Performance Health Check
In a previous article I discussed prolog and epilog scripts with respect to a resource manager (job scheduler). Most of the prolog examples were simple and focused on setting up the environment before running a job, whereas the epilog example cleaned up after an application or workflow was executed. However, prolog and epilog scripts are not limited to these aspects. One aspect of prolog/epilog scripting that I didn’t touch on was checking the health of the nodes assigned to a job.
Generically, you can think of a node health check as determining whether a node is configured as it should be (i.e., setting the environment as needed, which I discussed somewhat in the previous article) and is running as expected. This process includes checking that filesystems are mounted correctly, needed daemons are running, the amount of memory is correct, networking is up, and so on. I refer to this as the “state” of the node’s health.
In that same article, I mentioned Node Health Check (NHC), which is used by several sites to check the health of nodes, hence the name. In my mind, it focuses on checking the “state” of the node, which is a very important part of the health of a node. A large number of options can be turned on and off according to what you want to check about the state of the node.
Almost 20 years ago, when I worked for a Linux high-performance computing (HPC) company that no longer exists, We had a customer who really emphasized the number of nodes that were available for running jobs at any one time. One of the ways we measured this was to run a short application and check the performance against the other nodes. If the performance was up to or close to that of the other nodes, the node was considered “up” and available for users to run jobs; otherwise, the node was considered down and not used to run jobs. I refer to this concept as the “performance” health of the node.
Performance-Healthy Nodes
Node performance health, at least in my mind, is greatly underappreciated. The node can be in a good state, where everything appears to be working, but it might not perform correctly (i.e., be healthy). The difficult question to answer is: What does “correctly” mean?
Because I’m talking HPC, the first typical reaction is to check that the node is running as fast as possible. Don’t forget that parallel applications only run as fast as the slowest node. Having a few nodes that run faster than the others is fine (who doesn’t like extra performance), but you want to find nodes that are running slower than most of the other nodes. To make this determination, you can check whether performance is less than the norm.
In this article, I present some aspects for determining whether the performance of a node is acceptable for a user’s application with the use of standard benchmarks that are run on the node before a user’s application is run. The results are then compared with typical node performance for the same benchmarks.
Standard Benchmarks – NPB
The applications you run to check the health of a node is really up to you, but I highly recommend some typical applications. Although HPC runs multinode applications, an easy place to start is to focus on single-node application runs that can use all cores, all memory, or both. You can even run a single core if you like. In my opinion, the emphasis should be on testing an important aspect of performance: peak CPU or GPU floating point operations per second (FLOPS), memory bandwidth, combinations of compute and memory, data transfer from the CPU to the GPU (bandwidth, latency, or both), data transfers to local or network storage, or scaling performance with more than one core.
An important aspect of the tests or benchmarks is that they don't take too much time to complete; you don’t want to have a heath check test that unduly delays starting a user’s application, particularly for jobs that might not run very long and a few minutes delay would be a big portion of the total runtime. You need a balance in the time it takes to complete the test, the usefulness of the test, and the user application execution time (which is likely to be unknown).
To determine performance, I use the NASA Advanced Supercomputing (NAS) parallel benchmarks (NPB), a set of code created by NASA to test performance of parallel systems, providing a proxy for computation and data movement in computation fluid dynamics (CFD) applications. NPB has been around for many years and has proven to be very useful in testing systems.
One of the best aspects of the NPB tests is the different “classes” of problems that allow you to test a wide range of system configurations, which has a great effect on the time it takes to complete the tests. Over the years, NPB has added new classes of problem sizes, multizone versions of some tests (great for OpenMP coding), and even some tests that stress I/O and data movement.
In 1991, the NAS Division created some benchmarks suited to their needs that had different problem sizes. So, in 1991 they started writing NPB and released it in 1992. Since then, NPB has had three major releases with new features, new code, and new languages.
