Understanding I/O Patterns with strace, Part III
I’ve written articles in the past about I/O patterns and examined them using strace . This type of information comes from the perspective of the application – that is, what it sends to the OS. The OS then takes these requests and acts on them, returning a result to the application. Understanding the I/O pattern from an application's perspective allows you to focus on that application. You can then switch platforms or operating systems or distributions, or even tune the OS with an understanding of what your application requests from the OS.
The choice of language and compiler or interpreter have a great deal of influence on the resulting I/O pattern, which will be different when using C than when using Fortran, Python, and so on. In a series of three articles, I use three languages that are fairly common in HPC to illustrate these differences: C, Fortran 90, and Python (2.x series). I run the examples on a single 64-bit system with CentOS 6.2 using the default GCC compilers, GCC and GFortran (4.4.6), and the default Python (2.6.6).
With the use of a simple example in each language, I’ll vary the number of data type elements to get an increasing amount of I/O. The strace output captured when the application is executed will be examined for the resulting I/O. By varying the number of elements, my goal is to see how the I/O pattern changes and perhaps better understand what is happening.
In previous articles, I used strace to help understand the write I/O patterns of an application written in C and Fortran 90. Now, I want to do the same thing with an application written in Python. My goal is to understand what is happening in regard to the I/O and even how I might improve it by rewriting the application (tuning).
Python
One of the “up and coming” languages in HPC is Python, which is being used increasingly in HPC for real computations. For example, many genomic pipelines are being written in Python, as are many data analysis tools.
I will begin by taking the C code in Listing 2C of the first article (reproduced as Listing 1P here) and rewrite it in Python. Initially, I just write out the data structure in the loop once it's populated, which I refer to as “one-by-one.”
Listing 1P: C Code Example with Output in Loop (One-by-One)
1 #include<stdio.h>
2
3 /* Our structure */
4 struct rec
5 {
6 int x,y,z;
7 float value;
8 };
9
10 int main()
11 {
12 int counter;
13 struct rec my_record;
14 int counter_limit;
15 FILE *ptr_myfile;
16
17 counter_limit = 100;
18
19 ptr_myfile=fopen("test.bin","wb");
20 if (!ptr_myfile)
21 {
22 printf("Unable to open file!");
23 return 1;
24 }
25 for ( counter=1; counter <= counter_limit; counter++)
26 {
27 my_record.x = counter;
28 my_record.y = counter + 1;
29 my_record.z = counter + 2;
30 my_record.value = (float) counter * 10.0;
31 fwrite(&my_record, sizeof(struct rec), 1, ptr_myfile);
32 }
33 fclose(ptr_myfile);
34 return 0;
35 }Although my Python is not likely to be “pythonic” enough for some people, I'm just looking at the I/O portion of the code and not the code itself (Listing 2P).
Listing 2P: Python Code Example with Output in Loop (One-by-One)
1 #!/usr/bin/python
2
3 if __name__ == "__main__":
4
5 local_dict = {'x':0, 'y':0, 'z':0,'value':0.0};
6
7 counter_limit = 100;
8
9 f = open('test.bin', 'r+')
10 for counter in range(1,counter_limit):
11 local_dict['x'] = float(counter);
12 local_dict['y'] = float(counter + 1);
13 local_dict['z'] = float(counter + 2);
14 local_dict['value'] = 10.0 * float(counter);
15 f.write(str(local_dict));
16 # end for
17 f.close();
18
19 # end mainI'm using the standard fwrite Python function to perform the output. This function requires string data, hence the transformation of the dictionary into a string with the str() function in line 15.
Python is an interpreted language, so gathering the strace output of a script means you have to gather the strace of the Python interpreter itself. Consequently, you get a great deal of output about loading modules and getting the interpreter ready to run a script (including “loading” the script itself). In the strace output that follows, I have limited the lines of output shown to those that open the output file test.bin , do the I/O, and close the file. This greatly cuts down on the amount of output in this article for the Python runs.
Even when using only 100 iterations (Figure 1P), notice the two write() calls in the strace output.
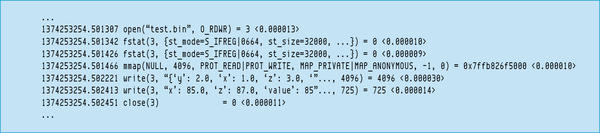 Figure 1P: Strace excerpt with Python one-by-one code; 100 iterations.
Figure 1P: Strace excerpt with Python one-by-one code; 100 iterations.
