« Previous 1 2
Thread processing in Python
Fork This
Ever since Python was created, users have been looking for ways to achieve multiprocessing with threads, which the Python global interpreter lock (GIL) prevents. One common approach to getting around the GIL is to run computationally intensive code outside of Python with tools such as Cython [1] and ctypes [2]. You can even use F2PY [3] with compiled C functions.
All of the previously mentioned tools bypass Python and rely on a compiled language to provide threaded multiprocessing elements with an interface to Python. What is really needed is either a way to perform threaded processing or a form of multiprocessing in Python itself. A very interesting tool for this purpose is Pymp [4], a Python-based method of providing OpenMP-like functionality.
OpenMP
OpenMP [5] employs a few principles in its programming model. The first is that everything takes place in threads. The second is the fork-join model, which comprises parallel regions in which one or more threads can be used (Figure 1).
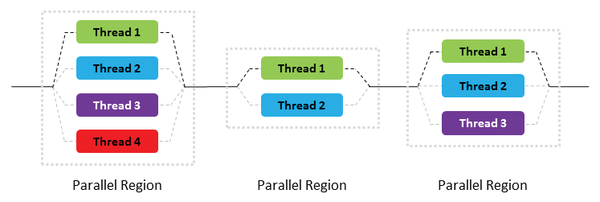 Figure 1: Illustration of the fork-join model for
Figure 1: Illustration of the fork-join model forBuy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Pymp – OpenMP-like Python Programming

Applying OpenMP techniques to Python code .
-
OpenMP – Parallelizing Loops

The powerful OpenMP parallel do directive creates parallel code for your loops.