hwloc
You just replaced your creaky, old server with a shiny, modern server. The new hotness has more (and faster) disks, has four times the amount of RAM, and is generally all around mo’bettah. But are you getting all the performance you should? Exactly where is all that memory, anyway? Do you know how big your shiny new L1, L2, and L3 caches are, and how they are shared across processor cores and sockets?
location, Location, LOCATION!
Most modern commodity servers have a non-uniform memory architecture (NUMA), meaning that the RAM is distributed between the processors on the machine. The processors are, in turn, connected by a high-speed network (e.g., QPI on Intel-based servers and Hypertransport on AMD-based servers).
The open source Portable Hardware Locality project [1], a sub-project of the larger Open MPI community [2], is a set of command-line tools and API functions that allows system administrators and C programmers to examine the NUMA topology and to provide details about each processor and memory type in a server. Plus, it draws pretty pictures! Managers love pretty pictures (Figure 1).
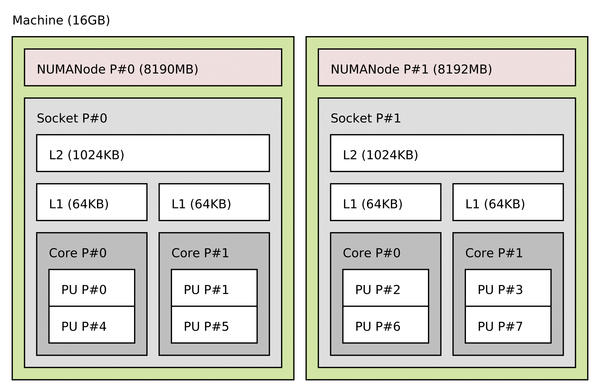 Figure 1: Sample output showing a two-socket, eight-core server with 16GB of RAM. “PU” stands for “processing unit” or hardware thread (“hyperthreads” in Intel processors).
Figure 1: Sample output showing a two-socket, eight-core server with 16GB of RAM. “PU” stands for “processing unit” or hardware thread (“hyperthreads” in Intel processors).
NUMA Background
When a process is running on a specific processor, reading and writing to memory directly attached to that processor is always fastest. Reading and writing to memory attached to a different processor is both slower and consumes bandwidth across the interprocessor network. Specifically, reading and writing to remote memory can even detract from performance of other processes on the server. Linux does a reasonably good job of trying to keep related processes and their memory local to each other. Usually, system administrators and C programmers can help Linux by issuing specific directives about where they want certain processes and their associated memory to be located.
Proper process and memory placement can have a dramatic effect on the performance of both the individual processes and the overall system.
(Non-)Portability of Server Topologies
Before you can place processes and their memory, however, you first need to know what the internal topology of your server is. Your server’s topology consists of a network of various entities, which hwloc calls objects .
Figuring out the topology of that network is hard because object numbering varies depending on factors such as the motherboard vendor, the BIOS version, and even with the operating system version. Changing any of these factors can result in the objects being renumbered. For example, Figures 2 and 3 show the same server but with the processor core objects ordered differently.
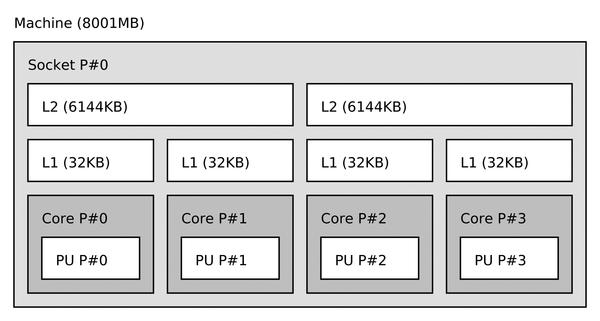 Figure 2: A quad-core processor with linearly numbered cores.
Figure 2: A quad-core processor with linearly numbered cores.
 Figure 3: A quad-core processor with interleaved cores.
