« Previous 1 2 3 4 Next »
Coordinating distributed systems with ZooKeeper
Relaxed in the Zoo
Admins who manage the compute cluster with a specific number of nodes and high availability (HA) requests will at some point need a central management tool that, for example, takes care of the naming, grouping, or configurations of the menagerie. Thanks to ZooKeeper [1], which is available under the Apache 2.0 license, not every cluster has to provide a synchronization service itself. The software can be mounted in existing systems – for example, in a Hadoop cluster.
Server and Clients
A ZooKeeper server keeps track of the status of all system nodes. Larger decentralized systems and multiple replicating servers can be used (Figure 1). They then synchronize node status information among themselves, making sure that system tasks run in a fixed order and that no inconsistencies occur.
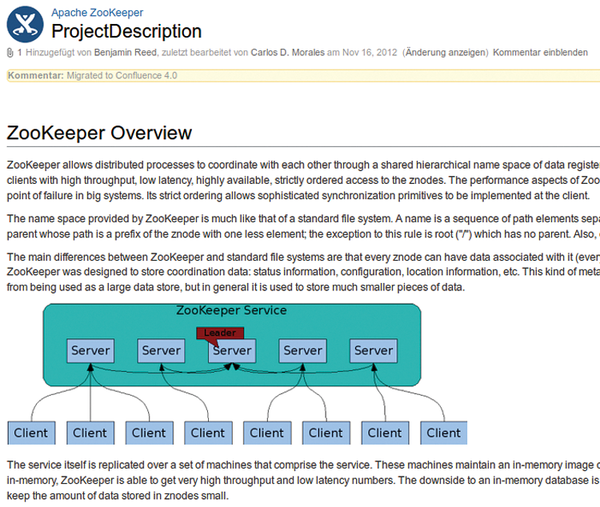 Figure 1: ZooKeeper takes care of communication between nodes in a cluster.
Figure 1: ZooKeeper takes care of communication between nodes in a cluster.
You can imagine ZooKeeper as a distributed filesystem, because it organizes its information analogously to a filesystem. It is headed by a root directory (/). ZooKeeper nodes, or znodes
, are maintained below this; the name is intended to distinguish them from computer nodes.
A znode acts both as a binary file and a directory for more znodes,
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
The advantages of configuration management tools
 Etcd, ZooKeeper, Consul, and similar programs are currently the subject of heated debate in the world of configuration management. We investigate the problems they seek to solve and promises they make.
Etcd, ZooKeeper, Consul, and similar programs are currently the subject of heated debate in the world of configuration management. We investigate the problems they seek to solve and promises they make. -
Mesos compute cluster for data centers
 The Apache Mesos free cluster framework is a powerful tool for distributed computing in data centers.
The Apache Mesos free cluster framework is a powerful tool for distributed computing in data centers. -
Apache Storm
 We take you through the installation of a Storm cluster and discuss how to create your own topologies.
We take you through the installation of a Storm cluster and discuss how to create your own topologies. -
Verifying your configuration
 Automated acceptance testing is a powerful tool for catching problems related to misconfiguration. We'll show you how to implement your own acceptance testing environment with a free tool called goss.
Automated acceptance testing is a powerful tool for catching problems related to misconfiguration. We'll show you how to implement your own acceptance testing environment with a free tool called goss. -
A watchdog for every modern *ix server
 Monit is a lightweight, performant, and seasoned solution that you can drop into old running servers or bake into new servers for full monitoring and proactive healing.
Monit is a lightweight, performant, and seasoned solution that you can drop into old running servers or bake into new servers for full monitoring and proactive healing.