
Lead Image © erikdegraaf, 123RF.com
Getting data from AWS S3 via Python scripts
Pumping Station
Data produced on EC2 instances or AWS lambda servers often end up in Amazon S3 storage. If the data is in many small files, of which the customer only needs a selection, downloading from the browser can bring on finicky behavior. Luckily the Amazon toolshed offers Python libraries as pipes for programmatic data draining in the form of awscli and boto3.
At the command line, the Python tool aws copies S3 files from the cloud onto the local computer. Install this using
pip3 install --user awscli
and then answer the questions for the applicable AWS zone, specifying the username and password as you go. You then receive an access token, which aws stores in ~/.aws/credentials and, from then on, no longer prompts you for the password [1].
Data exists in S3 as objects indexed by string keys. If a prosnapshot bucket contains a video.mp4 video file under the hello.mp4 key, you can use the
aws s3 cp s3://prosnapshot/hello.mp4 video.mp4
command to retrieve it from the cloud and store on the local hard disk, just as in the browser (Figure 1).
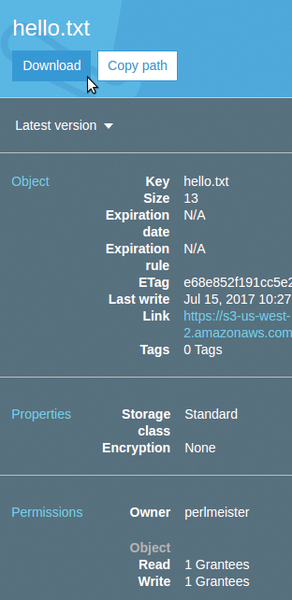 Figure 1: The browser moves selected S3 files from the cloud to the
Figure 1: The browser moves selected S3 files from the cloud to theBuy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Controlling Amazon Cloud with Boto
 The Boto Python module helps admins manage resources in the Amazon Cloud. We introduce you to the tool.
The Boto Python module helps admins manage resources in the Amazon Cloud. We introduce you to the tool. -
Integrating AWS Cloud Services with Your Custom Apps
The Boto Python module helps admins manage resources in the Amazon Cloud. We introduce you to the tool.
-
Tools for managing AWS cloud services
 The AWS Management Console, command-line tools, SDKs, toolkits for integrated development environments, and automation through Infrastructure as Code are all tools to help manage the operation of more than 200 services in the AWS cloud.
The AWS Management Console, command-line tools, SDKs, toolkits for integrated development environments, and automation through Infrastructure as Code are all tools to help manage the operation of more than 200 services in the AWS cloud. -
New storage classes for Amazon S3
 Each Amazon storage class addresses a different usage profile; we examine the new classes to help you make the right choice.
Each Amazon storage class addresses a different usage profile; we examine the new classes to help you make the right choice. -
S3QL filesystem for cloud backups
 Many HPC sites with petabytes of data need some sort of backup solution. Among the many candidates, cloud storage is a serious contender. In this article, we look at one solution with some serious advantages: S3QL.
Many HPC sites with petabytes of data need some sort of backup solution. Among the many candidates, cloud storage is a serious contender. In this article, we look at one solution with some serious advantages: S3QL.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
