Getting Started with HPC Clusters
On the Beowulf mailing list recently, Jim Lux started a discussion about “learning clusters” – that is, low-cost units that can be used to learn about clusters. For many years people have wondered how they can get started with clusters, usually in one of two ways: (1) I want to learn parallel programming, and (2) I want to learn how to build and/or administer clusters. Sometimes the question is simple curiosity: What is a Beowulf cluster and how can I build one?
In the past, you had just a few options: (1) Get access to a cluster at a nearby university, (2) buy/borrow/use some old hardware to build one yourself, or (3) build your own cluster using parts from various sources. However, with the rise of virtualization, you now have more system options than ever, particularly if your budget is limited.
In this article I’ll take a quick look at various system options for people who want to learn about clusters, focusing on the programming and administration aspects. These options range in price, learning curve, ease of use, complexity, and, doggone it, just plain fun. But the focus is to keep the cost down while you are learning. The one aspect of clusters that I’m not really going to focus on is performance. The goal is to learn, not to find the best $/GFLOPS or the fastest performance. Performance can come later, once you have learned the fundamentals.
Learning to Program
The first typical response to the question of how to get started writing programs for HPC clusters is, “learn MPI programming.” MPI (Message Passing Interface) is the mechanism used to pass data between nodes (really, processes).
Typically, a parallel program starts the same program on all nodes, usually with one process per core, using tools that come with MPI implementations (i.e., mpirun or mpiexec ). For example, if you have two four-core systems, your applications would likely use up to eight processes total – four per node. Your application starts with the desired number of processes on the various nodes specified either by you or the job scheduler (resource manager). MPI then opens up communications between each process, and they exchange data according to your application program. This is how you achieve parallelism – each application runs with its own set of data, and they communicate with each other to exchange data as needed.
To get started, just search the web for “MPI tutorial,” and you will find several options. To run your application, you need some hardware, and the simplest thing to do is use what you already have. Most likely you have at least a dual-core system, so run your application with two processes (the MPI parlance is np=2 , or “number of processes = 2”). The kernel scheduler should put one process on each core. You can also run with more than two processes, but the kernel will time slice (context switch) between them, which could cause a slowdown. Moreover, you need to make sure you have enough memory and the system does not start swapping (hint, use vmstat to watch for swapping). Although it’s best to run one process per core, while you are learning and if you have enough memory, it doesn’t hurt to try more processes than physical cores.
Remember that in this instance you’re not looking for performance, you’re only learning how to write applications. If you run your application on a single system with a single core and then run on two cores, you would hope to see some improvement in performance, but that’s not always true (and that’s the subject of another article).
If you want to extend your programming to larger systems, you will need something larger than your desktop or laptop computer. Later, I will present some options for this, but in the next section, I want to talk about how you can use virtualization on your laptop or desktop computer to learn about cluster tools and management.
Virtual Machines on Your Computer
For this lesson, I’m going to assume you have access to a desktop or a laptop with some amount of memory (e.g., 2-4GB as a starting point) and a reasonably new version of Linux that supports virtualization. Although you could use Microsoft Windows, that is a road for others to map – I will focus on using Linux.
The goal is to spin up at least one, if not more, virtual machines (VMs) on your system and use them to simulate a cluster. I won't go into detail about creating a VM or starting it up because you have access to a number of tutorials on the web, such as:
Creating a CentOS KVM Virtual Machine at Techotopia
Virtualization With KVM On A CentOS 6.2 Server at HowtoForge.
KVM and CentOS-6 at wiki.centos.org
KVM virt-manager: Install CentOS As Guest Operating System at cybercitiz.biz
CentOS KVM Install – Quick Start to a VM at forwardingplane.net
The advantage of using VMs is being able to spin up more VMs than you have real physical processors and letting the kernel time slice between them. Because they are logically isolated from one another, you can think of VMs as different nodes in a cluster. With your “cluster simulator,” you can learn to program for clusters or learn how to create and manage HPC clusters.
