A Library for Many Jobs
In recent years, new programming concepts have enriched the computer world. Instead of increasing processor speed, the number of processors have grown in many data centers. Parallel processing supports the handling of large amounts of data but also often requires a delicate transition from traditional, sequential procedures to specially adapted methods. The Joblib Python library saves much error-prone programming in typical procedures such as caching and parallelization.
A number of complex tasks come to mind when you think about parallel processing. The use of large data sets, wherein each entry is independent of the other, is an excellent choice for simultaneous processing by many CPUs (Figure 1). Tasks like this are referred to as “embarrassingly” parallel. Where exactly the term comes from is unclear, but it does suggest that converting an algorithm to a parallelized version should not take long.
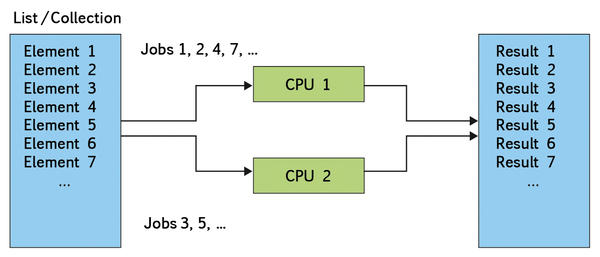 Figure 1:Problems involving input objects that can be independently and concurrently processed are referred to as “embarrassingly” parallel.
Figure 1:Problems involving input objects that can be independently and concurrently processed are referred to as “embarrassingly” parallel.
Experienced developers know, however, that problems can occur in everyday programming practice in any new implementation and that you can quickly get bogged down in the implementation details. The Joblib module, an easy solution for embarrassingly parallel tasks, offers a Parallel class, which requires an arbitrary function that takes exactly one argument.
Parallel Decoration
To help Parallel cooperate with the function in question (I’ll call it f(x) ), Joblib comes with a delayed() method, which acts as the decorator. Listing 1 shows a simple example of an implementation of f(x) that returns x unchanged. The for loop shown in Listing 1 iterates over a list l and passes the individual values to f(x) ; each list item in l results in a separate job.
Listing 1: Joblib: Embarrassingly Parallel
01 from joblib import Parallel, delayed 02 03 def f(x): 04 return x 05 06 l = range(5) 07 results = Parallel(n_jobs=-1)(delayed(f)(i) for i in l))
The most interesting part of the work is handled by the anonymous Parallel object, which is generated on the fly. It distributes the calls to f(x) across the computer’s various CPUs or processor cores. The n_jobs argument determines how many it uses. By default, this is set to 1, so that Parallel only starts a subprocess. Setting it to -1 uses all the available cores, -2 leaves one core unused, -3 leaves two unused, and so on. Alternatively n_jobs takes a positive integer as a counter that directly defines the number of processes to use.
The value of n_jobs can also be more than the number of available physical cores; the Parallel class simply starts the number of Python processes defined by n_jobs , and the operating system lets them run side by side. Incidentally, this also means that the exchange of global variables between the individual jobs is impossible, because different operating system processes cannot directly communicate with one another. Parallel bypasses this limitation by serializing and caching the necessary objects.
The optimum number of processes depends primarily on the type of tasks to be performed. If your bottleneck is reading and writing data to the local hard disk or across the network, rather than processor power, the number of processes can be higher. As a rule of thumb, you can go for the number of available processor cores times 1.5; however, if each process fully loads a CPU permanently, you will not want to exceed the number of available physical processors.
See How They Run
Additionally, the Parallel class offers an optional verbose argument with regular output of status messages that illustrate the overall progress. The messages show the number of processed and remaining jobs and, if possible, the estimated remaining and elapsed time.
The verbose option is by default set to 0 ; you can set it to an arbitrary positive number to increase the output frequency. Note that the higher the value of verbose , the more intermediate steps Joblib outputs. Listing 2 shows typical output.