Figure 3: A quad-core processor with interleaved cores.
Most operating systems – including Linux – offer methods of querying processor ordering and details of the server’s internal topology. Unfortunately, these methods are notoriously non-portable.
For example, the information returned from Linux’s /proc/cpuinfo and /sys virtual filesystem isn’t necessarily easy for humans to read and can be different between various hardware platforms and versions of the Linux kernel. Listing 1 shows an example of how Linux outputs this information for x86 architectures.
Listing 1: Linux Topology
$ cat /proc/cpuinfo [...] processor : 3 [...] physical id : 0 siblings : 4 core id : 3 cpu cores : 4 $ cd /sys/devices/system/cpu/cpu3/topology $ cat core_id 3 $ cat core_siblings 00000000,0000000f
Overview
The Hardware Locality tool suite (hwloc) takes care of hiding all these technical and non-portable details behind a convenient interface. The hwloc core gathers all the available pieces of information from the operating system and builds an abstracted, portable tree of objects: memory nodes (and node groups), caches, processor sockets, processor cores, hardware threads, and so on.
This tree can be obtained via hwloc’s CLI or C API. Figure 1 shows the graphical output from hwloc’s lstopo command on a machine with two NUMA nodes, each with a processor socket containing two cores. Each core has two hardware threads (known as “processing units” in hwloc terminology).
The hwloc tools (such as lstopo ) not only provide object numbering as seen by the OS (so-called “physical numbers”) but also compute a stable, logical numbering. This “logical” ordering runs linearly through adjacent objects and can thus be used to describe reliably which object is targeted, even if a server’s BIOS or operating system is upgraded.
The true power of hwloc is revealed when you start using its C programming interface. The entire tree of objects is presented in a cross-linked data structure; the tree can be traversed via children, parents, siblings, and cousins. Once an application finds the object or objects it is looking for in the tree, the hwloc tools can bind the execution or memory allocation, or both, of processes or threads to any (combination) of these objects from the command line or the through the C API.
Installation
Various Linux distributions are picking up hwloc (e.g., Debian Squeeze, Ubuntu 10.04, FC14, RHEL 6.1), but the suite is not available everywhere yet. Thus, you might need to download and install hwloc manually [3]. Once the suite has been downloaded, you can install hwloc with the common procedure:
$ ./configure [‑‑prefix=/there] [...] $ make all [...] $ sudo make install [...]
Optionally, you can specify a non-default installation location with the ‑‑prefix option. The hwloc suite is not dependent on any particular installation path; you can even safely install multiple copies or versions of hwloc into distinct prefixes on a single system.
Although a lot of effort has been put into making the configure /make steps “just work,” sometimes you need to specify some additional configure parameters to get what you need. Running configure ‑‑help will display a full list of the command-line switches that configure accepts, such as options to enable or disable XML, graphics support, and so on.
Command-Line Tools
Among the several command-line utilities hwloc includes, lstopo , described above, is perhaps the most common. It can output in plain text, prettyprint text, colored ANSI text, X11, FIG, Postscript, PDF, PNG, SVG, and XML formats. Listing 2, for example, shows the plain text output for a two-socket, eight-core server.
Listing 2: lstopo Textual Output.