The focus of the benchmarks was, as one would expect, derived from CFD applications. These benchmarks test many aspects of modern systems, from stressing the CPU in different ways, to memory bandwidth aspects, to interprocess and network communications. NPB started with five “kernels” and three pseudo applications. The kernels are:
- IS – integer sort, random memory access
- EP – embarrassingly parallel
- CG – conjugate gradient, irregular memory access and communication
- MG – multigrid on a sequence of meshes, long- and short-distance communication, memory intensive
- FT – discrete 3D fast Fourier transform (FFT) emphasizing all-to-all communication
The three pseudo applications are:
- BT – block tri-diagonal solver
- SP – scalar penta-diagonal solver
- LU – lower-upper Gauss–Seidel solver
The latest version of NPB is 3.4.2. Before NPB version 2.3, the benchmarks were all serial unless the compiler created multiprocessor binaries. NPB version 2.3, released in 1997, comprised a complete version of the benchmarks that used the Message Passing Interface (MPI), although the serial versions were still available.
In NPB release 3, three multizone versions of the benchmarks, termed NPB-MZ, were added that take advantage of MPI/OpenMP hybrid programming techniques and can stress interprocess communication and multinode communication, as well as single system aspects. A document describing these benchmarks was released in 2003.
The multizone (MZ) benchmarks are:
- BT-MZ – uneven-size zones within a problem class, increased number of zones as the problem class grows
- SP-MZ – even-size zones within a problem class, increased number of zones as the problem class grows
- LU-MZ – even-size zones within a problem class, a fixed number of zones for all problem classes
NAS also created a set of benchmarks for unstructured computations, data I/O, and data movement:
- UA – unstructured adaptive mesh, dynamic, and irregular memory access
- BT-IO – a test of different parallel I/O techniques
- DC – data cube
- DT – data traffic
The UA computation benchmark can push random memory access and memory bandwidth very easily.
The primary changes made to the benchmarks of the latest version 3.4.2 of the NPB are:
- added class F to the existing S, W, A, B, C, D, E
- added dynamic memory allocation
- added MPI and OpenMP programming models
The latest version of the multizone benchmarks is also 3.4.2. The primary changes to these benchmarks are:
- codes: BT-MZ, SP-MZ, LU-MZ
- classes: S, W, A, B, C, D, E, F
- programming models: MPI+OpenMP, OpenMP
- added dynamic memory allocation
The NAS Division has not released any official GPU versions of NPB, but if you look around the web, you can find various versions that others have created. Probably the most predominant version is NPB-GPU, which uses the CUDA parallel computing platform and programming model to produce the GPU versions of the five kernels and three pseudo applications.
Another common source of GPU versions is from Chemnitz University of Technology in the form of NPB-CUDA and NPB-MZ-CUDA.
Benchmarks To Use
Before you can test node health, you have to establish baseline performance. Because the node tests will be run before a user’s application, you don’t want to spend too much time on the benchmarks. How much time you spend is really up to you, but for the sake of argument, I will limit the time to 30-40 seconds per benchmark.
Running all the NBP benchmarks would take too much time. Eight benchmarks at 30 seconds each is four minutes. I’m not sure how many users want to wait four minutes before their applications start, just to test that the nodes are running correctly, but I can probably count them on one hand.
Instead, I'll run one or two benchmarks for a maximum of 30-80 seconds before the user’s application runs.
For a new system, I run the various NPB benchmarks on a single node with the maximum number of cores possible. I measure the runtime with the Linux time command, and I run the benchmarks a few times to compute the mean (Table 1). For this article, I ran the tests on an AMD CPU with six non-threaded cores, most of them for classes A, B, and C (standard test problems, with an approximate four times size increase going from one class to the next) where possible.
