« Previous 1 2 3 Next »
Network overlay with VXLAN
Safety Net
VXLAN Extends VLANs
The solution is overlay protocols (Figure 2) to abstract the existing VLAN structure. One option is VXLAN, which allows you to extend a subnet or a Layer 2 broadcast domain on the overlay network to include a Layer 3 underlay network. Therefore, the benefits of routed designs such as equal cost multipathing (ECMP, i.e., equal load distribution between different paths) can be combined with the flexibility of direct Layer 2 links, which would again allow for redundancy within a subnet and even at different locations. VXLAN is defined by the Internet Engineering Task Force (IETF) in RFC7348 [1].
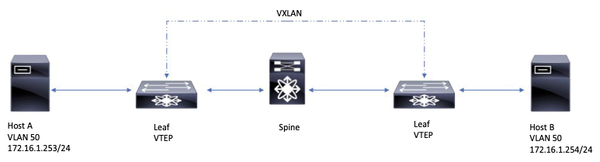 Figure 2: A spine-leaf design with VXLAN overlay: Host A and host B can reside on the same subnet despite different locations and a Layer 3 underlay.
Figure 2: A spine-leaf design with VXLAN overlay: Host A and host B can reside on the same subnet despite different locations and a Layer 3 underlay.
An example of VXLAN as an overlay could be a virtual server system that is redundant and uses the virtual IPv4 address 192.0.2.1. The address is mapped on server A at site A with the physical IPv4 address 192.0.2.2 or on server B at site B with an IPv4 address of 192.0.2.3, depending on the status (Figure 3). If server A fails, server B steps in to handle communications to and from the IPv4 address 192.0.2.1 by Gratuitous Address Resolution Protocol (Gratuitous ARP) message broadcast to all hosts on the subnet. This results in the MAC address for 192.0.2.1 being mapped in the ARP table on server B.
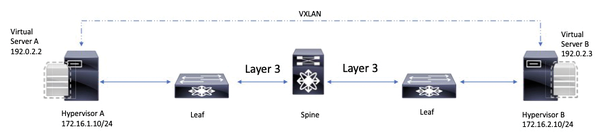 Figure 3: A VXLAN with a hypervisor as a VTEP enables coupling of redundant virtual servers in Layer 2.
Figure 3: A VXLAN with a hypervisor as a VTEP enables coupling of redundant virtual servers in Layer 2.
Without VXLAN, however, this setup would entail the risks and limitations mentioned earlier. Of course, it would be great if the Layer 2 link were not mandatory and the failover and load balancing mechanisms could be implemented directly on the client side and controlled centrally on the server side. Layer 2 coupling would then be obsolete for server-based services.
In addition to these advantages, VXLAN can also extend the maximum number of virtual networks. Classic VLANs supported by the IEEE 802.1Q networking standard offer a maximum of 4,094 segments – up to 16 million for VXLANs. The technology accomplishes this by packaging the Ethernet frames from the hosts into UDP segments. In this case, that means from the server systems at site A and site B. For this to happen, the Internet Assigned Numbers Authority (IANA) has assigned VXLAN its own UDP port number, 4789. The VXLAN header is used as well. The VXLAN segment is identified by a 24-bit VXLAN network identifier (VNI), which is the external identifier confirming membership of a Layer 2 segment.
VLANs are assigned to VNIs on respective VXLAN tunnel end points (VTEPs). VTEPs can be implemented both on a hypervisor (i.e., the virtualization layer between hardware and virtual machine) and on a switch or router.
Hosts that want to communicate over the VXLAN overlay do not need a dedicated agent. Otherwise, it would not be possible for appliances to engage, or it could result in the loss of vendor support. The host does not notice any difference between a direct Layer 2 connection and a VXLAN-based link, because the transport network is transparent for the host. Knowledge of the overlay is the reserve of the VTEPs. They know the overlay structure and must each have an accessible IP address in the underlay to allow the VTEPs to communicate with each other.
However, there are also different procedures on the underlay network: In some cases, multicasting is required for dynamic peering of the VTEPs. The routing protocols in the underlay only enable the connection between the VTEPs, which offers a high degree of flexibility.