Several cluster tool kits are around the web that you can use to learn about building HPC clusters. One example is Warewulf. I've written a series of articles about how to build a cluster using Warewulf, but you might need to adjust a few things because the newer version is slightly different from the version used when I wrote this article (the changes are small in my opinion). The developers of Warewulf routinely use VMs on their laptops for development and testing, as do many developers, so it’s not an unusual choice.
Once the cluster is configured, you can also run your MPI or parallel applications across the VMs. For maximum scalability, you would like to have one VM per physical core so that performance is not impeded by context switching; however, you can easily create more VMs than you have physical cores, as long as you have enough memory in the system for all the VMs to run. Fortunately, you can restrict the amount of memory for each VM, keeping the total memory of all VMs below a physical limit. (Don’t forget the memory needed by the hypervisor system!)
Just remember that you don't have to stop at one system when using VMs. You can take several systems and create VMs on each, growing the cluster to a greater number of systems. For example, if you have two quad-core systems, you can easily set up four VMs on each node, giving you a total of eight VMs. But what if you want to go larger?
Send in the Clouds
Although you might not be a fan of the word “cloud,” the concepts behind it have utility. In the case of HPC, clouds allow you to spin up a cluster fairly quickly, run some applications, and shut down the cluster fairly quickly. This capability is particularly useful while you are learning about clusters, because you can start with a few instances and then add more as you need them. Plus, once you are done, you can just shut it all down and never have to worry about it.
It’s fairly obvious that Amazon EC2 is the thousand-pound gorilla in the cloud room. Amazon EC2 has been around for about six years and has developed good tools and instructions on easily creating clusters using Amazon Web Services (AWS). Also, they have a very nice video that explains how to build a cluster quickly using AWS.
In general, you can take a couple of routes when dealing with the cloud and clusters. The first is to install the OS and cluster tools on your various VMs using something like Warewulf, as mentioned earlier, although you can substitute other cluster tools for Warewulf if you like. This method is useful if you want to understand how cluster tools work and how you administer a system.
If you just want a cluster up and working in the cloud, you have another option: StarCluster. It was developed at MIT specifically for building clusters in the cloud, namely Amazon’s EC2. A very nice howto for StarCluster gets you up and running very quickly, and a nice slide deck on SlideShare has an accompanying video that explains how to get StarCluster up and running.
A subtle point in the video is that Amazon has created pre-configured images called “Amazon Machine Images” (AMIs). AMIs are a collection of pre-configured OS images for VMs that are primarily open source because of licensing issues. In addition to Amazon-defined images are community-defined images and images that you create. These images can save you a lot of time when installing an OS because the tools can be integrated into the image, and you can add data and applications to images as you like.
In addition to compute services, Amazon EC2 also provides storage, which comes in several forms, including local storage, Amazon Elastic Block Storage (EBS), Amazon S3, and Amazon Glacier. Local storage is very interesting option, but remember, this storage also goes away once the VMs are stopped. Using EC2 you can perhaps learn about building and installing Lustre, GlusterFS, Ceph, or other storage solutions, without having to buy a bunch of systems.
As an example, Robert Read from Intel has recently experimented with building Lustre in Amazon EC2. The goal was to understand performance and how easy it is (or is not) to build Lustre within EC2. Read found that Lustre performed well and scaled fairly easily (you just add VMs) on AWS. Plus, the new distributed metadata (distributed namespace, DNE) is a good fit for AWS. However, currently, AWS needs a more dynamic fail-over capability because many people run metadata servers (MDSs) and object storage servers (OSSs) in fail-over mode (for better uptime).
Amazon Elastic Block Store (EBS) provides block-level storage volumes to images. They are network-attached (think iSCSI) and have the option of being “optimized” so that throughput is improved to about 500-1,000Mbps. Most importantly, they are persistent, so that if the VM is stopped, data is not lost. They have a limit of 1TB per EBS volume, but you can attach multiple volumes per image. Discussing Amazon S3 and Glacier is the subject for another article at another time, but just know that they can be used for storing data.