The first write() hits the 4,096-byte buffer limit, leaving 725 bytes for the second write() . Remember that the fwrite() function in Python wants the data to be written as a character string, so this will likely increase the amount of data written by the application.
A total of 4,821 bytes was written for only 100 iterations – quite a bit more than for C (1,600) or Fortran (2,400). A quick computation of the throughput of the first write shows it to be 136.5GBps, which is in line with the C and F90 code examples for the same algorithm.
In Figure 2P, the strace output excerpt for 256 iterations, you can see four write() function calls, with the first three hitting the buffer limit of 4,096 bytes. A total of 13,089 bytes are written.
 Figure 2P: Strace excerpt with Python one-by-one code; 256 iterations.
Figure 2P: Strace excerpt with Python one-by-one code; 256 iterations.
In the next two examples, I increase the number of iterations to 500 (Figure 3P) then 2,000 to see whether the trend of increasing buffer-limit writes continues.
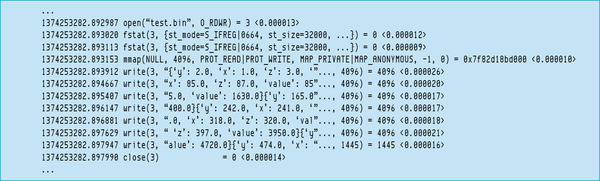 Figure 3P: Strace excerpt with Python one-by-one code; 500 iterations.
Figure 3P: Strace excerpt with Python one-by-one code; 500 iterations.
Five hundred iterations produces seven writes, with the first six reaching the 4,096-byte buffer limit, so it appears that the buffer limit trend continues until fewer than 4,096 bytes are left to write. For completeness, I show the 2,000-iteration case in Figure 4P.
 Figure 4P: Strace excerpt with Python one-by-one code; 2,000 iterations.
Figure 4P: Strace excerpt with Python one-by-one code; 2,000 iterations.
This number of iterations used 27 write() functions, with a total of 109,524 bytes of data written. Contrast this with the C code, which wrote 32,000 bytes, and Fortran 90 code, which wrote 52,124 bytes. Python has more than doubled the I/O of Fortran and trebled that of C. However, as with C and Fortran, you rely on the OS to combine writes to increase throughput performance. Perhaps a better way to do I/O is to use an array, called a “list” in Python, to store the data and then do all of the I/O in a single function call.
One of the better kept I/O secrets in Python is something called a pickle, which is an object serialization module. Basically, it allows you to write out objects, such as a list or a dictionary, with a single write statement.
I changed the Python code in Listing 2P to use pickle instead of fwrite() (Listing 3P). The defensive code around the pickle module import is a habit of mine. Additionally, I use a list of dictionaries and add them using the append method for the list class. To mirror the discussions in the previous articles for C and F90, I refer to this version of the Python code as the “array” method.
Listing 3P: Python Code Example with Output in Loop (Array)
1 #!/usr//bin/python
2
3 try:
4 import pickle;
5 except ImportError:
6 print "Cannot import pickle module - this is needed for this application.";
7 print "Exiting..."
8 sys.exit();
9
10
11 if __name__ == "__main__":
12
13 local_dict = {'x':0, 'y':0, 'z':0,'value':0.0};
14 my_record = []; # define list
15
16 counter_limit = 2000;
17
18 f = open('test.bin', 'r+')
19 for counter in range(1,counter_limit):
20 local_dict['x'] = float(counter);
21 local_dict['y'] = float(counter + 1);
22 local_dict['z'] = float(counter + 2);
23 local_dict['value'] = 10.0 * float(counter);
24 my_record.append(local_dict);
25 # end for
26 pickle.dump(my_record,f);
27 f.close();
28
29 # end mainFirst I’ll run the array code using 100 elements and gather the strace output. Because these runs produce quite a bit of output, I'm not going to show it all, but one thing I did discover is that the version of Python I'm using with CentOS 6.2 uses the cStringIO module to do the pickling. cStringIO is a much faster way to write() and read() when using a C library, so it should improve the code I/O.
 Figure 5P: Strace excerpt with Python array code; 100 elements.
Figure 5P: Strace excerpt with Python array code; 100 elements.
One of the most remarkable things about this output is that only 471 bytes were written for 100 elements (compression perhaps?). This is much less than either C (1,600) or Fortran (1,608).
Next I’ll try 256 (Figure 6P) and 500 elements (Figure 7P) to see whether they also produce less output than expected.
 Figure 6P: Strace excerpt with Python array code; 256 elements.
Figure 6P: Strace excerpt with Python array code; 256 elements.
 Figure 7P: Strace excerpt with Python array code; 500 elements.