Listing 2: Parallel with Status Reports
Parallel(n_jobs=2, verbose=5)(delayed(f)(i) for i in l)) [Parallel(n_jobs=2)]: Done 1 out of 181 | elapsed: 0.0s remaining: 4.5s [Parallel(n_jobs=2)]: Done 198 out of 1000 | elapsed: 1.2s remaining: 4.8s [Parallel(n_jobs=2)]: Done 399 out of 1000 | elapsed: 2.3s remaining: 3.5s [Parallel(n_jobs=2)]: Done 600 out of 1000 | elapsed: 3.4s remaining: 2.3s [Parallel(n_jobs=2)]: Done 801 out of 1000 | elapsed: 4.5s remaining: 1.1s [Parallel(n_jobs=2)]: Done 1000 out of 1000 | elapsed: 5.5s finished
The exact number of interim reports varies. At the beginning of execution, it is often still unclear how many jobs are pending in total, so this number is only an approximation. If you set verbose to a value above 10 , Parallel outputs the current status after each iteration. Additionally, the argument offers the option of redirecting the output: If you set verbose to a value of more than 50 , Parallel writes status reports to standard output. If it is lower, Parallel uses stderr – that is, the error channel of the active shell.
A third, optional argument that Parallel takes is pre_dispatch , which defines how many of the jobs the class should queue up for immediate processing. By default, Parallel directly loads all the list items into memory, and pre_dispatch is set to 'all ' . However, if processing consumes a large amount of memory, a lower value provides an opportunity to save RAM. To do this, you can enter a positive integer.
Convenient Multiprocessing Module
With its Parallel class, Joblib essentially provides a convenient interface for the Python multiprocessing module. It supports the same functionality, but the combination of Parallel and delayed() reduces the implementation overhead of simple parallelization tasks to a one-liner. Additionally, status outputs and configuration options are available – each with an argument.
In Memory
The previous example made use of a small and practically useless f(x) function. Some functions, however, regardless of whether they are parallelized, perform very time- and resource-consuming computations. If the input values are unknown before starting the program, a function like this might process the same arguments multiple times; this overhead could be unnecessary.
For more complicated functions, therefore, it makes sense to save the results (memorization). If the function is invoked with the same argument, it just grabs the existing result, rather than figuring things out again. Here, too programmers can look to Joblib for help – in the form of the Memory class this time.
Joblib provides a cache() method that serves as the decorator for arbitrary functions with one or more functional arguments. The results of the decorated function are then saved on disk by the memory object. The next time the function is called, it checks to see whether the same argument or the same arguments have been processed and, if so, returns the result directly (Figure 2). Listing 3 shows an implementation, again with a primitive sample function f(x) .
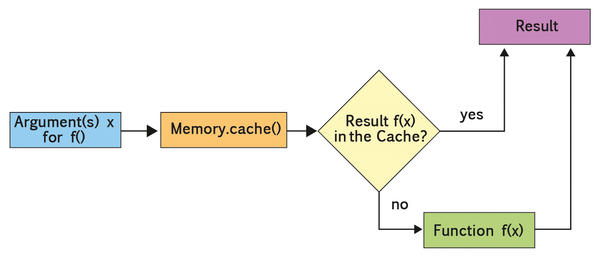 Figure 2:Memory stores the function results and delivers them without recomputing when re-requested.
Figure 2:Memory stores the function results and delivers them without recomputing when re-requested.
Listing 3: Store Function Results
01 from joblib import Memory 02 03 memory = Memory(cachedir='/tmp/example/') 04 05 @memory.cache 06 def f(x): 07 return x
The computed results are stored on disk in the JOBLIB directory below the directory defined by the cachedir parameter. Here again, each memorized function has its own subdirectory, which, among other things, contains the original Python source code of the function in the func_code.py file.
Memory for Names
A separate subdirectory also exists for each different argument – or, depending on the function, each different combination of several arguments. It is named for a hash value of the arguments passed in and contains two files: input_args.json and output.pkl . The first file shows the input arguments in the human-readable JSON format, and the second is the corresponding result in the binary pickle format used by Python to serialize and store objects.
This structure makes accessing the cached results of the memory function pleasantly transparent. The Python pickle module, for example, parses the results in the Python interpreter:
import pickle
result = pickle.load(open("output.pkl"))Memory does not clean up on its own at end of the program, which means the stored results are still available the next time the program starts. However, this also means you need to clean up the disk space yourself, if necessary, which is done either by calling the clear() method of the Memory object or simply by deleting the folder.
Additionally, you should note that Memory bases its reading of the stored results exclusively on the function name. If you change the implementation, Memory might erroneously return the results previously generated by the old version of the function the next time you start it. Furthermore, Memory does not work with lambda functions – that is, nameless functions that are defined directly in the call.