The large number of VM instances on Amazon are organized by breaking them up into instance families:
- General-Purpose (M1 and M3)
- Compute-Optimized (C1 and CC2)
- Memory-Optimized (M2 and CR1)
- Storage-Optimized (HI1 and HS1)
- Micro Instances (T1)
- GPU Instances (CG1)
A number of VM instances for each of these families vary on the basis of performance and cost. If you examine them, you will discover that Amazon gives you 750 free hours on micro instances plus some storage.
You can use any number of VM instances for learning about clusters. Examine the pricing carefully because some fees apply for moving and storing data. However, using a cloud such as Amazon EC2 is a great way to get started learning about clusters.
Crazy Eddie’s Used Systems
Up to this point, I’ve mostly focused on the software aspect of clusters – programming and cluster tools. However, the first two letters of HPC stand for “high” and “performance,” which means understanding and tuning the hardware for the cluster. Toward this end, you need to find some hardware to build your own cluster.
An easy way to get started is to find some older hardware that is no longer being used. Friends and family are good sources of old hardware, and you can sometimes even find good deals at yard sales, although “buyer beware” is a truth when you are in someone's garage buying a used PC. A number of websites also sell reasonable used systems. (Google is your friend, but be sure you read reviews before buying from a website.) A few stores also sell used hardware, but their prices can be a bit on the high side because you usually get some sort of warranty with them.
If you go the route of older hardware, I’m going to assume you want to use them without the virtualization I discussed in previous sections. The HPC world calls this using “bare metal.” Although you can use just one system to learn about cluster programming, just as you could use your laptop or desktop, as explained in the first section, ideally, you should have access to two or more systems and a basic switch. Figure 1 shows an outline of a really basic cluster with three compute nodes. (I’ve shown three compute nodes for illustration, but you can get by with just one.)
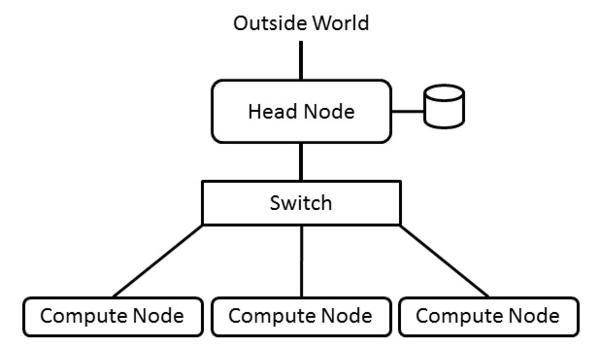 Figure 1: Generic cluster layout.
Figure 1: Generic cluster layout.
The most important item is the Head Node, also called the master node , and it is the brains of the cluster, if you will. In this particular setup, it also contains some storage for users, as shown by the disk to the right of the head node. The head node also contains the cluster tools used to provision other nodes, called compute nodes , and to control the running of applications.
Notice that the head node has two network connections: one to the Outside World , which is the connection into the cluster and, often, network device eth0, and the second is from the head node to the cluster switch, which is a private network, so many times it will have an address of 192.168.x.x (don’t forget that the head node has two Ethernet interfaces). This network is the only way the head node accesses the cluster nodes. You can use a single compute node or several. The only real requirements is that they can run a reasonable distribution.
The details on how you create a cluster from a head node, a switch, and a compute node, are usually found with the documentation of the cluster tool you are learning to use. Although it’s beyond the scope of this article to cover them, look around because a number of articles discuss how to set up and configure hardware for the various cluster tools.
Low-Cost Build-Your-Own
Using older, used systems that you borrow or buy from friends or family is a good way to get started learning about clusters and “hacking” the hardware, but sometimes there really is nothing like choosing your own systems. This way, you have control of the hardware and know precisely what is in each node. This means going shopping.