How VXLAN Works
To understand how VXLAN works, you first need to consider how Ethernet switches work. Initially, they create MAC address tables on the control plane, which uses Layer 2 source addresses acquired from the respective ports. In the case of an unknown MAC address, unknown unicast flooding normally occurs, which is equivalent to distributing the frame across all ports except the source port. After the MAC addresses have been acquired and the corresponding forwarding tables established, forwarding of the Ethernet frames can take place on the data plane.
In VXLAN, other methods create the forwarding decision tables. Whereas the acquisition target for legacy classic Ethernet switches is the MAC address to target port mapping, the target MAC address for VXLAN must be assigned to the VTEP IP. Only after this has happened can subsequent unicast frames to the respective target MAC address be encapsulated in VXLAN frames and delivered specifically to the target VTEPs.
The first, but also most inefficient and, at the same time, most insecure variant is data plane learning. This method is achieved by acquiring the source addresses and has the distinct disadvantage that the underlying network must be multicast capable, which might not be the case, especially on WANs or in public cloud networks. Multicasting is used on the underlay network to forward what are known as BUM frames (i.e., broadcast, unknown (unicast), and multicast frames in the overlay segment). Data plane learning is also known as flood-and-learn, wherein participating VTEPs join a multicast group to be defined for the respective VNI. VTEPs in turn send traffic to this multicast address.
Separation of Control and Data Planes
One alternative is the Multiprotocol Border Gateway Protocol (MP-BGP) in combination with the Ethernet virtual private network (EVPN) framework, a control plane protocol that optimizes MAC address acquisition and avoids flooding Layer 2 frames over the overlay network. MP-BGP EVPN is responsible for both discovering the VTEPs and learning the MAC addresses and is achieved by first acquiring the MAC address for each VTEP locally, as on legacy Layer 2 networks, and then distributing the acquired MAC address along with the associated IP address to the other VTEPs with the use of a BGP extension that relies on MP-BGP EVPN. This exchange is also known as network layer reachability information.
By correlating this acquired information with the IP address of the source VTEP of this BGP update and the associated VNI, forwarding can subsequently take place in the reverse direction. IP to MAC address mapping is enabled by ARP.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
GENEVE network tunneling protocol
 LAN data transmission has evolved from the original IEEE 802.3 standard to virtual extensible LAN (VXLAN) technology and finally to today's Generic Network Virtualization Encapsulation (GENEVE) tunneling protocol, which offers improved flexibility and scalability, although it still faces some issues. We look at the three technologies and their areas of application.
LAN data transmission has evolved from the original IEEE 802.3 standard to virtual extensible LAN (VXLAN) technology and finally to today's Generic Network Virtualization Encapsulation (GENEVE) tunneling protocol, which offers improved flexibility and scalability, although it still faces some issues. We look at the three technologies and their areas of application. -
Successful protocol analysis in modern network structures
 Virtual networks and server structures require additional mechanisms to ensure visibility of data streams. We show how to monitor and analyze network functions, even when virtualization is involved.
Virtual networks and server structures require additional mechanisms to ensure visibility of data streams. We show how to monitor and analyze network functions, even when virtualization is involved. -
Software-defined networking in OpenStack with the Neutron module
 In classical network settings, software-defined networking (SDN) is a nice add-on, but in clouds, virtual networks are an essential part of the environment. OpenStack integrates SDN technology through the Neutron module.
In classical network settings, software-defined networking (SDN) is a nice add-on, but in clouds, virtual networks are an essential part of the environment. OpenStack integrates SDN technology through the Neutron module. -
Virtual networks with Hyper-V in Windows Server 2016
 Microsoft provides some interesting virtualization features in current and future versions of Windows Server. You can connect or isolate virtual machines, and Windows Server 2016 even supports virtual switches.
Microsoft provides some interesting virtualization features in current and future versions of Windows Server. You can connect or isolate virtual machines, and Windows Server 2016 even supports virtual switches. -
Layer 3 SDN
 Calico chooses an unusual approach for software-defined networking, relying on open standards like BGP. We look at the distinctions and advantages of Calico.
Calico chooses an unusual approach for software-defined networking, relying on open standards like BGP. We look at the distinctions and advantages of Calico.