« Previous 1 2
Adding high availability to a Linux VoIP PBX
NumberPlease
Starting the Cluster
Before starting the cluster, you need to be aware of a couple of concepts. First, HAast/HAfs monitors the health of each node, including hardware, software, OS resources, external devices, and so on, and continuously updates a health score. If the health score goes beyond a limit you define, the cluster will failover to the other node. Therefore, if you find your cluster is failing back-and-forth, check the /var/log/haast file to see if the health of the node is okay.
Another important concept to understand is that in mission-critical telephony environments, nothing may be "shared" between nodes as described earlier (only "synchronized"). If you are wondering why you aren't seeing files and data synchronize between the cluster nodes, you likely have a health problem on the active node.
The easy part is starting the clustering software on each node:
systemctl start haast.service
After your have started HAast/HAfs on both nodes, you can watch the associated logfiles to ensure the services have started, the nodes have found each other, and the cluster has formed. A Telnet interface to HAast/HAfs even allows you to monitor and control the cluster (Figure 3).
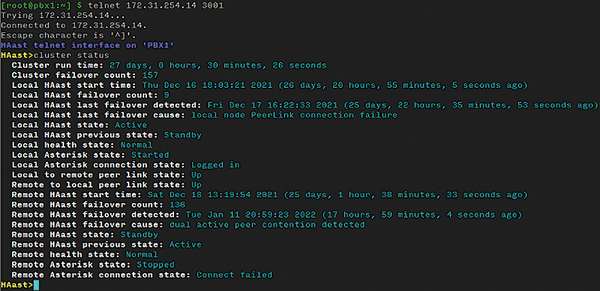 Figure 3: The Telnet interface to the cluster shows the status.
Figure 3: The Telnet interface to the cluster shows the status.
The output of the cluster status command reflects the fact that both nodes are online and the link between them (called peer link
) is up. If the Telnet interface is not responding, you likely have a major configuration issue causing HAast/HAfs to shut down, so check the HAast/HAfs logfile for details. If you see that the peer link connection is down in one or both directions, you have likely misconfigured the IP addresses in the [peerlink] section of the haast.conf file. If the Telnet interface shows the cluster is formed, then use the help command to discover how you can control and monitor the cluster with other commands.
Testing the Cluster
Now that the cluster is running, the first thing you want to do is test it. The simplest test (and least likely in the real world) is to kill the Asterisk process. Figure 4 shows how I killed the Asterisk process on my active node, resulting in the other node immediately taking over.
 Figure 4: Simulating an Asterisk failure.
Figure 4: Simulating an Asterisk failure.
In real life, your PBX is more likely to fail for complicated reasons outside your control, but the above example is a great way to simulate a failure. If you enabled the optional web interface to HAast/HAfs, you can also watch the failover take place in real time. Figure 5 shows the web interface indicating cluster status after the failover is complete.
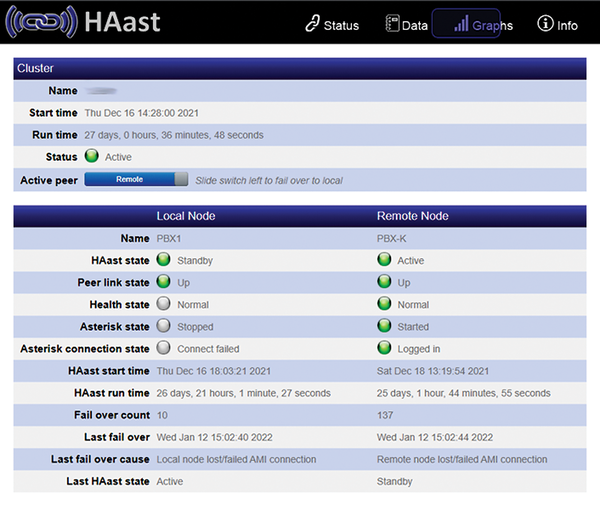 Figure 5: HAast web interface showing failover.
Figure 5: HAast web interface showing failover.
Conclusion
Adding robust high availability to a Linux-based VoIP PBX is surprisingly easy and effective, and this article just scratches the surface. If you get stuck along the way, a 150-page installation guide and dedicated support forums – all offered for free – can be found on the Telium website. It's time to take your VoIP PBX to the next level.
Infos
- Asterisk PBX: https://www.asterisk.org/
- FreeSWITCH PBX: https://freeswitch.com/
- Telium: https://telium.io
- Telium HA products for Asterisk: https://telium.io/haast/
- Telium HA products for FreeSWITCH: https://telium.io/hafs/
- VoIp-Info wiki: https://www.voip-info.org/asterisk-high-availability-design/
- Server fault support website: https://serverfault.com/questions/733403/high-availability-asterisk-voptions
- Issabel: https://www.issabel.com
- FusionPBX: https://www.fusionpbx.com
- Cloning a host across the network: https://www.thegeekdiary.com/how-to-clone-linux-disk-partition-over-network-using-dd/
- G4L on SourceForge: https://sourceforge.net/projects/g4l/
« Previous 1 2
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
- MariaDB Galera Cluster
-
Highly available Hyper-V in Windows Server 2016
 Microsoft has extended the failover options for Hyper-V in Windows Server 2016 to include two new cluster modes, as well as the ability to define an Azure Cloud Witness server. We look at how to set up a Hyper-V failover cluster.
Microsoft has extended the failover options for Hyper-V in Windows Server 2016 to include two new cluster modes, as well as the ability to define an Azure Cloud Witness server. We look at how to set up a Hyper-V failover cluster. -
Clusters with Windows Server 2012 R2
 With Windows, you can create a highly available cluster at the click of a button. The cluster will even handle fully automated, non-disruptive software upgrades.
With Windows, you can create a highly available cluster at the click of a button. The cluster will even handle fully automated, non-disruptive software upgrades. -
Cluster-Aware Updating for Windows Server 2012 R2
 The Cluster-Aware Updating service gracefully handles OS and application updates within your cluster. We show you how to set up and manage this tool.
The Cluster-Aware Updating service gracefully handles OS and application updates within your cluster. We show you how to set up and manage this tool. - Canonical Releases Autonomous Clustering with MicroK8s