Successful automatic service detection
The term “autodiscovery” sounds promising and raises expectations: At the press of a button, a computer is supposed to piece together everything it needs from the web and then configure the appropriate monitoring system. Subsequently, all it has to do is sound an alarm if an incident occurs. However, things are different in practice. Neither Nagios nor Icinga has an autodiscovery function. However, if you want this functionality, you can take advantage of many useful tools available. In this article, I describe how.
Although often no Configuration Management Database (CMDB) or similar tool is provided for managing configuration settings, other sources of information are available. These could be lists of server hardware, DHCP and DNS entries, or inventory information from an Active Directory.
Tools from the manufacturer also frequently manage certain hardware, and this information often can be exported easily. For example, you can import the data from Cisco Works with the CLI utility or access the underlying database directly via JDBC.
The configuration of Nagios or Icinga can be divided into various files and subfolders. In one directory, for example, configuration files can be maintained manually, with automatically generated configurations kept in another folder. In this respect, configuration files are a very flexible medium.
Automatic Monitoring
If you have insufficient – or even no – information about the environment to be monitored, autodiscovery is a common way to take a first inventory of the infrastructure. Almost all autodiscovery tools work according to the same pattern: The admin specifies an IP range whose addresses are then scanned to find open ports and thus identify services running on them. SNMP queries also provide detailed information about components and status, especially for networks and hardware.
Using Nmap
Nmap [http://nmap.org] stands for Network Mapper and is the tool of choice for the scanning networks. Besides executing plain portscans, it also tries to identify the operating system with OS fingerprinting. The following command executes a simple port scan on a chosen system:
nmap -v -A www.haribo.de
An abridged version of the output from this command is shown in Listing 1.
Listing 1: Nmap Command
root@sandbox:~# nmap -v -A www.haribo.de ... Host www2.haribo.com (213.185.81.67) is up (0.011s latency). Interesting ports on www2.haribo.com (213.185.81.67): Not shown: 995 closed ports PORT STATE SERVICE VERSION 21/tcp open ftp? 22/tcp open tcpwrapped 80/tcp open http Apache httpd |_ html-title: Requested resource was http://www2.haribo.com/?locale=de-DE and no page was returned. 443/tcp open ssl/http Apache httpd |_ html-title: Requested resource was http://www2.haribo.com/?locale=de-DE and no page was returned. 3306/tcp open tcpwrapped
It shows the standard ports are open as FTP, SSH, HTTP, and MySQL. One of the most powerful features of Nmap is the Nmap Scripting Engine (NSE), which lets you add little snippets of Lua program code to the basic functions to find out more details about specific services.
Finished scripts for a wide variety of applications and protocols are already available and grouped into categories in the online Nmap archives, so everything needed for daily use is already on board. The use of snippets also lets you investigate which feature sets have been activated, as well as probe their safety.
Subsequently, the information gained must be translated into the Nagios or Icinga format, which is child’s play thanks to another script already provided: nmap2nagios-ng .
Once a certain range has been scanned – for example, with
nmap -sS -O -oX mynet.xml 10.10.0.0/24
and the results have been saved in mynet.xml , the XML file can be used to generate a valid Nagios/Icinga configuration:
./nmap2nagios-ng.pl -i -e -r mynet.xml -o hostconfig.cfg
The default settings used for thresholds, contact groups, host groups, and so on can be customized beforehand in the corresponding conf file. Templates for new services can also be saved in the config file to teach the Perl script new template allocations. Finally, hostconfig.cfg just needs to be copied to the correct directory, and everything is ready to go.
Client-Based Discovery
After such a network-based inventory of the infrastructure, system monitoring can, of course, still be refined. Depending on the operating system, you can do this, for example, by using SNMP or by installing local agents.
As an example of an agent, the well-known Nagios solution check_mk offers the ability to search for existing services on the host and monitor them. Such agents are available for most popular Linux platforms and for Windows. For use under Windows, NSClient++ is also useful, and its standard module can be activated on any client. A special feature of NSClient++ is the ability to gather the results by itself and send them as passive results to the monitoring server.
Installing individual clients can be problematic, especially considering security and update aspects. Quite often, only packages from the respective distribution are allowed. In this case, it can help to extend the local snmpd and use check_snmp_extend . The underlying idea is simple and yet ingenious: New commands for requesting monitoring information are entered in the snmpd.conf file, which can then be executed with a normal plugin call if the correct SNMP community is specified.
The following example illustrates the monitoring of a software-based RAID array using the given entry in the snmpd.conf file:
extend raid-md0 /usr/local/bin/check_raid.pl –device=md0
After a restart of snmpd , the query is available immediately and can be used with the following Nagios or Icinga snippet:
define service{
use generic-service
host_name snmp_server
service_description SOFTRAID status
check_command check_snmp_extension!raid-md0
}If you distribute the corresponding snmpd.conf extensions on the clients as a package distribution, or with a configuration manager, then the information can be queried by an Nmap extension and automatically added to the configuration.
By Hand
In all the scenarios described here, an inventory was taken of the complete environment, and all findings were included in the monitoring. A disadvantage of this procedure is that the multitude of services can be quite intimidating and the really important components difficult to identify.