When learning about clusters, my aim is to control the costs as much as possible. The prices I’ll be quoting are from Newegg when I was writing this article (your mileage may vary), although you might be able to find cheaper prices. Also, just because I’m listing these items does not mean I endorse the associated companies (or the website). I just looked for the least expensive products in the various categories.
Table 1 lists the components for a simple head node with a reasonable amount of memory (4GB) and a dual-core processor. Notice that these prices don’t include tax and delivery (those vary too much to be accurately estimated). I included a DVD burner in the head node, but this is not strictly necessary. Overall, roughly US$ 250 will get you a dual-core head node.
Table 1: Dual-Core Node
| Name | Description | Quantity | Price | Extended Price |
| AMD A4-3300 processor | 2.5GHz dual-core processor with AMD Radeon HD 6410D graphics | 1 | $39.99 | $39.99 |
| ASRock A55M-V2 FM1 motherboard | MicroATX Socket FM1 motherboard; 2x240-pin DDR3 2400+ (OC)/1866/1600/1333/1066/800 memory; 16GB maximum memory, dual-channel; 1 PCIe 2.0x16 slot, 1 PCI slot; 2x SATA 3Gbps connectors, RAID-0/1/10; Realtek 8105E GigE NIC | 1 | $42.99 | $42.99 |
| 1866MHz dual-channel memory | 2x 2GB = 4GB total memory | 1 | $39.99 | $39.99 |
| ZION XON-720P mATX/ITX slim desktop case | 300W power supply | 1 | $34.99 | $34.99 |
| 250GB SATA 3.0Gbps disk | — | 1 | $59.99 | $59.99 |
| DVD +/-RW burner | — | 1 | $14.99 | $14.99 |
| GigE network card | — | 1 | $15.00 | $15.00 |
| Total | — | — | — | $247.94 |
A compute node version of the head node doesn’t need a DVD burner or the second NIC, bringing the price down to US$ 218. If you want to be more daring and go diskless, then the price is US$ 158 for a compute node.
Out of curiosity, I also configured a quad-core server to get an idea how much the extra cores cost. I used the same basic configuration as the dual-core, but I used the least expensive quad-core processor I could find. With the extra cores, I doubled the memory to 8GB using 4 DIMM slots instead of two, so each each core has 2GB of memory (same as the dual-core system). Table 2 shows the configuration I used. Roughly US$ 370 will get you a quad-core head node.
Table 2: Quad-Core Head Node
| Name | Description | Quantity | Price | Extended Price |
| AMD A6-3650 processor | 2.6GHz quad-core processor with AMD Radeon HD 6530D graphics | 1 | $69.99 | $69.99 |
| ASRock A75 PRO4-M FM1 motherboard | microATX Socket FM1 motherboard; 4x240-pin DDR3 2400+ (OC)/1866 (OC)/1600 (OC)/1333/1066/800 memory; 32GB maximum memory, dual-channel; 2 PCIe 2.0x16 slots (x16, x4), 2 PCI slots; 5x SATA 6Gbps connectors, RAID-0/1/10; Realtek 8111E GigE NIC | 1 | $74.99 | $74.99 |
| 1600MHz dual-channel memory | 4x4GB = 16GB total memory | 2 | $49.99 | $99.98 |
| ZION XON-720P mATX/ITX slim desktop case | 300W power supply | 1 | $34.99 | $34.99 |
| 250GB SATA 3.0Gbps disk | — | 1 | $59.99 | $59.99 |
| DVD +/-RW burner | — | 1 | $14.99 | $14.99 |
| GigE network card | — | 1 | $15.00 | $15.00 |
| Total | — | — | — | $369.93 |
For the compute nodes, you don’t need the second NIC or the DVD burner, resulting in a price of US$ 340. If you go diskless, you can get the price down to US$ 280.
