« Previous 1 2 3 Next »
Detect failures and ensure high availability
On the Safe Side
Corosync and Pacemaker
Corosync has become the standard bearer of everything cluster-related in Linux. Almost all modern Linux distributions support the framework, which also is available in their respective package repositories. Corosync is a cluster engine, and more technically, it's a communication system or messaging layer. Corosync's purpose is to monitor both cluster state and quorum.
Pacemaker is a cluster resource manager. When you enable a particular resource agent catering to a specific set of tasks or applications, Pacemaker ensures that it's running on the node on which it's designated to run. If that node fails, Pacemaker redirects that resource over to another node within the same cluster.
DRBD
DRBD (distributed replicated block device) [1] is implemented as both a kernel module and userspace management applications. It's developed by LINBIT, and as the name implies, the sole purpose of this framework is to replicate block devices across multiple distributed machines configured in a cluster. This method of replication is similar, but not identical, to that of a RAID 1 mirror (Figure 2). DRBD is typically configured for a high-availability environment, wherein one server acts as the primary server, making its underlying DRBD block device available to a specific set of services or applications, while all its updates are distributed across the cluster. The volumes on the remaining servers are always kept consistent with the primary server.
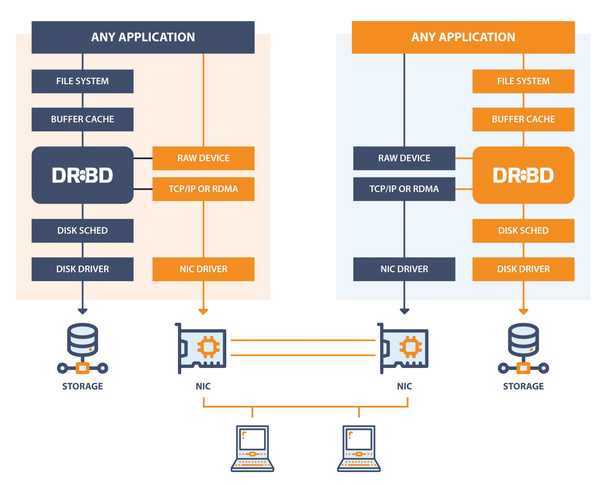 Figure 2: A high-level layout of the DRBD architecture and design showing where DRBD sits in the Linux kernel storage stack. © Courtesy of LINBIT
Figure 2: A high-level layout of the DRBD architecture and design showing where DRBD sits in the Linux kernel storage stack. © Courtesy of LINBIT
Configuring Servers
In this example, I configure a cluster consisting of two servers hosting data. When the data is updated to the one server, under the hood, DRBD will replicate it to the secondary server and its block storage. This scenario will be ideal when services such as NFS are hosted and the primary node becomes unresponsive or fails. Access to the necessary file-sharing services and its file content will continue uninterrupted.
Both hosts have the exact same configuration, and I will be using a secondary (local) drive with the exact same capacity on each, /dev/sdb:
$ cat /proc/partitions|grep sd 8 0 10485760 sda 8 1 1024 sda1 8 2 1835008 sda2 8 3 8647680 sda3 8 16 20971520 sdb
It is extremely important that both nodes in the cluster see one another in the network and can access the companion node by its hostname. If not, then be sure to modify your /etc/hosts file to address that requirement. If you are not sure about whether your hosts can reach each other, a simple ping or ssh from one to the other should provide the answer (Listing 1).
Listing 1
Test Ping
§§nonuber petros@ubu22042-1:~$ ping ubu22042-2 PING ubu22042-2 (10.0.0.62) 56(84) bytes of data. 64 bytes from ubu22042-2 (10.0.0.62): icmp_seq=1 ttl=64 time=0.505 ms 64 bytes from ubu22042-2 (10.0.0.62): icmp_seq=2 ttl=64 time=0.524 ms 64 bytes from ubu22042-2 (10.0.0.62): icmp_seq=3 ttl=64 time=0.496 ms ^C --- ubu22042-2 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2312ms rtt min/avg/max/mdev = 0.496/0.508/0.524/0.011 ms
Also note in this example that my command-line commands reflect that I am using Ubuntu as the host operating system, although DRBD is not limited to Ubuntu. The operating system of your choice will likely look different for the following package management examples. Before proceeding, be sure to update your operating system on both nodes to the latest and greatest package revisions to ensure that you are running in a stable and secure environment:
$ sudo apt-get update && sudo apt-get upgrade
Again, on both nodes, install the DRBD package from the operating system's remote repository:
$ sudo aptitude install drbd-utils
On one node, open the /etc/drbd.conf file and add the details in Listing 2, making the proper adjustments to account for hostnames, IP addresses, and disk drives.