A different, manual approach is to create your configuration and setup on the basis of the existing business processes. In this case, the inventory does not begin by documenting all components, but rather with a detailed analysis of business processes. These processes can include your mail solution, SAP system, or even your own Active Directory domain. After establishing appropriate priorities, you can begin to break down the process to identify its individual parts.
Consider the example of the central exchange cluster again (Figure 1).
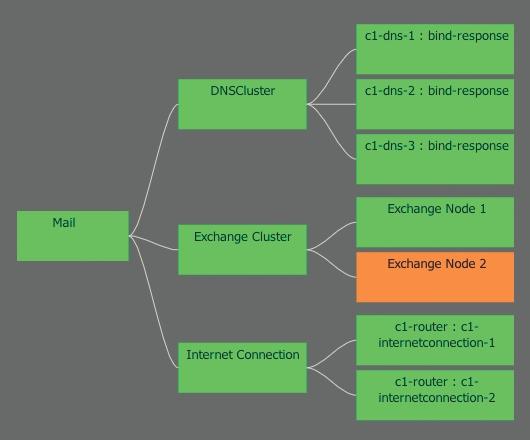 Figure 1: A schematic representation of the service dependencies in a mail cluster.
Figure 1: A schematic representation of the service dependencies in a mail cluster.
To provide the mail service, various subsystems are necessary, which also have their own dependencies. By documenting such a service structure, these dependencies can be identified and the individual subsystems can help document other processes. For example, the DNS cluster is most likely of great importance for other subprocesses and must not be defined again.
In this way, the hosts and services involved can be configured and then monitored. Bit by bit, a schemata of your environment develops, which usually leads to a better understanding of your IT environment than would be possible with a patchwork of independent services. This approach is also a helpful for auditing and optimizing an existing monitoring environment.
The Downside
The big problem with automatic analysis of an environment is that it follows the principle of quantity, not quality. A quick look at a monitoring system can usually show whether the process is being done systematically or if simply everything is being monitored. When trouble ensues, admins might just stop all unfamiliar services or disable the warnings. As a result, no one really knows exactly what, how, or why things are being monitored.
Another problem is lifecycle management in such an environment. If a monitoring setup does not go through the classic stages of development, test/QA, and production, the consequences are easy to foresee: Alarms will be triggered either by everything or by nothing or by the wrong things. Different priorities will be hard to define, admins will become demotivated, and in the end, SMS alerts will be consistently ignored.
A Better Way
If you just begin to think about your existing infrastructure when you start setting up your monitoring system, then a lot has already gone wrong. Although maintaining a CMDB and introducing configuration management can take a lot of effort, the process is still a worthwhile investment. Then, the hardware and software configuration of all systems is known before the devices are installed in the rack, and an intelligent monitoring system can be set up in a logical way. Consequently, suitable checks can be deployed and transferred to the monitoring system parallel to installation of the server and the monitoring clients and agents.
Much more important to the outcome, however, is the continuous processing of events and errors, because only then is meaningful problem management possible.
If services are generated automatically and information transmitted properly, then the resulting errors and alarms can later be traced back to the object in question. This way, a configuration item for a SAN volume becomes a SAN check with a custom variable. And, in the event of an error, this in turn becomes an alert that uniquely identifies the component. Then, it’s a small step from the alert to calling up the matching CMDB information.
Nagios and Icinga are two excellent monitoring systems that are not only helpful for monitoring servers, switches, or storage systems, but also for taking inventory of a system. For example, with only minor modifications to standard tests, Nagios and Icinga can both retrieve serial numbers, the number of processors, RAM modules, and hard drives, along with their respective usage data. The data obtained in this way can be helpful for later evaluations or can simply flow back into the CMDB, saving much repetitive maintenance.
The Author
Bernd Erk is Managing Director of NETWAYS GmbH in Nuremberg, Germany, which has been specializing in Open Source Systems Management for more than 15 years.
Related content
-
Monitoring network computers with the Icinga Nagios fork
A network monitor supports administrators by displaying a full set of critical information at a central location and alerting in case of trouble.
-
Network monitoring with Icinga and Raspberry Pi
 Icinga on the Raspberry Pi monitors your network, letting you see the good, the bad, and the ugly, so you can address problems proactively.
Icinga on the Raspberry Pi monitors your network, letting you see the good, the bad, and the ugly, so you can address problems proactively. -
Versatile network and system monitoring
 The LibreNMS open source monitoring environment, unlike its predecessor Observium, comes through the back door at no cost, with auto-discovery, alerting, the ability to scale even in very large environments with many devices, and flexible dashboards and widgets for special views.
The LibreNMS open source monitoring environment, unlike its predecessor Observium, comes through the back door at no cost, with auto-discovery, alerting, the ability to scale even in very large environments with many devices, and flexible dashboards and widgets for special views. -
Monitoring and service discovery with Consul
 When dozens of new services and VMs emerge and disappear every day in dynamic cloud environments, conventional monitoring provides false alarms, not operational security.
When dozens of new services and VMs emerge and disappear every day in dynamic cloud environments, conventional monitoring provides false alarms, not operational security. -
Monitoring with collectd 4.3
 Collectd 4.3 is a comprehensive monitoring tool with a removable plugin architecture.
Collectd 4.3 is a comprehensive monitoring tool with a removable plugin architecture.