« Previous 1 2
Stat-like command-line tools for admins
mpstat
One more tool I want to mention is not exactly along the lines of vmstat or dstat, but it has helped me when I'm helping a user with an application, particularly one that uses more than one core. The tool is part of Systat [11], and is called mpstat
[12]. Mpstat is more like iostat or nfsiostat, and it gives perhaps more and better information about the CPUs than vmstat or dstat. Because virtually all systems today have more than one core, mpstat can be very useful in tracking CPU usage. I use it when I'm writing OpenMP [12] code and want to see how much of the core capability I'm using. Figure 6 shows the output from
mpstat 1 10
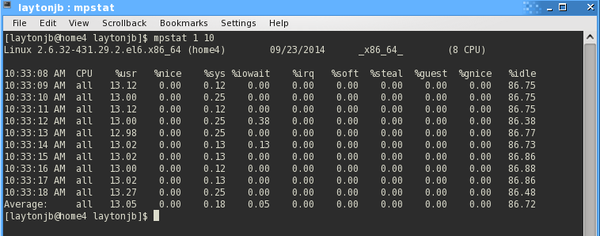 Figure 6: Mpstat output for all processors combined while running Python code.
Figure 6: Mpstat output for all processors combined while running Python code.
which outputs CPU statistics for 10 seconds at one-second intervals. The output first displays the system and the number of CPUs (eight, in this case), then starts printing the stats for all of the CPUs combined. The output is fairly similar to that of vmstat and dstat (Table 3).
Table 3: Mpstat Output
| Column | Output |
|---|---|
| CPU | Processor number to which the output refers. In Figure 6, it refers to all processors combined. |
| %usr | Percent CPU utilization by user applications. |
| %nice | Percent CPU utilization by user applications using the "nice" priority. |
| %sys | Percent CPU utilization at the system level (kernel). This does not include the time for servicing hardware or software interrupts. |
| %iowait | Percent CPU spent idle during which the system had an outstanding I/O request. |
| %irq | Percent CPU utilization spent servicing hardware interrupts. |
| %soft | Percent CPU utilization spent servicing software interrupts. |
| %steal | Percent CPU utilization spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor. |
| %guest | Percent CPU utilization spent by the CPU or CPUs to run a virtual processor. |
| %gnice | Percent CPU utilization spent by the CPU or CPUs to run a guest with a "nice" priority. |
| %idle | Percent CPU utilization spent idle while the system did not have an outstanding I/O request. |
The user applications are using a little over 13% of the total CPU capability, and the system is using a little less than 0.25%. The remaining roughly 86+% is idle (close to seven of eight cores). To see the details for each processor, use:
mpstat -P ALL
to show the same stats as in Figure 6, but for all of the CPU's combined and then for each core (Figure 7). I use this option to see if my programs using OpenMP code are using much of the CPU, which I hope reaches maximum core utilization.
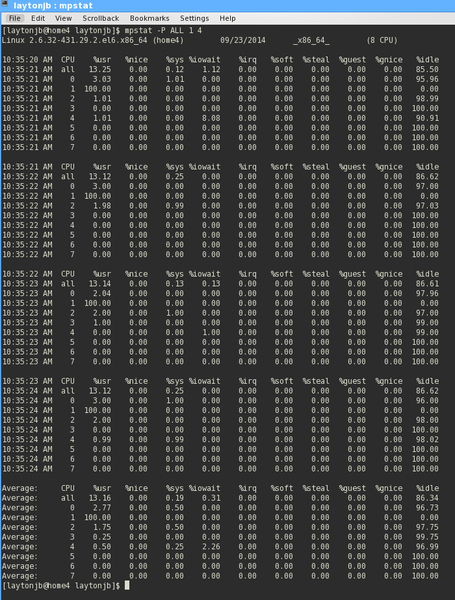 Figure 7: Mpstat output for each processor while running Python code.
Figure 7: Mpstat output for each processor while running Python code.
Summary
Sometimes you only have simple shell or crash cart access to a wayward node, so you can't run X. That means you have to rely on simple ASCII tools to help debug the problems.
I have found vmstat invaluable for diagnosing misbehaving nodes or checking or profiling user applications. For example, often when a user's application starts running slower, it's simply a matter of the user's application swapping on the compute nodes. A quick vmstat **1 **10 lets me see the problem and address it quickly. However, sometimes other issues require that you diagnose a node, and vmstat can't help. Fortunately, other people have run into the same problem and dstat was created. I tend to use dstat to get more information than I can get with vmstat.
Another tool I use, but not really to debug nodes, is mpstat, which helps me understand what my code is doing on a node. For example, if I'm writing OpenMP code, I can use mpstat to see if the cores are being used by user applications and, if so, how much. Moreover, you can use mpstat to diagnose performance problems that answer the question, "Why isn't my code running faster?"
Info
- "Top-like tools for admins" by Jeff Layton, ADMIN , issue 23, pg. 86, http://www.admin-magazine.com/Archive/2014/23/Top-like-tools-for-admins
- vmstat: http://en.wikipedia.org/wiki/Vmstat
- vmstat man page: http://linux.die.net/man/8/vmstat
- Kibibyte: http://en.wikipedia.org/wiki/Kibibyte
- VMSTAT Analyzer: http://www.codeproject.com/Articles/41848/VMSTAT-Analyzer
- VMLoad: https://gist.github.com/mmichaelis/1187126
- vmstat plotter: http://clusterbuffer.wordpress.com/admin-tools/vmstat-plotter/
- Web-vmstat: http://linoxide.com/tools/vmstat-graphical-mode/
- dstat: http://dag.wiee.rs/home-made/dstat/
- dstat man page: http://dag.wiee.rs/home-made/dstat/dstat.1.html
- Systat: http://sebastien.godard.pagesperso-orange.fr/
- mpstat: http://sebastien.godard.pagesperso-orange.fr/man_mpstat.html
- OpenMP: http://en.wikipedia.org/wiki/OpenMP
« Previous 1 2
Related content
-
Nmon: All-Purpose Admin Tool

HPC administrators sometimes assume that if all nodes are functioning, the system is fine. However, the most common issue users have is poor or unexpected application performance. In this case, you need a simple tool to help you understand what’s happening on the nodes.
-
Small Tools for Managing HPC

Several very sophisticated tools can be used to manage HPC systems, but it’s the little things that make them hum. Here are a few favorites.
-
Command-line tools for the HPC administrator
 Several sophisticated command-line tools can help you manage and troubleshoot HPC (or other) systems.
Several sophisticated command-line tools can help you manage and troubleshoot HPC (or other) systems. -
Sort Out the Top from the Bottom
As sure as the sun rises each morning, you can be certain that, at some point, an admin will need to diagnose why a failing server is overloaded and being worked too hard.
-
GUI or Text-Based Interface?

Sys admins are like smokejumpers who parachute into fires, fighting them until they are out, or at least under control. When you jump into the fire, you only have the tools you brought with you.