
Lead Image © Golkin Oleg, 123RF.com
PostgreSQL Replication Update
Data Duplication
If you have anything to do professionally with the topic of replication as a PostgreSQL consultant [1], you might easily gain the impression that colleagues and clients see only distributed, synchronous, multimaster replication as true replication. But are they right?
Synchronous vs. Asynchronous
Generally speaking, replication can be classified in different ways (e.g., synchronous or asynchronous) (Figure 1). In the case of synchronous replication, a transaction is not completed until it is acknowledged by the service. The advantage, particularly in the case of a crash, is that the data must have arrived on at least two systems. The drawback is that the data must be written to at least two systems. The advantage is therefore a disadvantage because the double write operations cost time.
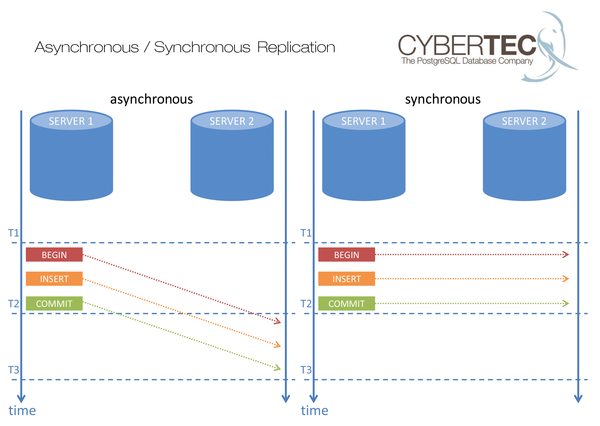 Figure 1: In the case of asynchronous replication, a time offset occurs when executing the transactions.
Figure 1: In the case of asynchronous replication, a time offset occurs when executing the transactions.
Single- and Multimaster
The distinction between single-master and multimaster is important. Many users choose multimaster because they can use it to distribute the read load, although it does not make writing faster because both
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
What's new in PostgreSQL 9.4
 The PostgreSQL Global Development Group recently introduced the new major version 9.4 of the popular free database, which includes innovative functions as well as a whole range of changes regarding speed and functionality.
The PostgreSQL Global Development Group recently introduced the new major version 9.4 of the popular free database, which includes innovative functions as well as a whole range of changes regarding speed and functionality. -
MySQL is gearing up with its own high-availability Group Replication solution
 Oracle recently introduced Group Replication as a trouble-free high-availability solution for the ubiquitous MySQL.
Oracle recently introduced Group Replication as a trouble-free high-availability solution for the ubiquitous MySQL. -
New in PostgreSQL 9.3
 The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance.
The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance. -
PostgreSQL 9.3
The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance.
-
Scale-out with PostgreSQL
 The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL.
The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.