As a general rule, use of the Memory class is recommended for functions whose results are so large they stress your computer’s RAM. If a frequently called function only generates small results, however, creating a dictionary-based in-memory cache makes more sense. A sample implementation is shown on the ActiveState website.
Fast and Frugal
On request, the Memory class uses a procedure that saves a lot of time for large stored objects: memory mapping. The core idea behind this approach is to write a file as a bit-for-bit copy of an object from memory to the hard disk. When the software opens the object again, it copies the relevant part of the file into contiguous memory so that the objects it contains are directly available. This approach keeps the system from having to allocate memory, which can involve many system calls.
Joblib uses the memory mapping method provided by the NumPy Python module. The constructor in the Memory class uses the optional mmap_mode parameter to accept the same arguments as the numpy.memmap class: r+ , r , w+ , and c .
Memory Mapping
Under normal circumstances, mmap_mode='r+' is recommended for enabling memory mapping. This value opens an optionally existing file and appends new data. In the other modes, Memory does not write any new data but only reads from the existing file (r ) or overwrites the existing data (w+ ). The c (copy-on-write) mode tells Memory to treat the file on the disk as immutable, as with r , but it does keep new assignments in memory.
If you need to save disk space rather than time, you can initialize the memory object with the argument compress=True . This option tells the Memory function to compress results when saving to disk; however, it rules out the option of memory mapping.
Finally, the Memory class also allows you to issue status messages. Its verbose constructor argument defaults to 1 , which means that cache() outputs a status message every time a memorized function is called when computing the results from scratch. If you substitute verbose=0 , the potentially very numerous status reports are suppressed. Substituting the default value for something higher tells Memory to report on each call of the function, whether the result was in a file or is recomputed.
Finally, cache() uses the ignore parameter to accept a list of function arguments that it ignores during memorization. This functionality is useful, if individual function arguments only affect the screen output but not the function result. Listing 4 shows the f(x) function with the additional verbose argument, whose value is irrelevant for the return value of the function.
Listing 4: Ignoring Individual Arguments
01 from joblib import Memory
02
03 memory = Memory()
04
05 @memory.cache(ignore=['verbose'])
06 def f(x, verbose=0):
07 if verbose > 0:
08 print('Running f(x).')
09 return xOn Disk
Joblib also provides two functions for saving and loading Python objects: joblib.dump() and joblib.load() . These functions are also used in the Memory class, but they also work independently of it and replace the Python pickle module’s mechanisms for serializing objects with what are often more efficient methods. In particular, Joblib stores large NumPy arrays quickly and in a space-saving way.
The joblib.dump() function accepts any Python object and a file name as arguments. Without other parameters, the object ends up in the specified file. Calling joblib.load() with the same file name then restores this object:
import joblib
x = ...
joblib.dump(x, 'file')
...
x = joblib.load('file')Like Memory , dump() also supports the optional compress parameter. This parameter is a number from 0 to 9 , indicating the compression level: 0 means no compression at all; 9 uses the least disk space but also takes the most time. In combination with compress , the cache_size argument also determines how much memory Joblib uses to compress data quickly before writing to disk. The specified value describes the size in megabytes, but that is merely an estimate that Joblib exceeds if needed, such as when handling very large NumPy arrays.
The dump() complement load() also optionally uses the memory mapping method – like Memory . The mmap_mode argument enables this with the same parameters and possible values as for Memory : r+ , r , w+ , and c are used for reading and writing, exclusive reading, overwriting, or read-only and in-memory completion.
Prestigious Helper
The value of the Joblib library is hard to overstate. It solves some common tasks in a flash with an intuitive interface. The problems – simple parallelization, memorization, and saving and loading objects – are those programmers often encounter in practice. What you find here is a convenient solution that gives you more time to devote to genuine problems.
Joblib is included in most distributions and can otherwise easily be imported with the Python package management tools, Easy Install and Pip, using easy_install joblib or pip install joblib . This process is quick, because – besides Python itself – Joblib does not require any other packages.
Related content
-
Parallelizing and memorizing Python programs with Joblib
 The Joblib Python Library handles frequent problems – like parallelization, memorization, and saving and loading objects – in almost no time, giving programmers more freedom to push on with their core tasks.
The Joblib Python Library handles frequent problems – like parallelization, memorization, and saving and loading objects – in almost no time, giving programmers more freedom to push on with their core tasks.