Ceph Jewel
When Red Hat took over Inktank Storage in 2014, thus gobbling up the Ceph object store, a murmur was heard throughout the community: on the one hand, because Red Hat already had a direct competitor to Ceph in its portfolio in the form of GlusterFS, and on the other because Inktank was a such a young company – for which Red Hat had laid out a large sum of cash. Nearly two years later, it is clear that GlusterFS only plays a minor role at Red Hat and that the company instead is relying increasingly on Ceph.
In the meantime, Red Hat has further developed Ceph, and many of the earlier teething problems have been resolved. In addition to bug fixing, developers and admins alike were looking for new features: Many admins find it difficult to make friends with Calamari, the Ceph GUI promoted by Red Hat; they need alternatives. The CephFS filesystem, which is the nucleus of Ceph, has been hovering in beta for two years and needs finally to be approved for production use. Moreover, Ceph repeatedly earned criticism for its performance, failing to compete with established storage solutions in terms of latency.
Red Hat thus had more than enough room for improvement, and much has happened in recent months. A good reason to take a closer look at Ceph is to determine whether the new functions offer genuine benefits for admins in everyday life and see what the new GUI has to offer.
CephFS: A Touchy Topic
The situation seems paradoxical: Ceph started life more than 10 years ago as a network filesystem. Sage Weil, the inventor of the solution, was looking into distributed filesystems at the time in the scope of his PhD thesis. It was his goal to create a better Lustre filesystem that got rid of Luster’s problems. However, because Weil made the Ceph project his main occupation and was able to create a marketable product, the original objective fell by the wayside: Much more money was up for grabs by surfing the cloud computing wave than by sticking with block storage for virtual machines.
Consequently, much time was put into the development of the librbd library, which now offers a native Ceph back end for Qemu. Also, storage services in the same vein as Dropbox appear commercially promising: Ceph’s RADOS gateway provides this function in combination with a classic web server. If you were waiting for CephFS, you mainly had to settle for promises. Several times Weil promised that CephFS would be ready – soon. However, for a long time, little happened in this respect.
Besides Weil’s change in focus, the complexity of the task is to blame. On one hand, a filesystem such as CephFS must be POSIX compatible because it could not otherwise be meaningfully deployed. On the other hand, the Ceph developers have strict requirements for their solution: Each component of a Ceph installation has to scale seamlessly.
A Ceph cluster includes at least two types of services: a demon that handles the object storage device (OSD) and the monitor servers (MONs). The OSD ensures that the individual disks can be used in the cluster, and the MONs are the guardians of the cluster, ensuring data integrity. If you want to use CephFS, you need yet another service: the metadata server (MDS) (Figure 1).
 Figure 1: For CephFS to work, the cluster needs MONs and OSDs, plus a MDS. They developers beefed up the server in Ceph v10.2.0 (Jewel).
Figure 1: For CephFS to work, the cluster needs MONs and OSDs, plus a MDS. They developers beefed up the server in Ceph v10.2.0 (Jewel).
Under the hood, access to Ceph storage via CephFS works almost identically to access via block device emulation. Clients upload their data to a single OSD, that automatically handles the replication work in the background. For CephFS to serve up the metadata in a POSIX-compatible way, the MDSs act as standalone services.
Incidentally, the MDSs themselves do not store the metadata belonging to the individual objects. The data is instead stored in the user-extended attributes of each object on the OSD. Basically, the MDS instances in a Ceph cluster only act as caches for the metadata. If they did not exist, accessing a file in CephFS would take a long time.
Performance and Scalability
For the metadata system to work in large clusters with high levels of concurrent access, MDS instances need to scale arbitrarily horizontally, which is technically complex. Each object must always have a MDS, which is ultimately responsible for the metadata of precisely that object. It must thus be possible to assign this responsibility dynamically for all objects in the cluster. When you add another MDS to an existing cluster, Ceph needs to take care of assigning objects to it automatically.
The solution the Ceph developers devised for this problem is smart: You simply divide the entire CephFS tree into subtrees and dynamically assign responsibility for each individual tree to MDS instances. When a new metadata server joins the cluster, it is automatically given authority over a subtree. This needs to work at any level of the POSIX tree: Once all the trees at the top level are assigned, the Ceph cluster needs to partition the next lower level.
This principle is known as dynamic subtree partitioning (DSP) and has already cost Weil and his team some sleepless nights. The task of controlling the assignment of the POSIX metadata trees dynamically for individual MDSs proved to be highly complicated, which is one of the main reasons CephFS has not yet been released for production.
The good news: In the newest version of Ceph (Jewel v10.2.x), the developers were looking to stabilize CephFS. Although, that version was not available at the time of this review, the work on the DSPs was largely completed. [Recently, the Jewel version of CephFS was announced to be stable – “with caveats.”]