01 Machine (24GB) 02 NUMANode P#0 (12GB) 03 Socket P#0 04 Core L#0 + PU L#0 (P#0) 05 Core L#1 + PU L#1 (P#2) 06 Core L#2 + PU L#2 (P#4) 07 Core L#3 + PU L#3 (P#6) 08 NUMANode P#1 (12GB) 09 Socket P#1 10 Core L#4 + PU L#4 (P#1) 11 Core L#5 + PU L#5 (P#3) 12 Core L#6 + PU L#6 (P#5) 13 Core L#7 + PU L#7 (P#7)
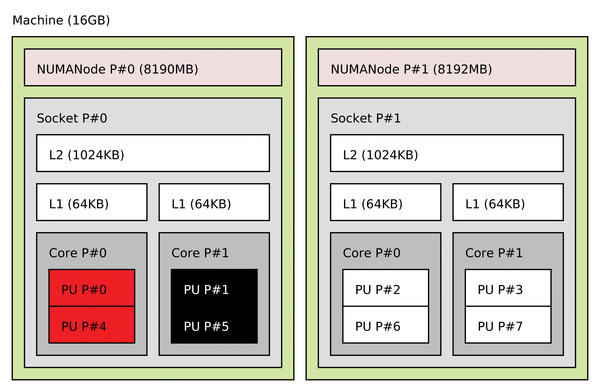 Figure 4: lstopo output, in which core P#0 is not available to the current user (e.g., restricted via Linux cpuset/cgroup), and core P#1 is offline.
Figure 4: lstopo output, in which core P#0 is not available to the current user (e.g., restricted via Linux cpuset/cgroup), and core P#1 is offline.
Only the resources actually available to the current process are displayed by default. Figure 4 shows a sample server with one core offline. Other resources (e.g., stopped or restricted cores) can also be displayed by giving the ‑‑whole‑system option. The lstopo XML export dumps the entire topology so that it can be used by other scripting tools (e.g., Perl scripts) or even loaded in lstopo on another server. The example below first exports the machine topology as seen on host2 , transfers the resulting XML file to host1 , then creates a PDF file.
host1$ ssh host2 host2$ lstopo h2.xml host2$ exit host1$ scp host2:h2.xml host1$ lstopo ‑i h2.xml h2.pdf
In addition to writing to files, if the DISPLAY environment variable is set; lstopo draws the topology in an X11 window. The lstopo utility can also filter the displayed topology to ignore some objects, display more verbose textual output (including all object attributes, such as, cache sizes), and so on.
After consulting the topology tree, hwloc can then be used to bind processes or threads to specific cores or sockets. The hwloc‑bind utility offers a command-line binding interface that benefits from hwloc’s advanced knowledge of the topology. Contrary to usual tools, such as taskset or numactl , that use physical processor and memory indexes, hwloc‑bind lets you bind tasks using logical (or physical) object identifiers.
In the example below, prog1 will run on any processing unit in the second logical socket, and prog2 will run on any processing units in the third or fourth logical core; whereas its memory will be allocated on the first logical NUMA memory node.
$ hwloc‑bind socket:1 ‑‑ prog1 $ hwloc‑bind core:2‑3 ‑‑membind numanode:0 ‑‑ prog2
Binding individual processes to specific locations is useful, but binding to load balance an entire server is more useful.
The hwloc‑distribute tool was designed to compute where to bind processes, depending on how many you want to distribute across the server. It returns bitmasks (i.e., a list of physical processing units) that can be given to hwloc‑bind . Listing 3 shows how four programs can be bound easily to the four cores of the whole machine in Figure 1 with the use of output from hwloc‑distribute .
Listing 3: Process Distribution
$ hwloc‑distribute 4 0x00000011 0x00000022 0x00000044 0x00000088 $ hwloc‑bind 0x00000011 prog1 $ hwloc‑bind 0x00000022 prog2 $ hwloc‑bind 0x00000044 prog3 $ hwloc‑bind 0x00000088 prog4
Note that Listing 3 shows that each process will be bound to two Linux virtual processors. These processors correspond to the two hardware threads (i.e., processing units) in each core in Figure 1.
As shown in Listing 4, hwloc also lets you check to see whether your processes are bound properly.
Listing 4: Getting the Binding
$ hwloc‑bind ‑‑get 7714 Core:2 $ hwloc‑ps 7712 PU:1 prog1 7713 PU:3 prog2 7714 Core:1 threadedprog $ lstopo ‑‑ps # ... topology output ... Core P#2 7714 threadedprog PU P#1 7712 prog1 PU P#3 7713 prog2
hwloc‑bind can return the current binding of any process, the hwloc‑ps utility lists all processes that are currently bound to part of the machine, and lstopo ‑‑ps inserts those processes into the topology output.