Table 1: NPB Test Results
| Benchmark |
Class A time (s) |
Class B time (s) |
Class C time (s) |
|
BT (4 cores) |
11.95 | 66.5 | 272 |
|
CG (4 cores) |
0.4 | 23.9 | 62.3 |
|
EP (6 cores) |
1.4 | 5.46 | 21.05 |
|
FT (4 cores) |
1.69 | 17.26 | 67.7 |
|
IS (4 cores) |
0.6 | 2.16 | 8.2 |
|
LU (6 cores) |
5.13 | 41.8 | |
|
MG (4 cores) |
1.2 | 3.8 | 39.1 |
|
SP (4 cores) |
16.2 | 138.3 |
Notice that for most benchmarks I could only use four cores. These benchmarks can only use a core count greater than one that is a multiple of two (i.e., 1, 2, 4, 8, 16, 32, etc.).
Looking through Table 1, I made the following observations and decisions:
- For my system, I could only run the IS test with a class C problem size. Therefore, I will restrict myself to classes A and B.
- The BT benchmark takes a while to run at class B sizes (66.5s), so I won’t use that test.
- I want to have at least one test that uses all the cores, so that points to EP and LU. However, LU takes 41.8s for a class B size, which is a bit long, so I won’t use the LU test, leaving the EP test.
- The FT test is for a discrete 3D FFT with all-to-all communication. FFT can be communication intensive even on a single node.
- The total runtime of EP and FT for class B size is about 23s, which is a fairly short time, so I will add the MG benchmark with a very short runtime (3.8s) for a class B problem size.
Therefore, I will run the EP, FT, and MG tests to check health performance. For class B, the EP test takes 5.46s, the FT test 17.26s, and the MB test 3.8s. If I stay with only class B tests, the total runtime would be about 27s, which I believe will be an acceptable time to wait before a job starts.
Acceptable Performance
The EP and FT tests measure performance. The next question to answer is: What is acceptable performance? The answer to this question will vary from site to site and from person to person, but I will discuss my ideas.
You can’t set acceptable performance by running benchmarks one time. You need to run them several (many?) times. For example, I would run each test a minimum of 21 times and collect the runtimes, so I can find any variation in the runs.
Next, I would compute the mean and standard deviation (SD) from the runtimes for each benchmark. To determine a cut-off value for performance, you should look at your distribution of runtimes. With a normal distribution (Figure 1; attribution 2.5 Generic (CC BY 2.5)), I don’t care whether the performance is better than the mean, so I can ignore any performance cut-off to the right of the mean. (On the other hand, if the node performance is significantly better than the mean, you might want to try to understand why it is performing so much better than the others.)
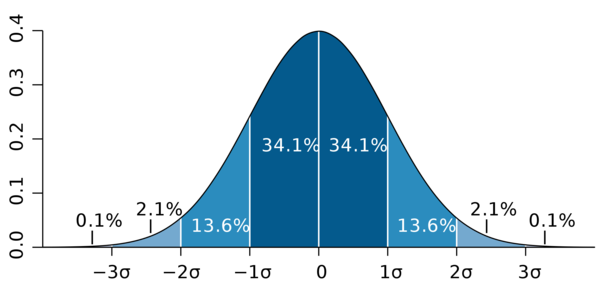 Figure 1: Normal distribution, with each band having a width of 1 standard deviation.
Figure 1: Normal distribution, with each band having a width of 1 standard deviation.
The lower bound of performance, or the left-hand portion of Figure 1, is of most interest. As always in HPC, acceptable performance varies from site to site and from person to person, but I choose to cut off the lower limit of performance (LLP) at
LLP = mean – 1/2(SD)
because 1 SD allows for a 34.1% reduction in performance (assuming a normal distribution). One-eighth of a standard deviation is 4.78% of normally distributed data or 95.22% of the mean, allowing for benchmarks 4.78% below the mean. If you select a standard deviation fraction of 0.01, then the minimum value is 96.02% of the mean.
