« Previous 1 2 3 Next »
Sustainable Kubernetes with Project Kepler
Power Play
Scraping Power Metrics
The next step is to instrument the node and the cluster to scrape power metrics from the node's mains power supply. Devices for measuring the current drawn from a wall socket have been around for a long time and are commonly found in the form of multimeters with clamp probes that place a coil around the power cable and measure the current induced in the coil.
Smart uninterruptible power supply (UPS) and power distribution unit (PDU) devices, typically found in data centers, can also report on the power consumed by each connected device, although they might not expose the power data in a sufficiently raw format to make them usable for this experiment. Luckily, the trend for home automation means that WiFi-enabled smart switches containing accurate power consumption sensors are available for less than $10 each and are easily reprogrammable to run open source home automation software such as ESPHome.
To compare Kepler's metrics against real power consumption, I have powered my Kubernetes hosts with Sonoff S31 smart switches flashed with ESPHome firmware, with power measurements exported to the Kubernetes cluster's Prometheus database by json-exporter. Being able to chart each node's real mains power consumption within the cluster's own Prometheus stack is certainly insightful, and might even be a useful application in some on-premises production environments. My wiki page [4] gives details on how I implemented this setup. Figure 2 shows my bare metal host powered by the Sonoff switch, with the switch's ESPHome web UI visible on the left-hand side of the photo.
 Figure 2: Bare metal Kubernetes host powered by Sonoff switch with power readings scraped into Prometheus.
Figure 2: Bare metal Kubernetes host powered by Sonoff switch with power readings scraped into Prometheus.
Benchmarking the Workload
To compare power consumption reporting reliably, you'll need a standardized and reproducible compute workload, which places a big enough load on its host CPU to make it obvious whenever it is run. For this, I created a text file of 50,000 random numbers between 1 and 100 and a suitably inefficient bubble sort program packaged into a container designed to sort the text file and then politely exit when done. It will note the times when the workload pod starts and completes and compare the host's average power consumption during the time the workload is running compared with its average power consumption in the idle state.
Figure 3 shows the power metrics from the smart switch covering the period in which the test workload ran. The start of the sudden increase, just after 18:31hr, is when the workload job was created on the Kubernetes cluster. Fitting the "average" lines by eye, the host's power consumption goes up from an average of 19W when idle to 37W when the workload is running. Therefore, the workload was responsible for approximately 18W of power consumption over the course of seven minutes. That's 2.1Wh or 7,560 joules of energy. According to the latest data published by the US Environmental Protection Agency, the average carbon footprint of a domestic kilowatt-hour is 0.389kg of CO2, so this workload's carbon footprint was 0.82g of CO2. Tiny, but not zero!
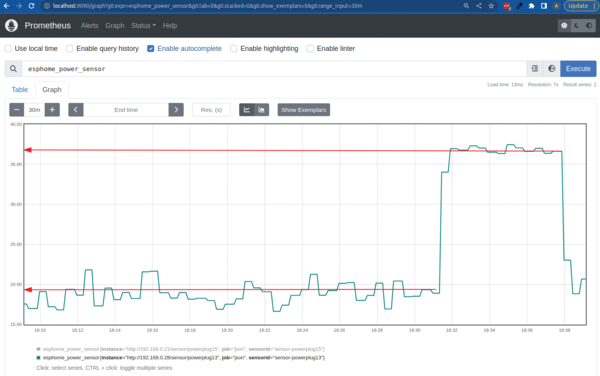 Figure 3: The bare metal host's extra power consumption caused by the test workload is easily seen by the metrics from the ESPHome smart switch.
Figure 3: The bare metal host's extra power consumption caused by the test workload is easily seen by the metrics from the ESPHome smart switch.
The host is a 10-year-old Core i7 model with eight cores, Haswell architecture, and a fan that goes instantly into screaming overdrive as soon as I start the bubble sort workload. Repeating the same test on a smaller and more modern host – a Core i7 Chromebox with Skylake architecture – gives the results shown in Figure 4, which is an approximately 12.5W power increase over a six-minute period, or 0.49g of CO2. This setup at least shows that you get more computing power per kilowatt-hour with a more modern host.