Finally, hwloc also includes a Swiss army knife called hwloc‑calc that serves as a generic conversion tool between miscellaneous hwloc objects. As shown in Listing 5,
Listing 5: The hwloc-calc Tool
# Output a mask containing # cores 0 and 1 $ hwloc‑calc Core:0‑1 0x00000033 # Largest objects containing # these cores $ hwloc‑calc Core:0‑1 ‑‑largest Socket:0 # List of physical indexes of # hardware threads (Processing # Units) contained in these cores $ hwloc‑calc Core:0‑1 ‑‑intersect PU ‑‑physical‑output 0,4,1,5 # List of physical indexes of # second hardware threads of all # cores $ hwloc‑calc Core:all.PU:1 ‑‑intersect PU ‑‑physical‑output 4,5,6,7
it accepts objects or bitmasks as input, combines them, and outputs the result as bitmasks, objects, lists of indexes, and so on. Its outputs can be given to other hwloc utilities or used in scripts.
C Programming Interface
A set of core functions is provided in hwloc.h , along with a large set of inline helpers in hwloc/helper.h .
In its simplest form, the initialization and detection of a topology can be reduced to two function calls to fill an hwloc_topology_t variable:
hwloc_topology_t t; hwloc_topology_init(&t); hwloc_topology_load(t);
In the preceding example, t is the head of a tree of objects that can be traversed many ways, including array-of-array style (Listing 6) or direct access of a specific type of object (see Listing 7).
Listing 6: Printing the Topology, Row by Row
01 hwloc_obj_t obj;
02 depth = hwloc_topology_get_depth(t);
03 for (d = 0; d < depth; d++) {
04 n = hwloc_get_nbobjs_by_depth(t, d);
05 for (i = 0; i < n; i++) {
06 obj = hwloc_get_obj_by_depth(t, d, i);
07 printf("%d,%d type %d\n",
08 d, i, obj‑>type);
09 }
10 }Listing 7: Direct Access of an Object Type
01 n = hwloc_get_nbobjs_by_type(topo, HWLOC_OBJ_CORE); 02 obj = hwloc_get_obj_by_type(topo, HWLOC_OBJ_CORE, n ‑ 1); 03 hwloc_set_cpubind(topo, obj‑>cpuset, 0);
In Listings 6 and 7, the type and cpuset members are just two examples of the variety of information available at each object in the tree.
Listing 7 also shows the use of hwloc_set_cpubind() to bind the current process to the specified cpuset. hwloc’s full documentation (in PDF, HTML [4], and man page format) describes many more functions and options, such as those to bind threads, bind other processes, and migrate memory, for example.
Finally, it should be noted that the hwloc community has created Perl and Python bindings to make this internal programming interface available through other languages.
Embedding hwloc within Your Software
In most cases, applications that use the hwloc C API can simply link against a system-installed hwloc. However, this might not always be the case.
Consider an example software package named Whazzle. Whazzle both requires hwloc and has been qualified with a specific version of hwloc. For these two reasons, the Whazzle developers decided to “embed” an entire copy of an expanded hwloc tarball in the Whazzle source code tree.
The presence of hwloc in the Whazzle code base ensures that hwloc will always be available on the target system – regardless of whether hwloc is installed on the system. This approach also guarantees that Whazzle uses the one, specific version of hwloc for which it has been developed and tested.
The hwloc embedding design works best with software projects that use GNU Autoconf, Automake, and Libtool. Whazzle fortunately uses these tools, so the Whazzle developers then use the hwloc-provided M4 GNU Autoconf macros in their configure.ac script.
As such, when Whazzle’s configure script is invoked, hwloc will also be configured, and when make is invoked with any of the standard Automake targets (e.g., all , clean , install , etc.), they also traverse into the hwloc directory and perform the appropriate actions.
