« Previous 1 2
Artificial intelligence improves monitoring
Voyage of Discovery
Multivariate Analysis
Multivariate analysis extends the principle of bivariate analysis to the simultaneous interpretation of an arbitrary number of curves. For example, if the processor load starts to grow not only on one server, but on several at the same time, the effect is even more relevant. In an age of misuse of resources for illegitimate purposes, such as cryptojacking, attackers want to avoid being noticed at all if possible. A minimal percentage of misused computing power is not noticeable on individual machines. Only an analysis that links conspicuous changes on several servers or studies several metrics together brings such attacks to light and helps stop the attacks promptly.
Machine learning algorithms can also be distinguished according to the number of labels they require, which is of particular interest, because such labels cannot always be generated automatically and are therefore a potentially time-consuming part of the analysis. In supervised learning, labels are essential: The algorithm learns to distinguish between different groups in the training phase by relying on the labels. In semi-supervised learning, at least part of the data is labeled, whereas no labels are necessary in unsupervised learning.
Anomaly detection in particular is increasingly relying on unsupervised methods, especially to detect as early as possible critical situations that have never occurred before. The potential methods range from traditional algorithms like DBSCAN, a density-based data clustering algorithm, to state-of-the-art methods such as Isolation Forest, a learning algorithm for anomaly detection. One point of criticism of unsupervised methods is that, without ground truth, anomalies can still be detected, but it is impossible to estimate how many of the existing events have been found.
Practical Use
Figure 5 shows a use case that resembles the example introduced earlier. The processor load (top left) increases in a linear fashion. The difference plot displayed as a bar chart below each of the four curves illustrates and quantifies the effect by comparing the current situation with that of the previous week. The increase cannot be explained with batch requests (top right). Only joint analysis with hard disk latencies, the version store size (bottom right), and the longest running transaction provides a more accurate picture and explains the processor load.
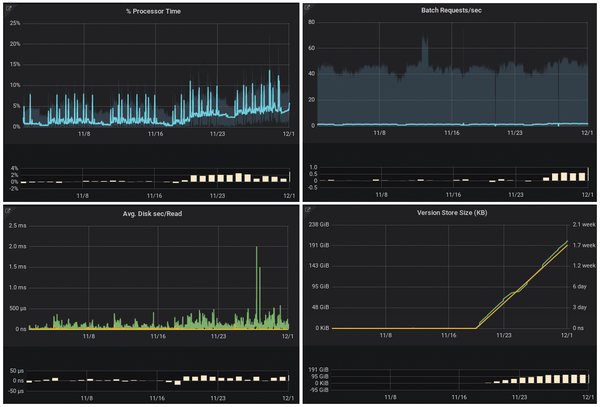 Figure 5: The increase in processor load is not attributable to batch jobs. Additional measured values help provide an explanation.
Figure 5: The increase in processor load is not attributable to batch jobs. Additional measured values help provide an explanation.
AI can be used to detect such constellations without having to search for them manually in dashboards. Therefore, an experienced admin, who would otherwise have to spend a lot of time analyzing the causes, can take immediate action. Critical settings or conditions can be eliminated before serious problems develop with far-reaching consequences. Additionally, AI can examine the expert's countermeasures, detect patterns, and suggest appropriate countermeasures for comparable situations in the future or, in some cases, even initiate the response automatically.
In contrast to traditional reactive monitoring, AI-based methods can look a bit further into the future and notify the administrator as soon as the probability of the current situation turning sour increases.
Besides the traditional question – Is the current situation critical (compared with historical data)? – mathematical answers to the following two questions can also be given: When will a critical situation occur if everything continues as before? What needs to be done so that the situation does not become critical? Where years of experience used to be the main advantage, AI can now calculate which metric is contributing to the respective situation and with what probability.
These theoretical considerations can be transferred to performance monitoring in practice by using, for example, the pipeline shown in Figure 6. A time series database (such as InfluxDB) stores data from heterogeneous sources. The user first checks each incoming metric at step I by univariate analysis and simplifies it with statistical methods to allow navigation. For the most part, alerts are optimized.