New Functions for CephFS
In addition to a working DSP implementation, the Jewel release of CephFS offers more improvements. So far, one of the biggest criticisms was the lack of a filesystem checking tool for CephFS. This criticism regularly raises its head in the history of virtually all filesystems. You might recall the invective to which fsck in ReiserFS was exposed.
If you have a network filesystem, the subject of fsck is significantly more complex than local filesystems that exist only on a single disk. On the one hand, a Ceph fsck needs to check whether the stored metadata are correct; on the other hand, it needs to be able to check the integrity of all objects belonging to a file on request by the admin. This is the only way ultimately to ensure that the admin can download every single file from the cluster. If recovery is no longer possible, the cluster at least needs to notify the admin to get the backups out of the drawer.
Jewel will include a couple of retrofits in terms of a filesystem check: Greg Farnum, who worked on Ceph back in the Inktank era, has taken up the gauntlet. Together with John Spray, he partly consolidated and revised the existing approaches for the Jewel version of Ceph. The result is not a monolithic fsck tool, but a series of programs that are suitable for different purposes: cephfs-data-scan can rebuild the pool of metadata in CephFS, even if it is completely lost.
The concept of the damage table is also new: The idea is for the CephFS repair tools to use the table to “remember” where they discovered errors in the filesystem. The Ceph developers are looking to avoid the situation in which clients keeping on trying to read the same defective data. The table also acts as the starting point for subsequent repair attempts. Finally, the damage table also helps improve the stability of the system: If the Ceph tools find a consistency problem in a CephFS-specific subtree, they mark the individual subtree as defective in the future. Previously, it was only possible to circumnavigate larger areas of the filesystem.
One thing is clear: The CephFS changes in Jewel make this product significantly more mature and create a real alternative to GlusterFS. Although the first stable version of CephFS will still contain some bugs, The Ceph developers in recent months will definitely have made sure that any existing bugs will not cause loss of data. If you want to use CephFS in the scope of a Red Hat or Inktank support package, Jewel is likely to give you the opportunity to do just that, because Jewel will be a long-term support release.
Latency Issues in Focus
The second significant Ceph change concerns the object store itself: The developers have introduced a new storage back end for the storage cluster’s data tanks, the OSD. It will make Ceph much faster, especially for small write operations.
However, if you want Ceph to use a block device, you still need a filesystem on the hard disk or SSD. After all, Ceph stores objects on the OSDs using a special naming scheme but does not handle the management of the block device itself thus far. The filesystem is thus necessary for the respective ceph-osd daemon to be able to use a disk at all.
In the course of its history, Ceph has recommended several filesystems for the task. Initially, the developers expected that Btrfs would soon be ready for production use. They even designed many features for Ceph explicitly with a view to using Btrfs. When it became clear that it would take a while for Btrfs to reach the production stage, Inktank changed its own recommendation: Instead of Btrfs, it was assumed that XFS would work best on Ceph OSDs (Figure 2).
 Figure 2: XFS is the Ceph developers’ current recommendation for OSDs. However, BlueStore is likely to be the choice in the future.
Figure 2: XFS is the Ceph developers’ current recommendation for OSDs. However, BlueStore is likely to be the choice in the future.
Either way, Weil realized at a fairly early stage that a POSIX-compliant filesystem as the basis for OSDs is a bad idea, because most guarantees that POSIX offers for filesystems are virtually meaningless for an object store, such as parallel access to individual files, which does not occur in the Ceph cluster because an OSD is only ever managed by one OSD daemon, and the daemon takes care of requests in sequential order.
The fact that CephFS does not need most POSIX functions is of little interest to a Btrfs or XFS filesystem residing on an OSD, though. Some overhead thus arises when writing to OSDs in Ceph because filesystems spend time ensuring POSIX compliance in the background. In terms of throughput, that is indeed negligible, but superfluous checks of this type do hurt, especially in terms of latency. Accordingly, many admins throw their hands up in horror if asked to run a VM, say, with MySQL on a Ceph RBD (RADOS block device) volume. A comparison with quick fixes like Fusion-io is ruled out by default, but Ceph even spectacularly exceeds Ethernet latency.
BlueStore to the Rescue
The Ceph developers’ approach permanently eliminates the problem of POSIX filesystems with BlueStore. The approach comprises several parts: BlueFS is a rudimentary filesystem that has just enough features to operate a disk as an OSD. The second part is a RocksDB key-value store, in which OSDs store the required information.
Because the POSIX layer is eliminated, BlueStore should be vastly superior to its colleagues XFS and Btrfs, especially for small write operations. The Ceph developers substantiate this claim with meaningful performance statistics, showing that BlueStore offers clear advantages in a direct comparison.
