
Lead Image © J.R. Bale, 123RF.com
Managing Linux Memory
Memory Hogs
Modern software such as large databases run on Linux machines that often provide hundreds of gigabytes of RAM. Systems that need to run the SAP database (HANA) in a production environment, for example, can have up to 4TB of main memory [1]. Given these sizes, you might expect that storage-related bottlenecks no longer play a role, but the experience of users and manufacturers with such software solutions shows that this problem is not yet completely solved and still needs attention.
Even well tuned applications can lose performance because of insufficient memory being available under certain conditions. The standard procedure in such situations – more RAM – sometimes does not solve the problem. In this article, we first describe the problem in more detail, analyze the background, and then test solutions.
Memory and Disk Hogs
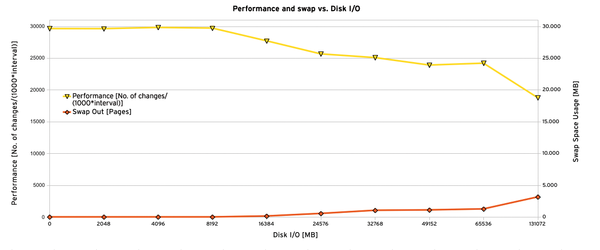
Many critical computer systems, such as SAP application servers or databases, primarily require CPU and main memory. Disk access is rare and optimized. Parallel copying of large files should thus have little effect on such applications because they require different resources.
Figure 1 shows, however, that this assumption is not true. The diagram demonstrates how the (synthetic) throughput of the SAP application server changes if disk-based operations also occur in parallel. As a 100 percent reference value, we also performed a test cycle without parallel disk access. In the next test runs, the dd command writes a file of the specified size on the hard disk.
{kind=link}
...
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
A swap space primer
 What happens when RAM runs out?
What happens when RAM runs out? -
Optimize and manage Linux-based Azure VMs
 Master advanced configuration techniques for Azure virtual machines on Linux with a focus on optimizing performance by applying system tweaks, managing storage solutions, and automating monitoring tasks.
Master advanced configuration techniques for Azure virtual machines on Linux with a focus on optimizing performance by applying system tweaks, managing storage solutions, and automating monitoring tasks. -
Tuning Your Filesystem’s Cache
Keeping your key files in RAM reduces latency and makes response time more predictable.
-
Tuning your filesystem's cache
 Keeping your key files in RAM reduces latency and makes response time more predictable.
Keeping your key files in RAM reduces latency and makes response time more predictable. -
Processor and Memory Metrics

One goal of HPC administration is effective monitoring of clusters. In this article, we talk about writing code that measures processor and memory metrics on each node.