« Previous 1 2 3 Next »
Linux Storage Stack
Stacking Up
I/O Scheduler
The traditional I/O schedulers NOOP, Deadline, and CFQ are certainly the most important schedulers used in current Linux distributions. Even the newest distributions, like Debian 8, are still in kernel version 3.16, which for blk-mq, only supports a virtual driver (e.g., virtio-blk for KVM guests) and a "real" driver (mtip32xx for the Micron RealSSD PCIe) in addition to a test driver (null_blk).
Traditional I/O schedulers work with the following two queues:
- Request queue: In this queue, the requests used by processes are collected, possibly merged, and sorted by the scheduler based on the scheduling algorithm. The schedulers use different approaches to deal with individual requests and to pass them to the device driver.
- Dispatch queue: This queue includes organized requests that are ready for processing on the storage device. It is managed by the device driver.
NOOP is a simple scheduler that collects all I/O requests in a FIFO queue (Figure 1, left). It performs a merge to optimize the requests and thus reduces unnecessary access times. However, it doesn't sort the requests. The device driver also processes the dispatch queue using FIFO principles. The NOOP scheduler doesn't have any configuration options (tunables).
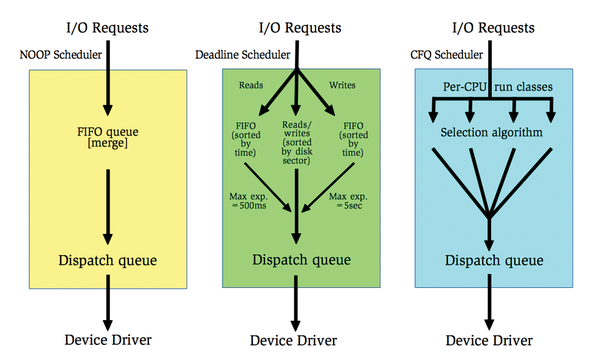 Figure 1: The Deadline scheduler (center) attempts to prevent requests from "starvation" using two queues sorted by expiration time, whereas the CFQ scheduler (right) uses priority or scheduling classes.
Figure 1: The Deadline scheduler (center) attempts to prevent requests from "starvation" using two queues sorted by expiration time, whereas the CFQ scheduler (right) uses priority or scheduling classes.
The Deadline scheduler (Figure 1, center) tries to save requests from "starvation." For this purpose, it takes note of an expiration time for each request and pushes it into respective read and write queues sorted by time (deadline queues). The Deadline scheduler gives preference to read over write accesses (the default is 500ms for reads compared with 5s for writes). A "sorted queue" keeps all requests sorted by disk sector, to minimize seek time, and feeds requests to the dispatch queue unless a request from one of the deadline queues times out. An attempt is therefore made to guarantee a predictable service start time. This scheme is advantageous because read accesses are mainly issued synchronously (blocking) and write accesses asynchronously (non-blocking).
The CFQ (Completely Fair Queuing) scheduler (Figure 1, right) is the default scheduler for the Linux kernel, although some distributions use the Deadline scheduler instead. CFQ sets the following objectives:
- Fair distribution of the available I/O bandwidth to all processes of the same priority class via time slices. "Fair" refers to the length of the time slots, not the bandwidth; that is, a process with sequential write access will obtain a higher bandwidth than a process with randomly distributed write access in the same time slot).
- The possibility of dividing processes in priority or scheduling classes (e.g., via
ionice). - Periodic processing of process queues for distributing latency. The time slots allow a high bandwidth for processes that can initiate many requests in its slot.
Beyond the Scheduler
Blk-mq is a new framework for the Linux block layer. It was introduced with Linux kernel 3.13 and completed in Linux kernel 3.16. Blk-mq allows more than 15 million IOPS on eight-socket servers for high-performance flash devices (e.g., PCIe SSDs), although single-socket and dual-socket servers also benefit from the new subsystem [1]. A device is then controlled via blk-mq if its device drivers are based on blk-mq.
Blk-mq provides device drivers with the basic functions for distributing I/O requests to multiple queues. The tasks are distributed with blk-mq to multiple threads and thus to multiple CPU cores. Blk-mq-compatible drivers, for their part, inform the blk-mq module how many parallel hardware queues a device supports.