BlueStore should already be usable as the OSD back end in the Jewel version. However, the function is still tagged “experimental” in Jewel – the developers thus advise against production use. Never mind: The mere fact that the developers understand the latency problem and already started eliminating it will be enough to make many admins happy. In addition to BlueStore, a number of further changes in Jewel should have a positive effect on both throughput and latency, all told.
The Eternal Stepchild: Calamari
The established storage vendors are successful because they deliver their storage systems with simple GUIs that offer easy management options. Because an object store with dozens of nodes is no less complex than typical SAN storage, Ceph admins would usually expect a similarly convenient graphical interface.
Inktank itself responded several years ago to constantly recurring requests for a GUI and tossed Calamari onto the market. Originally, Calamari was a proprietary add-on to Ceph support contracts, but shortly after the acquisition of Inktank, Red Hat converted Calamari into an open source product and invited the community to participate in the development – with moderate success: Calamari meets with skepticism from both admins and developers for several reasons.
Calamari does not see itself only as a GUI, but as a complete monitoring tool for Ceph cluster performance. For example, it raises the alarm when OSDs fail in a Ceph cluster, and that is precisely one good reason that Calamari is not a resounding success thus far: It is quite complicated to persuade Calamari to cooperate at all. For example, the software relies on SaltStack, which it wants to set up itself. If you already have a configuration management tool, you cannot meaningfully integrate Calamari with it and are forced to run two automation tools at the same time.
In terms of functionality, Calamari is not without fault. The program offers visual interfaces for all major Ceph operations – for example, the CRUSH map that controls the placement of individual objects in Ceph is configurable via Calamari – but the Calamari interface is less than intuitive and requires much prior knowledge if you expect a working Ceph cluster in the end.
Help On the Way
SUSE also noticed that Calamari is hardly suitable for mass deployment. Especially in Europe, SUSE was a Ceph pioneer. Long before Red Hat acquired Inktank, SUSE was experimenting with the object store. Although SUSE has enough developers to build a new GUI, they instead decided to cooperate with it-novum, the company behind openATTIC, a kind of appliance solution that supports open-source-based storage management.
For some time, the openATTIC beta branch has contained a plugin that can be used for basic Ceph cluster management, which is exactly the part of openATTIC in which SUSE is interested (Figure 3). In the future collaboration with it-novum, SUSE is looking to improve the Ceph plugin for openATTIC and extend it to include additional features. In the long term, the idea is to build a genuine competitor to Calamari. If you want, you can take a closer look at the Ceph functions in openATTIC.
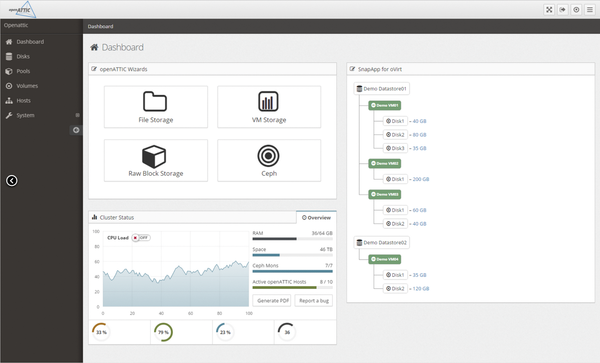 Figure 3: openATTIC is setting out to become the new GUI of choice for Ceph administration, thanks to a collaboration between SUSE and it-novum.
Figure 3: openATTIC is setting out to become the new GUI of choice for Ceph administration, thanks to a collaboration between SUSE and it-novum.
When the initial results of the collaboration between SUSE and it-novum can be expected is unknown; this is one topic not covered in the press releases. However, the two companies are unlikely to take long to present the initial results, because there is clearly genuine demand right now, and openATTIC provides the perfect foundation.
Disaster Recovery
In the unanimous opinion of all admins with experience of the product, one of the biggest drawbacks of Ceph is the lack of support for asynchronous replication, which is necessary to build a disaster recovery setup. A Ceph cluster could be set up to span multiple data centers if the connections between the sites are fast enough.
Then, however, the latency problem raises its ugly head again: In Ceph, a client receives confirmation of a successful write only after the specified object has been copied to the number of OSDs defined by the replication policy. Even really good data center links have a higher latency than write access to filesystems can tolerate. If you want to build a multi-data-center Ceph in this way, you have to accept the very high latencies for write access to the virtual disk on the client side.
Currently you have several approaches to solving the problem in Ceph. Replication between two clusters of Ceph with the RADOS federated gateway (Figure 4) is suitable for classic storage services in the style of Dropbox. An agent part of the RADOS gateway synchronizes data between the pools of two RADOS clusters at regular intervals. The only drawback: The solution is not suitable for RBDs, but it is exactly these devices that are regularly used in OpenStack installations.