To me, if I see more than a 5% drop in performance compared with the mean, I should probably start looking at the offending node. The problem could be noisy system processes, a user application that doesn’t close correctly, or even incorrect DIMM or CPU replacements that don’t match the speeds of the others.
Benchmark Process
Running health performance checks before a user application definitely sounds like the use of a prolog in the resource manager, because prolog scripts run before a job. The prolog script can be almost anything; just write the code as a Bash script, from which you can call scripts written in other languages such as Perl or Python, run applications, or execute Bash commands. Because prologs are run as root, be careful. For example, to run the EP benchmark use:
time mpirun -np 6 -h ./hostfile ep.B.x
The output could be written to a random file in /tmp and parsed for the runtime.
The benchmark time is then compared with the mean minus one-eighth of the standard deviation. If the test value falls below this computed value, the node is marked as down, and the user’s job is resubmitted. The benchmark runtime along with the node name is added to a file or database for unacceptable runtimes and the admin is notified.
If the result is greater than the cutoff, you should write the benchmark time and node name to a file of acceptable results. This file should be used to recompute the mean and standard deviation for future benchmark testing.
Four implicit assumptions underlie the process:
- The benchmark binary and all supporting libraries and tools must be available on every node in the cluster on which you run jobs.
- You must write a script to parse the output from the benchmarks, which should not be difficult.
- You have to establish two files (databases): one for storing the unacceptable results and the other for storing acceptable results.
- A resource manager must be present that uses a prolog before running a job. All the HPC resource managers that I know of have this capability.
Summary
Checking the health of a node is an important task for maximum utilization. I like to divide node health into two parts: state health and performance health. Both parts can run in a prolog script in the resource manager before the user’s application executes. These scripts can either report the results to the admin or be used to check that the node health is acceptable for running the user’s application.
To determine the state health of the node, you can write scripts to check on the various states, such as whether filesystems are mounted correctly, needed daemons are running, the amount of memory is correct, networking is up, certain system packages have the require version, and so on. NHC is a great tool for checking the state of a node, with a wide range of tests. NHC is in production at several sites, some of which are very large. The tool is well tested over several years and is easy to use. If you don’t want to write your own prolog scripts, NHC is definitely the tool of choice.
The performance aspect of node health is often ignored in HPC systems. I summarized some aspects of this health check with the use of standardized benchmarks. In particular, the NPB benchmarks were used as a basis for checking whether a node is performing well by testing various aspects of a system. These tests have been available since about 1992, are well understood, stress various aspects of the system, and are very easy to compile.
By running the NPB benchmarks on the nodes of an HPC system several times, you can determine the mean and standard deviation for the system. Then, you run the benchmarks on a node as part of a resource manager prolog to measure performance and compare the result with the system statistics. If the results for the node are less than a desired value, the node is marked down and the user’s job is resubmitted.
Determining a node’s performance health before running a user’s job can help both the user and the admin by reducing the number of questions around why an application might not be performing well. I hope this article has stimulated some ideas for measuring the performance health of your system.
Related content
-
Measuring the performance health of system nodes
 Many HPC systems check the state of a node before running an application, but not very many check that the performance of the node is acceptable before running the job.
Many HPC systems check the state of a node before running an application, but not very many check that the performance of the node is acceptable before running the job. -
Benchmarks Don’t Have to Be Evil

Benchmarks have been misused by both users and vendors for many years, but they don’t have to be the evil creature we all think them to be.
-
Using benchmarks to your advantage
 A collection of single- and multinode performance benchmarks is an excellent place to start when debugging a user's application that isn't running well.
A collection of single- and multinode performance benchmarks is an excellent place to start when debugging a user's application that isn't running well. -
Prolog and Epilog Scripts

HPC systems can benefit from administrator-defined prolog and epilog scripts.
-
ClusterHAT

Inexpensive, small, portable, low-power clusters are fantastic for many HPC applications. One of the coolest small clusters is the ClusterHAT for Raspberry Pi.