
Lead Image © Kheng Ho Toh, 123RF.com
What's new in PostgreSQL 9.4
Modern Database
PostgreSQL has used a JSON data type for some time to simplify storing JSON documents in relational databases. This approach is useful for handling JSON documents as entities instead of mapping to a relational data model. Additionally, it allows data storage within a database, with all the advantages that PostgreSQL offers the user, such as uncompromising transaction security, excellent extensibility, and scalability in the same software component.
However, the original implementation of the JSON data type had a major drawback: JSON documents were stored in the database as strings and required parsing and analysis every time JSON data was accessed. Accessing elements of a document with this kind of representation is also very complex, to say nothing of indexing with any kind of efficiency.
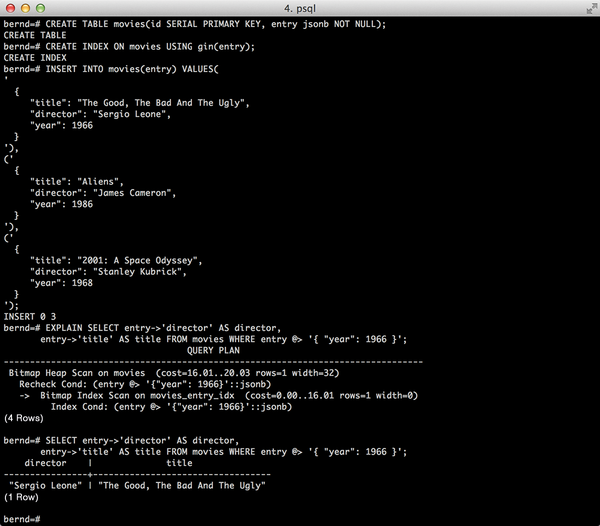
PostgreSQL 9.4 has now introduced a data type, in the form of JSONB, that handles and saves JSON documents as structured, binary data types. This allows efficient access to JSON documents as well as the implementation of fast index access methods. Scalar values from JSONB documents are stored as basic PostgreSQL types within a document. The query half-way down Figure 1 shows a very simple example with the table movies whose column entry contains a JSONB document with a film title. The @> operator checks whether the left operand contains the right JSONB expression.
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
PostgreSQL Replication Update
 High availability, replication, and scaling are everyday necessities in the database world. What features does PostgreSQL offer in this context, and how good are they?
High availability, replication, and scaling are everyday necessities in the database world. What features does PostgreSQL offer in this context, and how good are they? -
New in PostgreSQL 9.3
 The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance.
The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance. -
PostgreSQL 9.3
The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance.
-
Scale-out with PostgreSQL
 The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL.
The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL. -
High availability with Oracle Standard Edition
 Oracle offers several approaches to creating a high-availability environment. We look at the Standard Edition and some of the associated drawbacks to achieving this goal.
Oracle offers several approaches to creating a high-availability environment. We look at the Standard Edition and some of the associated drawbacks to achieving this goal.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
