
Lead Image © RFsole, Fotolia.com
OpenStack Sahara brings Hadoop as a Service
Computing Machine
Scalable cloud environments appear tailor-made for Big Data application Hadoop, putting it squarely in the cloud computing kingdom. Hadoop also has a very potent algorithm at its side: Google's MapReduce [1]. Moreover, the developer of Apache Lucene, Doug Cutting, is also the creator of Hadoop, so the project is not lacking in bona fides.
Hadoop, however, is a very complex structure composed of multiple services and various extensions. Much functionality means high complexity: You have to take many steps between planning a Hadoop installation and having a usable installation. A better, less complex idea is a well-prepared OpenStack service: The OpenStack component Sahara [2] offers Hadoop as a Service.
The promise is that administrators can click together a complete Hadoop environment quickly that is ready to use. Several questions arise: Will you see any benefits from Hadoop if you have not looked thoroughly into the solution in advance? Does Sahara work? Is the Hadoop installation that Sahara produces usable? I tested Sahara to find out.
Hadoop
The heart of Hadoop comprises two parts:
- The Hadoop Distributed File System (HDFS), a scalable filesystem characterized by its inherent high availability. HDFS primarily works as object-based storage (e.g., Ceph, which might become a replacement for HDFS).
- The MapReduce algorithm from Google. Map and Reduce are two functions within Hadoop that let you fish in the Big Data pond to find exactly the data needed.
Several components that fall into the "nice to have" category connect these two core components:
- HBase, a DBMS that runs on top of HDFS. It serves up data from a Hadoop cluster to the outside world.
- Hive, a data warehouse. The data stored in Hadoop can be not only searched but categorized using a syntax similar to SQL.
This list is certainly not complete; Hadoop has both official and unofficial extensions for almost every imaginable task.
Sahara
Once you have specified the kind of Hadoop cluster you have in mind, the theory is that Sahara should get on with the work and ultimately deliver a complete, ready-to-use cluster to the user. Like almost all other OpenStack services, Sahara comes in the form of several components (Figure 1).
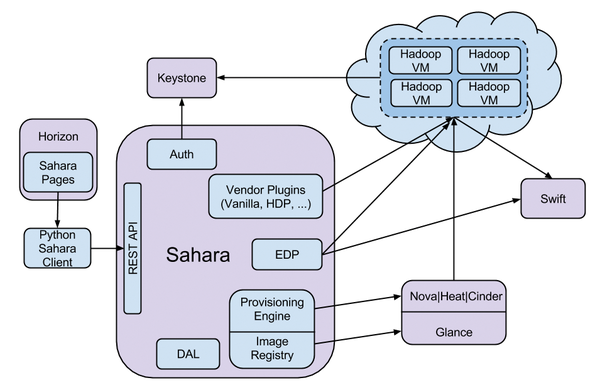 Figure 1: Sahara is a complex structure of several components; this graphic shows the most important ones [3]. (OpenStack.org)
Figure 1: Sahara is a complex structure of several components; this graphic shows the most important ones [3]. (OpenStack.org)
The core project consists of an application for authentication, a provisioning engine, its own database for operating system images, a job scheduler for elastic data processing (EDP), and the plugins used to create different Hadoop flavors. These are joined by a Sahara command-line client and an extension from the OpenStack Horizon component that allows administrators to use Sahara services via the OpenStack dashboard (Figure 2). Following the OpenStack philosophy, a RESTful API is on board.
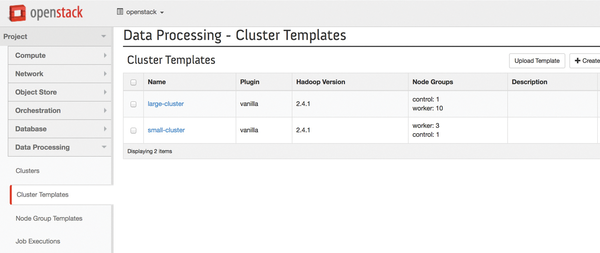 Figure 2: The levers for Sahara are hidden in the Data Processing menu item in the Horizon dashboard.
Figure 2: The levers for Sahara are hidden in the Data Processing menu item in the Horizon dashboard.
Naming Conventions
In typical OpenStack style, Sahara has a plethora of terms that do not exist or have a completely different meaning outside the context of Sahara. The term "cluster," for example, is of central importance: Clusters in Sahara are all virtual machines that belong to a Sahara installation, including the Sahara controllers, such as the workers. Sahara divides Hadoop installations into nodes on which specific services run. The master operates the Sahara name node, which acts as a metadata server. The core workers contain data and run a task tracker, which takes commands from the master node. Simple workers only process data, which comes from the core workers.
A central component of Hadoop is HDFS, designed for use in high-performance computing. The data is distributed to the installation's (the core workers') existing nodes. However, because one instance in the cluster must always know what data is where, the master runs the name node, so it is thus virtually a cluster-wide server for the HDFS metadata; that is, Sahara no longer thinks in terms of individual VMs. After all, it is a freely scalable computing cluster.
If the administrator starts a cluster with Sahara, it automatically leads to starting three groups: master, core workers, and workers. Sahara sets how many VMs belong to these groups dynamically at run time when called for by the administrator and adjusts the number automatically on request later on.
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
The new OpenStack version 2014.1 alias "Icehouse"
 The new OpenStack version "Icehouse" comes with new features and new components, on top of numerous improvements to existing components.
The new OpenStack version "Icehouse" comes with new features and new components, on top of numerous improvements to existing components. -
Big data tools for midcaps and others
 Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis. -
Hadoop for Small-to-Medium-Sized Businesses

Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
-
Ubuntu Server 14.04 LTS, 64-Bit
 The 64-bit server install image on this month's CD is for computers with the AMD64 or EM64T architecture (e.g., Athlon64, Opteron, EM64T Xeon, Core 2). Ubuntu Server emphasizes scale-out computing, whether you are administering an OpenStack cloud, a Hadoop cluster, or a massive render farm.
The 64-bit server install image on this month's CD is for computers with the AMD64 or EM64T architecture (e.g., Athlon64, Opteron, EM64T Xeon, Core 2). Ubuntu Server emphasizes scale-out computing, whether you are administering an OpenStack cloud, a Hadoop cluster, or a massive render farm. -
The New Hadoop

Hadoop version 2 expands Hadoop beyond MapReduce and opens the door to MPI applications operating on large parallel data stores.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
