The Road to End-of-Scale
Exascale has been in the news recently: The good new is that the US Subcommittee on Energy will likely fund exascale computing and that the science ministry of Japan is committed to developing a next-generation supercomputer by 2020.The not so good news came in a speech by Horst Simon, Deputy Director of Lawrence Berkeley National Laboratory, titled “Why We Need Exascale and Why We Won’t Get There by 2020” (see also Simon's slides from the Optical Interconnects Conference in Santa Fe, New Mexico, May 6, 2013). Can we keep extending the performance graphs of current technology and create an Exascale system by 2020?
The answer to that question is not easy. While there is need for exascale, can it be a FLOPS to far? Before presenting some of my back-of-the-envelop analysis, I want to go on record and state that I fully support the Exascale effort. HPC is tool that moves everyone forward, and there are bigger problems yet to mastered. My concern is that the historical exponential technology growth rate with which we have been accustomed cannot go on forever. Although Moore’s Law still seems to be holding, it does not always translate into linear performance gains. Consider the graph of CPU clock frequency in Figure 1 (courtesy of Paul E. McKenney, Is Parallel Programming Hard, and, If So, What Can You Do About It?) that shows a nice linear growth rate stopped right in its tracks..
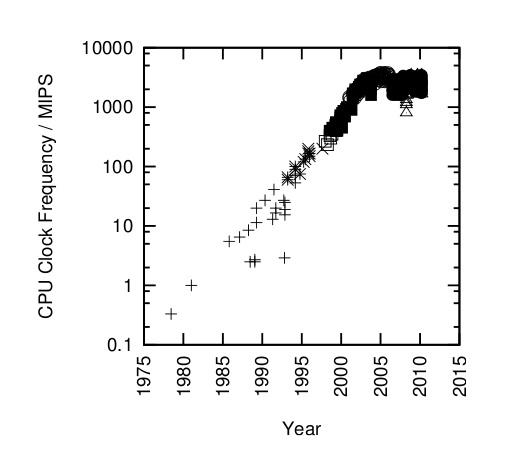 Figure 1: CPU clock frequency over time (CC BY-SA 3.0 US).
Figure 1: CPU clock frequency over time (CC BY-SA 3.0 US).
Of course, you know the reason: Higher clocks, and thus temperatures, were not sustainable. That is not to say clock rates will not increase – they are moving slowly higher because of improvements in process technology – but not at the exponential rate with which we all became very comfortable. All exponential growth must end at some point. The ability to shrink transistors did not slow, however; Moore’s Law continues to hold (for now). The industry decided “if we can’t make processors faster, we’ll add more of them,” and thus the introduction of multicore and the parallel way of life. To be sure, though, there was a hard stop in the growth rate of processor clocks.
Parallel computing is great if you don’t have to think about it. Unfortunately, in the HPC business, you need to think about it more than most. In my opinion, there is also a bit of confusion about parallel computing. Many people confuse parallel execution and concurrency. Concurrency is a property of an algorithm or program; that is, parts of the program can operate independently and give the correct answer. Parallel execution is the ability to take the concurrent parts, execute them at the same time, and decease overall execution time. Just because something is concurrent does not guarantee it will result in a parallel speed-up. Parallel execution is more a function of the machine overhead than of the program. This effect is usually measured in scalability , or said another way: How much faster will my program go if I add more cores? Depending on the underlying application, weakly connected cores (GigE) might limit scalability, and strongly connected cores (InfiniBand or 10GigE) might increase scalability.
The ratio of concurrent to sequential processing is also very important in parallel execution. Figure 2 describes the very familiar Amdahl’s Law for parallel computing.