 Figure 4: The RADOS gateway offers Dropbox-like services for Ceph. In Jewel, the developers have improved off-site replication in the RADOS gateway.
Figure 4: The RADOS gateway offers Dropbox-like services for Ceph. In Jewel, the developers have improved off-site replication in the RADOS gateway.
A different solution is thus needed, and the developers laid down the basis for it in the Jewel version of Ceph: The RBD driver will have a journal in future in which the incoming write operations are noted. You can thus track for each RBD which changes are taking place. This eliminates the need for synchronous replication for links between data centers: If the content of the journal is regularly replicated between sites, a consistent state can always be ensured on both sides of the link.
If worst comes to worst, it’s possible that not all the writes from the active data center reach the standby data center if the former is hit by a meteorite. However, the provider will probably prefer this possibility to day-long failure of all services.
Incidentally, the developers have again performed a major upgrade in Jewel on the previously mentioned multiple-site replication feature in the RADOS gateway. The setup can now be run in active-active mode. The agent used thus far will, in future, be an immediate part of the RADOS gateway itself, thus removing the need to run an additional service.
Sys Admin Everyday Life
In addition to the major construction sites, some minor changes in the Jewel release also attracted attention. Although unit files for operation with systemd have officially been around in Ceph since mid-2014, the developers enhanced them again for Jewel. A unit file now exists for each Ceph service; individual instances such as OSDs can be started or stopped in a targeted way on systems with systemd.
The same applies for integration with the SELinux security framework. Ubuntu users who would rather rely on the Ubuntu default AppArmor will need to put in some manual work if things go wrong. The developers have also looked into the topic of security for Jewel: Ceph uses its own authentication system, CephX, when users or individual services such as OSDs, MDSs, or MONs want to log in on the cluster (Figure 5).
 Figure 5: CephX will be better protected in future against brute force attacks. However, it is unclear whether this function will make Jewel freeze.
Figure 5: CephX will be better protected in future against brute force attacks. However, it is unclear whether this function will make Jewel freeze.
For protection against brute force attacks, a client who tries to log in on the cluster with false credentials too often will be added automatically to a black list. Ceph then refuses all further logon attempts, regardless of the validity of the username and password combination. When this issue went to press, this function still not not appear in Jewel.
Conclusions
In the Jewel release, the Ceph developers have tackled many of the important problems that previously made Ceph unusable in some scenarios. CephFS in particular as a stable release should open up a new market segment and make Ceph interesting as a substitute for cumbersome NFS installations. If SUSE and it-novum fulfill their promises, managing Ceph via a GUI will be significantly easier sometime soon. Replication across data centers makes Ceph usable for disaster recovery.
All of these features will make life difficult for GlusterFS: Although Red Hat is thus far committed to its product, it is unlikely to continue investing money in the development of two projects in the medium term, given that Ceph can replace GlusterFS and offer more functionality. Ceph is basically staking its universal claim in the software-defined storage market with the changes for Jewel and is on its way to becoming the universal storage solution.
The Author
Martin Gerhard Loschwitz works as a cloud architect for SysEleven GmbH, where he focuses on the topics of OpenStack, distributed storage, and Puppet. In his spare time, he maintains Pacemaker for Debian.
Related content
-
Ceph object store innovations
 The Ceph object store remains a project in transition: The developers announced a new GUI, a new storage back end, and CephFS stability in the just released Ceph c10.2.x, Jewel.
The Ceph object store remains a project in transition: The developers announced a new GUI, a new storage back end, and CephFS stability in the just released Ceph c10.2.x, Jewel. -
What's new in Ceph
 Ceph and its core component RADOS have recently undergone a number of technical and organizational changes. We take a closer look at the benefits that the move to containers, the new setup, and other feature improvements offer.
Ceph and its core component RADOS have recently undergone a number of technical and organizational changes. We take a closer look at the benefits that the move to containers, the new setup, and other feature improvements offer. -
Management improvements, memory scaling, and EOL for FileStore
 Ceph developers focus on getting rid of historic clutter and adding new features for improved performance and built-in automation.
Ceph developers focus on getting rid of historic clutter and adding new features for improved performance and built-in automation. -
Optimally combine Kubernetes and Ceph with Rook
 Ceph distributed storage and Kubernetes container orchestration come together with Rook.
Ceph distributed storage and Kubernetes container orchestration come together with Rook. -
CephX Encryption

We look at the new features in Ceph version 0.56, alias “Bobtail,” talk about who would benefit from CephX Ceph encryption, and show you how a Ceph Cluster can be used as a replacement for classic block storage in virtual environments.