Listing 2
DRBD Config Details
§§nonuber
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
resource r0 {
protocol C;
startup {
wfc-timeout 15;
degr-wfc-timeout 60;
}
net {
cram-hmac-alg sha1;
shared-secret "secret";
}
on ubu22042-1 {
device /dev/drbd0;
disk /dev/sdb;
address 10.0.0.216:7788;
meta-disk internal;
}
on ubu22042-2 {
device /dev/drbd0;
disk /dev/sdb;
address 10.0.0.62:7788;
meta-disk internal;
}
}
Copy the configuration file over to the secondary server and run the final set of commands on both servers to create the metadata block, start the DRBD service daemon, and enable that same service to start on every bootup:
$ sudo scp /etc/drbd.conf ubu22042-2:/etc/ $ sudo drbdadm create-md r0 initializing activity log initializing bitmap (640 KB) to all zero Writing meta data... New drbd meta data block successfully created. $ sudo systemctl start drbd.service $ sudo systemctl enable drbd.service
You should now see a new block device listed on each machine:
$ cat /proc/partitions|grep drbd 147 0 20970844 drbd0
Next, configure the primary (active) node of the storage cluster:
$ sudo drbdadm -- --overwrite-data-of-peer primary all
You will not be able to run this command more than once or on more than one node; otherwise, you'll see a message like:
$ sudo drbdadm -- --overwrite-data-of-peer primary all 0: State change failed: (-1) Multiple primaries not allowed by config Command 'drbdsetup-84 primary 0 --overwrite-data-of-peer' terminated with exit code 11
At this point, the /dev/drdb0 of the primary node will synchronize over to the second. To watch the synchronization progress from the primary node to the secondary, on the secondary node, enter:
$ watch -n1 cat /proc/drbd
You should see something similar to the output shown in Listing 3. When synchronization is 100 percent complete, the same file will showcase the output in Listing 4.
Listing 3
Sync Progress
§§nonuber
Every 1.0s: cat /proc/drbd ubu22042-2: Sat Apr 8 16:19:01 2023
version: 8.4.11 (api:1/proto:86-101)
srcversion: 2A5DFCD31AE4EBF93C0E357
0: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r-----
ns:0 nr:1755136 dw:1755136 dr:0 al:8 bm:0 lo:1 pe:4 ua:0 ap:0 ep:1 wo:f oos:19215708
[>...................] sync'ed: 8.4% (18764/20476)M
finish: 0:10:40 speed: 29,964 (16,712) want: 41,000 K/sec
Listing 4
cat /proc/drbd
§§nonuber
$ cat /proc/drbd
version: 8.4.11 (api:1/proto:86-101)
srcversion: 2A5DFCD31AE4EBF93C0E357
0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:20970844 dw:20970844 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
At any point you can switch both primary and secondary roles by going to the primary node and executing:
$ sudo drbdadm secondary r0
(Note: The block device must not be mounted.) Going to the secondary node, enter:
$ sudo drbdadm primary r0 To validate, read the content of <C>/proc/drbd<C> and observe the order of the Primary and Secondary labels in the <I>Connected ro<I> section: 0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
Back on the primary node, format the DRBD storage volume with a filesystem, mount the DRBD storage volume, and verify that it's mounted:
$ sudo mkfs.ext4 -F /dev/drbd0 $ sudo mount /dev/drbd0 /srv $ df|grep drbd /dev/drbd0 20465580 24 19400632 1% /srv
You won't be able to mount the block device on the secondary node, even when fully synchronized. If you do, you'll see the error:
$ sudo mount /dev/drbd0 /srv mount: /srv: mount(2) system call failed: Wrong medium type.
Back on the primary node, create a test file:
$ echo "hello world" | sudo tee -a /srv/hello.txt hello world $ cat /srv/hello.txt hello world $ ls -l /srv/hello.txt -rw-r--r-- 1 root root 12 Apr 8 16:37 /srv/hello.txt
Assuming you wait the proper amount of time for the file to synchronize over to the secondary node, unmount the DRBD volume on the primary node and demote the node to a secondary role:
$ sudo umount /srv $ sudo drbdadm secondary r0
On the secondary node, promote its role to that of a primary, and then mount the DRBD volume:
$ sudo drbdadm primary r0 $ sudo mount /dev/drbd0 /srv
Now you should be able to see the same test file created earlier:
$ ls -l /srv/ total 20 -rw-r--r-- 1 root root 12 Apr 8 16:37 hello.txt drwx------ 2 root root 16384 Apr 8 16:33 lost+found $ cat /srv/hello.txt hello world
Note that if you are seeing the following error when changing node roles,
$ sudo drbdadm secondary r0 0: State change failed: (-12) Device is held open by someone Command 'drbdsetup-84 secondary 0' terminated with exit code 11
you can determine which process ID is holding the device open by typing:
$ sudo fuser -m /dev/drbd0 /dev/drbd0: 597
In my case, it is the multipathd daemon:
$ cat /proc/597/comm multipathd
After disabling the service:
$ sudo systemctl stop multipathd Warning: Stopping multipathd.service, but it can still be activated by: multipathd.socket
I had no problem continuing with my exercise.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
- DRBD Management Console Can Now Handle LVM Volumes
-
Live migration of virtual machines
 A big advantage in virtualization is the ability to move systems from one host to another without exposing the user to a long period of downtime. To that end, the hypervisor and storage component need to cooperate.
A big advantage in virtualization is the ability to move systems from one host to another without exposing the user to a long period of downtime. To that end, the hypervisor and storage component need to cooperate. -
Live Migration

A big advantage in virtualization is the ability to move systems from one host to another without exposing the user to a long period of downtime. To that end, the hypervisor and storage component need to cooperate.
-
Storage cluster management with LINSTOR
 LINSTOR is a toolkit for automated cluster management that takes the complexity out of DRBD management and offers a wide range of functions, including provisioning and snapshots.
LINSTOR is a toolkit for automated cluster management that takes the complexity out of DRBD management and offers a wide range of functions, including provisioning and snapshots. -
Adding high availability to a Linux VoIP PBX
 Maximize telephony uptime by clustering Asterisk or FreeSWITCH PBXs together.
Maximize telephony uptime by clustering Asterisk or FreeSWITCH PBXs together.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