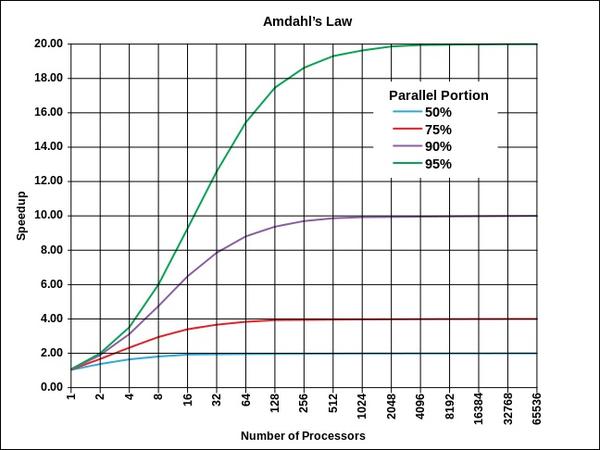 Figure 2: Amdahl’s Law and the limit of parallel speed-up (courtesy of Wikipedia, CC BY-SA 3.0).
Figure 2: Amdahl’s Law and the limit of parallel speed-up (courtesy of Wikipedia, CC BY-SA 3.0).
Obviously, best performance comes from minimizing sequential execution and maximizing concurrent execution. Machine overhead can be considered sequential execution, which is why things like interconnect latency and bandwidth can have a dramatic effect on program scalability, for some programs .
Drawling Lines
Now that some parallel computing 101 concepts have been established, I want to take a look at extending today’s technology toward the 2020 Exascale goal. Also, please keep in mind the following projections are back-of-the-envelope estimates. There is much more to this than can be discussed in a short article. In addition, this analysis assumes the goal of “all nodes must be able to communicate with any other node with full bandwidth and low latency.” Although this requirement might not be necessary for all parallel algorithms, it has always been an important design goal for all high-performance machines.
First I’ll look at where we are: the fastest machine, as per the TOP500 list, Titan at Oak Ridge National Lab. Titan can deliver 20PFLOPS of performance on the HPL benchmark using AMD Opteron processors and NVidia K20x accelerators. To reach exascale with the same benchmark, one needs to increase the performance by a factor of 50. Note that Simon suggests that we all agree that Exascale is number 1 on the TOP500 list with an R max > 1 exaFLOPS. He also notes that just running HPL (the TOP500 benchmark) will take about six days!
If you can sustain Moore’s Law, then you can apply Pollack’s Rule, which states processor performance increase due to microarchitecture advances is roughly proportional to the square root of the increase in complexity, suggesting that each new generation increases processor performance by a factor of two. Thus, if you were to apply this rule and allow for two more generations of process improvement by 2020, you could assume that the same Titan footprint could achieve 80PFLOPS. If you are generous and assume 100PFLOPS, you are still an order of magnitude away from the goal. Of course, if you can increase the size of the machine by a factor of 10, the goal might be possible. Recall that Titan employs GPUs, which provided a one-time bump in the performance curve, but nothing seems to be on the processor or GPU roadmap that would pass 100PFLOPS.
Assuming for the moment commensurate improvements in other aspects of the Titan – faster interconnects, larger and faster memory and filesystems – then perhaps an Exascale machine 10 times the size of Titan could be possible in 2020. These assumptions, however, could be difficult to justify. As Simon pointed out in his presentation, the power cost of moving bits around the machine will exceed the power cost of computation and might well overwhelm the total machine power budget. A high-performance parallel filesystem, although not necessary to set the Exascale TOP500 mark, would certainly be needed for the grand problems run on the machine. Currently, Titan has 20,000 spindles (moving parts) in its filesystem. Factoring the continued growth of magnetic storage media, an exaFLOPS machine with a 50 times greater parallel filesystem would need 114,000 spindles in 2020, which is clearly not impossible but would render the machine a bit more fragile because of the failure statistics of large numbers.
The Core Diameter
On the basis of the above analysis, it might be necessary to increase the physical size of an exascale machine beyond those of the petascale variety today. Titan can deliver 20,000TFLOPS in a volume of 800m3, which gives a compute density of 25TFLOPS/m3 and a power density of 10KW/m3 (17.6PFLOPS using 8,209KW). These numbers are typical. The most power-efficient machine in 2012, Beacon (National Institute for Computational Sciences/University of Tennessee), uses Intel Xeons and Phi accelerators to deliver 110TFLOPS using a volume of four standard racks. The teraFLOPS per cubic meter and the power density per cubic meter were virtually identical for two different hardware designs (i.e., AMD with NVidia accelerator and Intel with Intel accelerator).
