null
Now, create a namespace and change into the directory:
$ sudo mkdir namespaces/1 $ cd namespaces/1/
To set the hybrid SSD volume as the NVMe target device and enable the namespace, enter:
$ echo -n /dev/mapper/rc-wa_md0 | sudo tee -a device_path > /dev/null $ echo 1 | sudo tee -a enable > /dev/null
Now that you have defined your target block device, you need to switch focus and define your target (i.e., networking) port: Create a port directory in the NVMe target tree and change into the directory:
$ sudo mkdir /sys/kernel/config/nvmet/ports/1 $ cd /sys/kernel/config/nvmet/ports/1
Now, set the local IP address from which the export will be visible, the transport type, port number, and protocol version:
$ echo 10.0.0.185 | sudo tee -a addr_traddr > /dev/null $ echo tcp | sudo tee -a addr_trtype > /dev/null $ echo 4420 | sudo tee -a addr_trsvcid > /dev/null $ echo ipv4 | sudo tee -a addr_adrfam > /dev/null
For any of this to work, both the target and initiator will need to have port 4420 open in its I/O firewall rules.
To tell the NVMe target tree that the port just created will export the block device defined in the subsystem section above, link the target subsystem to the target port and verify the export:
$ sudo ln -s /sys/kernel/config/nvmet/subsystems/nvmet-test/ /sys/kernel/config/nvmet/ports/1/subsystems/nvmet-test $ dmesg | grep "nvmet_tcp" [ 9360.176859] nvmet_tcp: enabling port 1 (10.0.0.185:4420)
Alternatively, you can do most of that above for the NVMe target configuration with the nvmetcli utility, which provides a more interactive shell that allows you to traverse the same tree, but within a single, perhaps more easy to follow, environment.
Configuring the Initiator Server
For the secondary server (i.e., the server that will connect to the exported target and use the virtual NVMe drive as if it were attached locally), load the initiator or host-side kernel modules:
$ modprobe nvme $ modprobe nvme-tcp
Again, remember that for this to work, both the target and initiator need port 4420 open in its I/O firewall rules.
To discover the NVMe target exported by the target server, use the nvme command-line utility (Listing 6); then, connect to the target server and import the NVMe device(s) it is exporting (in this case, you should see just the one):
$ sudo nvme connect -t tcp -n nvmet-test -a 10.0.0.185 -s 4420
Next, verify that the NVMe subsystem sees the NVMe target (Listing 7) and that the volume is listed in your local device listing (also, notice the volume size of 21TB):
$ cat /proc/partitions | grep nvme 259 0 20508171264 nvme0n1
Listing 6: Discover NVMe Target
$ sudo nvme discover -t tcp -a 10.0.0.185 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: tcp adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: nvmet-test traddr: 10.0.0.185 sectype: none
Listing 7: Verify NVMe Target Is Visible
$ sudo nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 152e778212a62015 Linux 1 21.00 TB / 21.00 TB 4 KiB + 0 B 5.4.12-0
You are now able to read and write from and to /dev/nvme0n1 as if it were a locally attached NVMe device. Finally, enter
$ sudo nvme disconnect -d /dev/nvme0n1
to disconnect the NVMe target volume.
Conclusion
The virtual NVMe drive you built will perform very well on write operations with a local NVMe SSD and "okay-ish" on non-repeated random read operations with local DRAM memory as a front end to a much larger (and slower) storage pool of HDDs. This configuration was in turn exported as a target across an NVMeoF network over TCP and to an initiator, where it is seen as a local NVMe-connected device.
The Author
Petros Koutoupis is currently a senior performance software engineer at Cray for its Lustre High Performance File System division. He is also the creator and maintainer of the RapidDisk Project (www.rapiddisk.org). Petros has worked in the data storage industry for well over a decade and has helped to pioneer the many technologies unleashed in the wild today.
Related content
-
Building a virtual NVMe drive
 An economical and high-performing hybrid NVMe SSD is exported to host servers that use it as a locally attached NVMe device.
An economical and high-performing hybrid NVMe SSD is exported to host servers that use it as a locally attached NVMe device. -
Unleashing Accelerated Speeds with RAM Drives
 Enable and share performant block devices across a network of compute nodes with the RapidDisk kernel RAM drive module.
Enable and share performant block devices across a network of compute nodes with the RapidDisk kernel RAM drive module. -
Rethinking RAID (on Linux)

Configure redundant storage arrays to boost overall data access throughput while maintaining fault tolerance.
-
Tuning ZFS for Speed on Linux
 The ZFS filesystem and volume manager simplifies data storage management and offers advanced features that allow it to perform in mission-critical or high-performance environments.
The ZFS filesystem and volume manager simplifies data storage management and offers advanced features that allow it to perform in mission-critical or high-performance environments. -
Rethinking RAID (on Linux)
 Configure redundant storage arrays to boost overall data access throughput while maintaining fault tolerance.
Configure redundant storage arrays to boost overall data access throughput while maintaining fault tolerance.