Blk-mq-based device drivers bypass the previous Linux I/O scheduler. Some drivers did that in the past without blk-mq (ioMemory-vsl, NVMe, mtip32xx); however, as BIO-based drivers, they had to provide a lot of generic functions themselves. These types of drivers are on the way out and are gradually being reprogrammed to take the easier path via blk-mq (Table 1).
Table 1
Driver with blk-mq Support
| Driver | Device Name | Supported Devices | Kernel Support |
|---|---|---|---|
| null_blk | /dev/nullb*
|
None (test driver) | 3.13 |
| virtio-blk | /dev/vd*
|
Virtual guest driver (e.g., in KVM) | 3.13 |
| mtip32xx | /dev/rssd*
|
Micron RealSSD PCIe | 3.16 |
| SCSI (scsi-mq) | /dev/sd*
|
SATA, SAS HDDs and SSDs, RAID controller, FC HBAs, etc. | 3.17 |
| NVMe | /dev/nvme*
|
NVMe SSDs (e.g., Intel SSD DC P3600 and P3700 series | 3.19 |
| rbd | /dev/rdb*
|
RADOS block device (Ceph) | 4.0 |
| ubi/block | /dev/ubiblock*
|
RADOS block device (Ceph) | 4.0 |
| loop | /dev/loop*
|
Loopback device | 4.0 |
SCSI Layer
From the block layer to the respective hardware drivers for driving some storage devices (e.g., for new NVMe flash memory in the NMVe driver, which has used blk-mq since kernel version 3.19). However, the path first leads to the SCSI midlayer for all storage devices that are addressed via a device file like /dev/sd*, /dev/sr*, or /dev/st*, which doesn't addressed just SCSI or SAS devices, but also SATA storage, RAID controllers, and FC HBAs.
Thanks to scsi-mq , it is possible to address such devices starting with blk-mq from Linux kernel 3.17. However, this path is disabled by default at the moment. Christoph Hellwig, the main developer of scsi-mq, does hope to have scsi-mq activated by default in future Linux versions in order to remove the old code path completely at a later date [2].
SCSI low-level drivers at the lower end of the storage stack are in fact the drivers that address the respective hardware components. They range from the general Libata drivers for controlling (S)ATA components via RAID controller drivers, such as megaraid_sas (Avago Technologies MegaRAID, formerly LSI) or AACRAID (Adaptec), to (FC) HBA drivers such as qla2xxx (QLogic), to the paravirtualized drivers virtio_scsi and vmw_pvscsi. For these drivers to deploy multiple parallel hardware queues via blk-mq/scsi-mq in the future, each driver must be adjusted accordingly.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Storage protocols for block, file, and object storage
 The future of flexible, performant, and highly available storage.
The future of flexible, performant, and highly available storage. -
NVDIMM Persistent Memory

Non-volatile dual in-line memory modules will provide storage as fast as RAM and keep its content through a reboot. The Linux kernel is already geared to handle the new technology and can even serve the modules up as block devices.
-
NVDIMM and the Linux kernel
 Non-volatile dual in-line memory modules will provide storage as fast as RAM and keep its content through a reboot. The Linux kernel is already geared to handle the new technology and can even serve the modules up as block devices.
Non-volatile dual in-line memory modules will provide storage as fast as RAM and keep its content through a reboot. The Linux kernel is already geared to handle the new technology and can even serve the modules up as block devices. -
Fundamentals of I/O benchmarking
 Admins often want to know how to measure the performance of a specific solution. Care is needed, however: Where there are benchmarks, there are pitfalls.
Admins often want to know how to measure the performance of a specific solution. Care is needed, however: Where there are benchmarks, there are pitfalls. -
Linux I/O Schedulers
 The Linux kernel has several I/O schedulers that can greatly influence performance. We take a quick look at I/O scheduler concepts and the options that exist within Linux.
The Linux kernel has several I/O schedulers that can greatly influence performance. We take a quick look at I/O scheduler concepts and the options that exist within Linux.