If you assume that you are getting close to the limit of thermal density for computation, then you can’t really pack much more computation into a given amount of space. Exotic cooling methods probably will not reduce the volume of a machine by more than a factor of two. Recall that Titan is liquid cooled.
A while back I pondered what physical limits the speed of light (SOL) would have on really big machines. I had done some simple computations and come up with what I called the the core-diameter. In summary, I proposed a maximum diameter of a cluster in meters, beyond which the SOL would begin to dominate (reduce) latency between machines.
Using some simple numbers and a requirement of end-to-end latency of 2µs (microseconds), I estimated a core diameter of 32m. This diameter translates to a sphere of 17,000m3. I reduced this volume in half, assuming the need for machine access and infrastructure needs (heat removal, cabling, support structure). Thus, to keep all nodes within 2µs of each other, you would be limited to 8,500m3. With Titan a starting point, and assuming Pollack’s Rule (doubling the performance two times), you should be able to achieve 100TFLOPS/m3.
The SOL tells you that you can expect to fit 850PFLOPS (using 85,000KW of power) into your core radius before experiencing reduced latency, so you are close to, and might actually be able to hit, 1EFLOPS. Once the diameter is exceeded, however, latency increases and sequential overhead, as shown by Amdahl’s Law, starts to hammer at the scalability of the Exascale machine. If you want a lower machine-wide latency, which might be needed to provide better scalability than Titan (i.e., with 10 times more nodes than Titan), the core diameter gets smaller and reduces the amount of computation you can fit into the compute sphere.
The point of the above analysis is not to place an exact limit on the size of machines. It does, however, show that you will very soon be brushing up against some very real physical limits in terms of extreme-scale HPC. In particular, the 10KW/m3 power requirement will probably get slightly better, but not enough to be significant. The numbers can be refined and assumptions challenged, but like the exponential growth of processor clock speed, the rate must eventually flatten. If the growth shown in Figure 3 is going to continue, then many non-trivial barriers will need to be addressed. There is no simple way to keep extending the line . Hitting exaflops by 2020 is going to take commitment, engineering, and increased funding. It won't be easy.
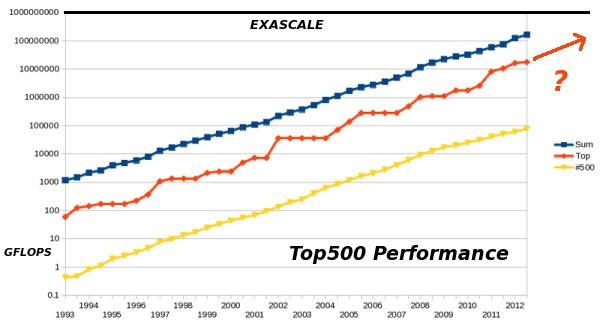 Figure 3: HPC growth of supercomputer performance, based on data from the TOP500.org site. Vertical axis shows performance in GFLOPS. Red line denotes fastest supercomputer in the world at the time. Yellow line denotes supercomputer number 500 on TOP500 list. Blue line denotes total combined performance of supercomputers on TOP500 list. (Courtesy of Wikipedia, CC BY-SA 3.0)
Figure 3: HPC growth of supercomputer performance, based on data from the TOP500.org site. Vertical axis shows performance in GFLOPS. Red line denotes fastest supercomputer in the world at the time. Yellow line denotes supercomputer number 500 on TOP500 list. Blue line denotes total combined performance of supercomputers on TOP500 list. (Courtesy of Wikipedia, CC BY-SA 3.0)
Related content
- XPRESS Project Focuses on High-Performance OS
- NERSC Gets Ready for Exascale
- Exascale Project Names a New Leader
-
Using loop directives to improve performance
 OpenACC is a great tool for parallelizing applications for a variety of processors. In this article, I look at one of the most powerful directives, parallel loop.
OpenACC is a great tool for parallelizing applications for a variety of processors. In this article, I look at one of the most powerful directives, parallel loop. - Argonne Announces Call for Papers for the Exascale Aurora System