« Previous 1 2 3 Next »
Getting the Most from Your Cores
Listing 1: Collect and Plot CPU Stats
#!/usr/bin/python
import time
try:
import psutil
except ImportError:
print "Cannot import psutil module - this is needed for this application.";
print "Exiting..."
sys.exit();
# end if
try:
import matplotlib.pyplot as plt; # Needed for plots
except:
print "Cannot import matplotlib module - this is needed for this application.";
print "Exiting..."
sys.exit();
# end if
def column(matrix, i):
return [row[i] for row in matrix]
# end def
# ===================
# Main Python section
# ===================
#
if __name__ == '__main__':
# Main dictionary
d = {};
# define interval and add to dictionary
interv = 0.5;
d['interval'] = interv;
# Number of cores:
N = psutil.cpu_count();
d['NCPUS'] = N;
cpu_percent = [];
epoch_list = [];
for x in range(140): # hard coded as an example
cpu_percent_local = [];
epoch_list.append(time.time());
cpu_percent_local=psutil.cpu_percent(interval=interv,percpu=True);
cpu_percent.append(cpu_percent_local);
# end for
# Normalize epoch to beginning
epoch_list[:] = [x - epoch_list[0] for x in epoch_list];
# Plots
for i in range(N):
A = column(cpu_percent, i);
plt.plot(epoch_list, A);
# end if
plt.xlabel('Time (seconds)');
plt.ylabel('CPU Percentage');
plt.show();
# end ifExample
The point of the code is not to create another tool but to implement it when running example programs to illustrate how CPU utilization stats can be gathered. The programs used in this example are the NAS Parallel Benchmarks (NPB). Version 3.3.1 using OpenMP was used for the example. Only the FT test (discrete 3D fast Fourier transform, all-to-all communication) was run and the Class B “size” standard test (4x size increase going from one class to the next) was used on a laptop with 8GB of memory using two cores (OMP_NUM_THREADS=2 ).
Initial tests showed that the application finished in a bit less than 60 seconds. With an interval of 0.5 seconds between statistics, 140 function calls gathered the statistics (this is hard-coded in the example code).
To better visualize the CPU utilization statistics, a “pause” is used at the beginning so that CPU utilization is captured on a relatively quiet system. Also, the application finishes a little faster than 60 seconds, so the CPU utilization stats capture the system “quieting down” after the run.
One important thing to note is that the application was run on a system that was running X windows and a few other applications and daemons; therefore, the system was not completely quiet (i.e., 0% CPU utilization) when the application was not running.
Figure 2 is the plot of CPU utilization versus time in seconds (relative to the beginning of gathering the statistics).
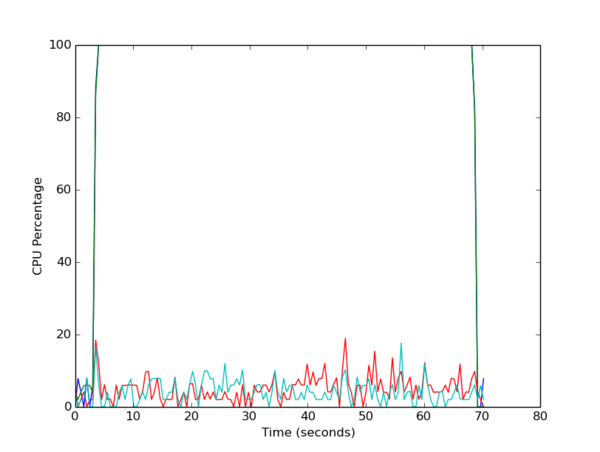 Figure 2: CPU utilization while running NPB FT Class B with two cores.
Figure 2: CPU utilization while running NPB FT Class B with two cores.
This plot doesn’t have a legend, so it might be difficult to see the CPU utilization of all four cores. However, at the bottom of the plot are two lines representing CPU utilization of two of the four cores. For these two cores, CPU utilization while the NPB FT Class B application is running is quite low (<20%). However, for the other two cores, the CPU utilization quickly goes to 100% and stays there most of the time the statistics were gathered, although in this graph, it only looks like one line.
For this particular example, the application was not “pinned” to any cores, which means the processes were not tied to a specific core in the processor and were not moved by the kernel. If processes are not pinned to a core, it is possible for the kernel to move them between cores. In that case, the CPU utilization plots would show a specific core at a high percentage that then drops low, while the CPU utilization on a different core rises dramatically.
For this example, the kernel did not move any processes, most likely because two cores are available for running daemons or any other process that needs CPU cycles. If the application had been run with four threads, the plot would have been more chaotic because the kernel would have had to move or pause processes to accommodate daemons or other processes when they started.
« Previous 1 2 3 Next »
Related content
-
Getting the most from your cores
 CPU utilization metrics tell you how well your applications are using your processing resources.
CPU utilization metrics tell you how well your applications are using your processing resources. -
Monitoring Storage with iostat

One tool you can use to monitor the performance of storage devices is iostat . In this article, we talk a bit about iostat, introduce a Python script that takes iostat data and creates an HTML report with charts, and look at a simple example of using iostat to examine storage device behavior while running IOzone.
-
Processor and Memory Metrics

One goal of HPC administration is effective monitoring of clusters. In this article, we talk about writing code that measures processor and memory metrics on each node.
-
Remora – Resource Monitoring for Users

Remora provides per-node and per-job resource utilization data that can be used to understand how an application performs on the system through a combination of profiling and system monitoring.
-
A Bash-based monitoring tool
 In a sea of top-like tools, bashtop impresses with an easy-to-use and efficient interface.
In a sea of top-like tools, bashtop impresses with an easy-to-use and efficient interface.