You can get a small five-port GigE switch for less than US$ 20.00. Throw in some Ethernet cables at about US$ 2 per cable, and you get the following system totals:
- Five-node dual-core processor cluster: US$ 1,150 @ US$ 115/core
- Five-node dual-core processor, diskless cluster: US$ 910 @ US$ 91/core
- Five-node quad-core processor cluster: US$ 1,760 @ US$ 88/core
- Five-node quad-core processor, diskless cluster: US$ 1,520 @ US$ 76/core
These pricing games can be fun, but in all seriousness, they give you an idea of how much money you would need to build your five-node cluster. (I limited it to five total nodes because of the size of the GigE switch.) Building your own systems means you know exactly what is in the cluster and how to tune it for the best possible performance.
Summary
The question of how to get started working with HPC clusters comes up all the time as people discover and want to learn about HPC computing. The two fundamental things to learn about clusters are writing applications and running or administering clusters. In this article, I walked through some options, starting with building and running applications on what you have today – your laptop or desktop computer – and highlighting options for further investigation.
One of the quickest and easiest ways to really get started is to use virtualization, which is sort of the antithesis of HPC: Virtualization takes a single system and makes it appear to be several separate systems; HPC tries to take several systems and make them appear to be a single system. You can use your laptop or desktop to run a number of VMs and then use them to learn about HPC applications or administering clusters. In doing so, you not only learn about HPC, you learn about virtualization for Linux, which is not a bad skill to have.
The next step up from using VMs on your laptop or desktop is to use VMs from a cloud provider such as Amazon. Cloud VMs give you a great deal of freedom in choosing the level of performance, as well as the number of VMs, you want. It also gives you another kind of freedom: Once you are done with the system, you just turn it off and it goes away. Cloud VMs can also be fairly cost effective because you only pay for the time you use them. However, you also don't have the benefit of owning the hardware and learning more about the details of configuring it and tuning applications for it.
Finally, I went over some options for your own hardware, starting with used or older systems. These can usually be found stashed away in a basement or closet of friends or family, or even at yard sales (buyer beware). Using older systems can give you a very quick start for configuring, managing, and running a cluster using bare metal.
Of course, nothing is as fun as building the systems yourself. The last option I covered was a quick configuration guide for building a cluster with a head node, a private network, and one to five compute nodes. Going this route allows you to understand what truly goes into the system, so you can tune it to run applications or tune the applications for the hardware.
If you are brand new to HPC, I would suggest starting with learning how to program for clusters, because this helps you understand how parallel applications work and gives you a much better understanding of clusters. Choose the easiest route; spinning up some VMs on your laptop or desktop is not a bad way to go because you learn about virtualization while you are learning about HPC.
Once you have written an application or two and understand how they work, and if you are interested in learning how to build or manage clusters, you should move on and experiment with cluster tools. Again, the easiest way to get started is to use VMs on your laptop or desktop. I know some cluster tool developers that do this everyday, illustrating the usefulness of such an approach, even though nothing beats building your own hardware.
Related content
-
Kubernetes clusters within AWS EKS
 Automated deployment of the AWS-managed Kubernetes service EKS helps you run a production Kubernetes cluster in the cloud with ease.
Automated deployment of the AWS-managed Kubernetes service EKS helps you run a production Kubernetes cluster in the cloud with ease. -
Clusters with Windows Server 2012 R2
 With Windows, you can create a highly available cluster at the click of a button. The cluster will even handle fully automated, non-disruptive software upgrades.
With Windows, you can create a highly available cluster at the click of a button. The cluster will even handle fully automated, non-disruptive software upgrades. -
ClusterHAT

Inexpensive, small, portable, low-power clusters are fantastic for many HPC applications. One of the coolest small clusters is the ClusterHAT for Raspberry Pi.
-
Building an HPC Cluster

High-performance computing begins with understanding what you are trying to achieve, the assumptions you make to get there, and the resulting boundaries and limitations imposed on you and your HPC system.
-
StarCluster Toolkit: Virtualization Meets HPC

Cloud computing has become a viable option for high-performance computing. In this article, we discuss the use case for cloud-based HPC, introduce the StarCluster toolkit, and show how to build a custom machine image for compute nodes.