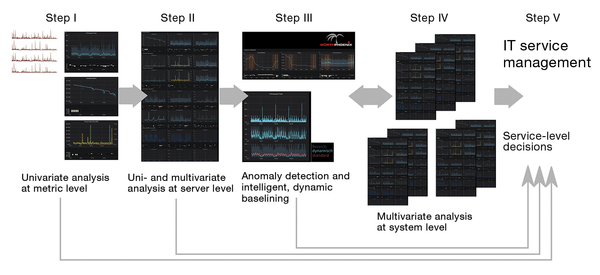 Figure 6: The five steps in the application of AI in performance monitoring.
Figure 6: The five steps in the application of AI in performance monitoring.
Findings gained at step I are transferred to step II, where both univariate and multivariate analysis takes place at the server level. Step III detects anomalies at the server level and evaluates them, helping to create intelligent and dynamic baselines that can be used to prevent faults in the best way possible.
Step IV is influenced directly or indirectly by all previous levels. Multivariate analysis at the system level and the targeted use of machine learning algorithms for analysis and predictions enable efficient root cause analysis. Downtime can be minimized. Finally, step V brings together all previously gained knowledge to improve service management in general. Thanks to the processed and statistically summarized data, as well as the results already achieved, informed decisions can be made and their effects promptly quantified after implementation.
If a company wants to expand its system monitoring capabilities – for example, to check whether a particular application is running smoothly on its own system or at the customer's site – it can use standard solutions such as existing pre-implemented algorithms (e.g., random forests, artificial neural networks, or support vector machines). Provided that the experience in the in-house team is sufficient, results can be achieved that would be inconceivable without AI.
In many cases, promising but more complex approaches that are still in active research cannot be sufficiently generalized to be implemented in standard solutions. Identifying the additional analysis potential they offer for the respective application is a task for experts. All the routines required for data preparation (e.g., normalization, pruning, splitting) are usually available, however.
For this step, it is only important that the person who creates the preprocessing pipeline is sufficiently familiar with the machine learning algorithm to be used later so that they can preprocess the necessary steps in the correct sequence. Automated methods can also achieve results, but with a risk that data will be processed in a time-consuming manner, without the later results making sense from a mathematical point of view or adding genuine value in the real world.
Conclusions
AI and machine learning are changing almost all industries, not least IT. Approaches and methods for recording, analyzing, and processing the data generated by IT operations are grouped under the generic term "IT operations analytics" (ITOA). Modern monitoring systems such as NetEye by Würth Phoenix already provide some simplifications and facilitations for administrators; semi-autonomous solutions should not be long in coming.
However, ITOA clearly cannot replace traditional application performance management (APM). Instead, it is a supplement that empowers administrators to react to problems more quickly and in a more targeted manner. Experienced IT staff remains indispensable.
« Previous 1 2
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Statistics and machine learning with Weka
 The open source Weka tool applies a wide variety of analysis methods to data without the need for advanced programming skills and without having to change environments.
The open source Weka tool applies a wide variety of analysis methods to data without the need for advanced programming skills and without having to change environments. -
Detecting security threats with Apache Spot
 Security vulnerabilities often remain unknown when the data they reveal is buried in the depths of logfiles. Apache Spot uses big data and machine learning technologies to sniff out known and unknown IT security threats.
Security vulnerabilities often remain unknown when the data they reveal is buried in the depths of logfiles. Apache Spot uses big data and machine learning technologies to sniff out known and unknown IT security threats. -
Advantages of data analysis with graph databases
 Analyze scattered but related data in real time with a graph database.
Analyze scattered but related data in real time with a graph database. -
Machine learning and security
 Machine learning can address risks and help defend the IT infrastructure by strengthening and simplifying cybersecurity.
Machine learning can address risks and help defend the IT infrastructure by strengthening and simplifying cybersecurity. -
The limits and opportunities of artificial intelligence
 We talked to Peter Protzel, an academic with experience in knowledge-based systems and process automation, about the future of artificial intelligence.
We talked to Peter Protzel, an academic with experience in knowledge-based systems and process automation, about the future of artificial intelligence.