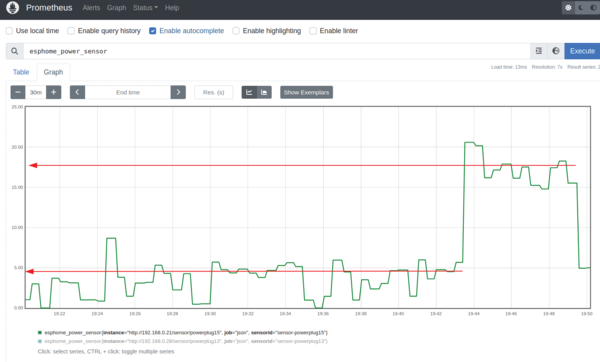 Figure 4: The power monitoring setup shows that the same workload on a more modern Intel architecture completes faster with a smaller power draw and, hence, a lower carbon footprint.
Figure 4: The power monitoring setup shows that the same workload on a more modern Intel architecture completes faster with a smaller power draw and, hence, a lower carbon footprint.
Kepler Core Concepts
The smart switches showed the carbon footprint of a single workload running in a tightly controlled environment. To find the carbon footprint of an arbitrary pod in a multiuser production cluster, you need a more sophisticated approach, because you won't be able to correlate mains power measurements with workload timings as in the last experiment.
Project Kepler (Kubernetes Efficient Power Level Exporter) is a CNCF Sandbox project started by Red Hat that aims to solve this problem. The Kepler eBPF program probes kernel tracepoints and performance counters to obtain counts of CPU instructions and DRAM operations within a given measurement period, allocated by process ID. It combines this information with cgroup and Kubelet information to see which processes are owned by which pod (Figure 5).
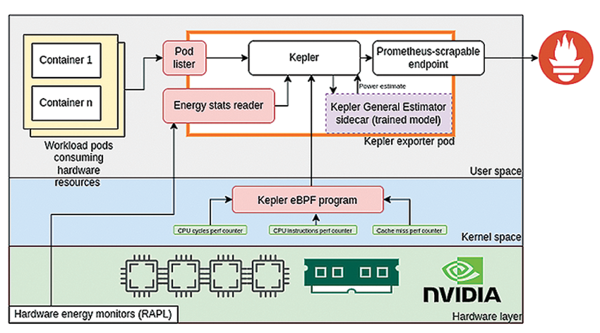 Figure 5: Kepler uses eBPF to extract performance counter data and combines it with information from hardware power interfaces and Kubelet/cgroups to predict each pod's power consumption with an ML model.
Figure 5: Kepler uses eBPF to extract performance counter data and combines it with information from hardware power interfaces and Kubelet/cgroups to predict each pod's power consumption with an ML model.
Kepler then takes hardware-level power consumption information from RAPL and ACPI (and NVIDIA management library (NVML) for hosts equipped with NVIDIA GPUs) and feeds it all into a trained ML model that estimates the "power ratio" of each pod. Knowing the instantaneous total power consumption of each hardware component, Kepler predicts each pod's share of that total power consumption, reporting its results in the form of Prometheus-compatible metrics.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Monitoring container clusters with Prometheus
 In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation.
In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation. -
Time-series-based monitoring with Prometheus
 As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications.
As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications. -
Detect anomalies in metrics data
 Anomalies in an environment's metrics data are an important indicator of an attack. The Prometheus time series database automatically detects, alerts, and forecasts anomalous behavior with the Fourier and Prophet models of the Prometheus Anomaly Detector.
Anomalies in an environment's metrics data are an important indicator of an attack. The Prometheus time series database automatically detects, alerts, and forecasts anomalous behavior with the Fourier and Prophet models of the Prometheus Anomaly Detector. -
Central logging for Kubernetes users
 Grafana's Loki is a good replacement candidate for the Elasticsearch, Logstash, and Kibana combination in Kubernetes environments.
Grafana's Loki is a good replacement candidate for the Elasticsearch, Logstash, and Kibana combination in Kubernetes environments. - NVidia Announces New Kepler-Based GPUs
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