Figure 7P: Strace excerpt with Python array code; 500 elements.
For 256 elements, only 1,097 bytes were written (again, much smaller than either C [4,096] or Fortran[4,104]). In the strace output excerpt for 500 elements, you can see that only 2,073 bytes were written in 0.00029 seconds. Because the output is still below the buffer limit, only a single write() was used.
Finally, I’ll finish with the 2,000-element case (Figure 8P).
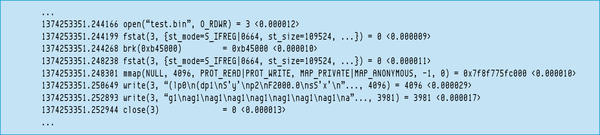 Figure 8P: Strace excerpt with Python array code; 2,000 elements.
Figure 8P: Strace excerpt with Python array code; 2,000 elements.
This time Python had to use two writes to output all the data. The first write() hit the buffer limit of 4,096 bytes, leaving only 3,981 bytes for the second write() . Once again, the total number of bytes written is smaller than for C or Fortran. The Python pickle example wrote 8,077 bytes, whereas C wrote 32,000 bytes and Fortran 32,008 bytes.
Summary
This series of three articles on tracking I/O patterns with strace using three languages yielded a few lessons. The first is that strace can help you understand the I/O pattern of an application from the application’s perspective. You can get a great deal of useful information from the strace output. Although it doesn't tell you what the OS did with the I/O requests, it does tell you what the application is sending to the OS.
The second lesson is that paying attention to how the application does I/O can be very important. In the C examples, I went from a number of 4,096-byte writes to much larger sized writes. In sequential streaming of I/O to the OS, larger writes can improve throughput performance. This kind of input also helps the OS, because it can tell the filesystem to open a file with a large number of allocated blocks, hopefully sequential, that can then be written to the underlying storage media in a streaming fashion, which is what hard drives really like.
The same isn't always true for Fortran. Fortran, and more specifically GFortran, appears to be limited to 8,192-byte I/O buffers. Fortran therefore has to rely on the underlying OS to combine writes to create streaming writes. Another lesson learned is that GFortran likes to put an lseek () between writes, which can also reduce throughput. For better I/O performance in Fortran, then, you might be better off using a library or abstraction for I/O, such as hdf5, or even writing your own C library that you can link to your Fortran code.
Python is a bit of a different beast. Although it is not a compiled language like C or Fortran, it is an interpreted language. Getting an strace of Python code involves tracing the interpreter as well. Consequently, you get a great deal of strace traffic about loading modules. By using the common Python output function fwrite() , the data is buffered only up to 4,096 bytes, and the amount of data written is larger than for C and Fortran.
However, Python has an output method called a pickle, and newer versions of Python, including the version I tested (2.6.6), use a high-speed I/O package called cStringIO . Although pickling the data resulted in hitting the 4,096-byte buffer limit with 2,000 elements, it also resulted in a much smaller amount of output than with Fortran or C. Pickling your Python data can have a huge effect on Python I/O performance compared with using the classic fwrite() method.
The last lesson I want to mention is that there is more than one way to do I/O. By switching from the “one-by-one” approach, which wrote the data once the data structure was full, to the “array” method, which created an array of data structures and filled them before writing out the data, I was able to improve my data I/O pattern. With the C code, I could write a much larger set of data at once, rather than hitting the predefined buffer limit. From a theoretical standpoint, the ability to better buffer the data can lead to better throughput performance.
Related content
-
Tuning I/O Patterns in Fortran 90

In the second article of this three-part series, we look at simple write examples in Fortran 90 and track the output with strace to see how it affects I/O patterns and performance.
-
Tuning I/O Patterns in C

The language you choose to use affects I/O patterns and performance. We track a simple write I/O pattern with C and look at how to improve performance.
-
Understanding the Status of Your Filesystem

Understanding the proliferation of data in your filesystem is key to being an administrator. Understanding file sizes and file ages and their distribution helps you tune filesystems for performance and develop policies for data management.
-
Darshan I/O analysis for Deep Learning frameworks
 Characterizing and understanding I/O patterns in the TensorFlow machine learning framework with Darshan.
Characterizing and understanding I/O patterns in the TensorFlow machine learning framework with Darshan. -
HPC Storage – I/O Profiling

HPC Storage is arguably one of the most pressing issues in HPC. Selecting various HPC Storage solutions is a problem that requires some research, study, and planning to be effective – particularly cost-effective. Getting this process started usually means understanding how your applications perform I/O. This article presents some techniques for examining I/O patterns in HPC applications.