Upcoming Features
The recently released version 1.2 of Hardware Locality [3] focused on exposing physical distances between objects (especially NUMA nodes) to applications that need such information to optimize their placement. In this version, the ability to restrict the hwloc topology to a custom part of the machine was also added.
Now it is also possible to find out where a process or thread runs, as opposed to where it is bound (e.g., if a single-threaded process was bound to an entire socket, it likely only ran on a single processing unit).
The next major release series of hwloc (1.3) will focus on adding I/O devices to the topology, because the performance of applications not only depends on where tasks are running and memory buffers are allocated, but also on which I/O peripherals they access (Figure 5).
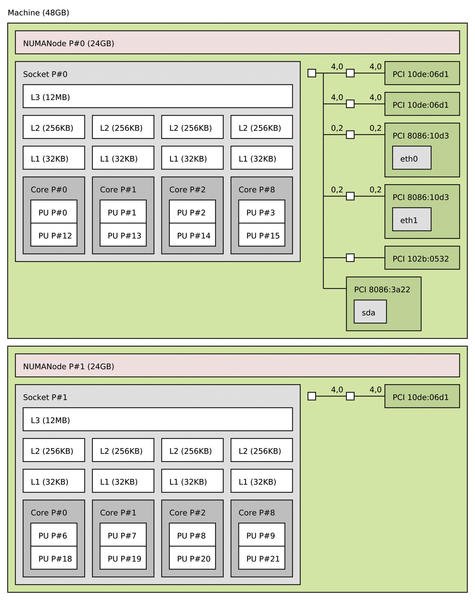 Figure 5: A two-socket, eight-core server with PCI devices.
Figure 5: A two-socket, eight-core server with PCI devices.
Additionally, v1.3 will enable process and memory placement according to I/O locality, as shown in Listing 8.
Listing 8: Binding Processes (v1.3)
# Starts io_program on a core # near the sda disk $ hwloc‑bind os=sda io_program # Starts web_server on a core # near the eth2 interface $ hwloc‑bind os=eth2 web_server # Starts my_prog near the PCI # device whose bus ID is 02:04.0 $ hwloc‑bind pci=02:04.0 my_prog
The Final Word
The real power of the hwloc tool suite is that it provides a portable mechanism to examine and utilize server hardware topology. Developers can effect topology-based decisions in their applications, and system administrators can load balance their servers.
Indeed, the hwloc community is growing, and a variety of software projects have incorporated hwloc support, including (but not limited to) Open MPI, MPICH2, MVAPICH2, Padb, ForestGOMP, StarPU, PLASMA, DAGuE, Qthreads, the Rose compiler, and the Open Grid Scheduler.
Remember, as core counts in servers continue to go up, it’s all about location, Location, LOCATION!
Info
[1] The Portable Hardware Locality (hwloc) project:
http://www.open-mpi.org/projects/hwloc/
[2] Open MPI: Open Source High Performance Computing:
http://www.open-mpi.org/
[3] hwloc current release:
http://www.open-mpi.org/software/hwloc/current/
[4] hwloc CLI and API documentation:
http://www.open-mpi.org/projects/hwloc/doc/
Related content
-
Warewulf Cluster Manager – Development and Run Time

The Warewulf cluster is ready to run HPC applications. Now, it’s time to build a development environment.
-
CPU affinity in OpenMP and MPI applications
 Get better performance from your nodes by binding processes and associating memory to specific cores.
Get better performance from your nodes by binding processes and associating memory to specific cores. -
Processor and Memory Affinity Tools

Get better performance from your nodes by binding processes and associating memory to specific cores .
-
Grid Engine: Running on All Four Cylinders

Two years after the Oracle acquisition of Sun, Grid Engine is still alive and scheduling jobs.
-
Processor Affinity for OpenMP and MPI

Processor affinity with serial, OpenMP, and MPI applications.