« Previous 1 2 3 Next »
Make better use of Prometheus with Grafana, Telegraf, and Alerta
Makeover
Telegraf
Almost every Prometheus setup uses the Prometheus Node Exporter, but it is not absolutely necessary. As long as the data is available in the appropriate format, Prometheus does not care from which sources it obtains its metrics. Node Exporter has nevertheless developed into a general-purpose tool because of its feature scope. It collects basic data such as CPU load, RAM usage, and load average without further configuration. Thus, it offers the same functions that many admins first used in classic monitoring systems.
On the one hand, Node Exporter has various plugins that support not only basic values but also special cases, such as reading network statistics for InfiniBand cards. However, other functions have virtually died in the program, such as reading SMART statistics for hard drives, for which Node Exporter can only call an immature external script. Prometheus developers find that their SMART implementation is exactly what Prometheus is supposed to offer, and if that is not enough for a user, then the developers imply that the users are employing Prometheus incorrectly.
If you don't want to have a long discussion with the Prometheus developers, Telegraf might be a good alternative to Node Exporter: The program is part of InfluxData's TICK Stack and therefore lives in the competitor's camp. However, the open APIs provided by modern applications, including Prometheus and InfluxData, allow software from the two camps to work together.
Talking to Prometheus
Prometheus' open standards allowed Telegraf's developers to provide it with a function that outputs Prometheus-compatible metric values. Telegraf is, then, a drop-in replacement for Prometheus Node Exporter. Like Node Exporter, Telegraf opens a TCP/IP port on the respective system and exposes its metric data there. You can configure Prometheus so that it not only connects to Node Exporter, but also queries the Telegraf port.
The only clue that Prometheus is not talking to its native exporter is that the metrics have different names. However, this is irrelevant for Prometheus functionality, because the product is designed to support a wide variety of exporters.
Telegraf is not superior in every way to Prometheus Node Exporter, which, for example, collects various metrics with no adequate equivalent in Telegraf (e.g., metrics for Mellanox network cards). Similarly, from the admin's point of view, it doesn't make much sense to have both Telegraf and Node Exporter collect all metrics, because many are similar, and you would end up with a huge volume of redundant metrics in Prometheus.
Telegraf offers a fundamental advantage in large setups with individual network segments that are isolated from each other by firewalls. If you want to use different exporters in such environments, the result is often massive holes in the firewalls, because theoretically, every exporter needs an open port on every host and in every firewall on the path between the host and Prometheus.
Telegraf can work around that problem by collecting metrics from other exporters that only listen on the localhost IP address 127.0.0.1 and pass them to Prometheus in one fell swoop. This setup saves admins the need for bulk firewall rule editing.
In addition to the collection function described above, Telegraf has an extremely practical function that calls external scripts and sends their output to Prometheus as metrics. In this way, you can create exporters quickly for metrics that currently have none.
Conceivably, for example, you could check compliance on systems with InSpec [2], which can output its results in JSON format. If you call InSpec as an external script from Telegraf and send the results to Prometheus, Prometheus can trigger an alarm if a compliance test fails.
Alerta
The Prometheus Alertmanager will always work reliably if configured correctly. The graphics it creates to visualize alerts, on the other hand, are not convincing. Although it has a web interface, it only lists the alarms that currently exist in the Alertmanager in a very plain format.
If you are familiar with the charts that Nagios or Icinga use, you won't appreciate the Alertmanager output. Its web GUI is certainly not suitable for use as a tool that runs on a screen in a control center to notify admins in case of alerts. However, precisely such a tool is part of the standard toolkit in most operations.
Because Alertmanager has an open API, tools other than those from the Prometheus toolchain can connect to it. The developers of TICK Stack took advantage, once again, and gave their Alerta tool an interface to let it talk to Prometheus Alertmanager.
Alerta itself comprises several components. The most important from the admin's point of view is undoubtedly the web interface (Figure 4). Alerta displays alerts with multiple colors you can set in a configuration file. The Alerta API makes sure that alarms appear in the Alerta web front end in the first place.
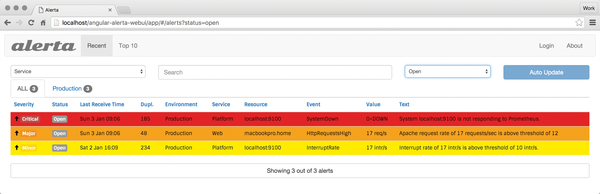 Figure 4: Alerta is a clear and intuitive alternative to the Prometheus Alertmanager GUI.
Figure 4: Alerta is a clear and intuitive alternative to the Prometheus Alertmanager GUI.
All alerts are managed by Alerta through its API; the web interface only displays them. As an alternative to the web interface, you can use a command-line interface (CLI) to manipulate alerts in the shell. However, Alertmanager, which also has a CLI component, can do this, as well.
The web interface proves to be extremely useful in practice: Not only does it display current alarms in tabular form, it also offers various details when the admin clicks on an alarm from the list, such as the date on which the alarm first appeared or the type of alarm.
Alerta differentiates between several problem levels when displaying errors: Critical errors are displayed in red, Major errors are highlighted in orange, less critical Minor errors are highlighted in yellow, and a Warning is highlighted in blue. Prometheus determines the degree to which a problem is relevant.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Monitoring, alerting, and trending with the TICK Stack
 If you are looking for a monitoring, alerting, and trending solution for large landscapes, you will find all the components you need in the TICK Stack.
If you are looking for a monitoring, alerting, and trending solution for large landscapes, you will find all the components you need in the TICK Stack. -
OpenStack observability with Sovereign Cloud Stack
 Operators of an OpenStack environment need to know whether the environment is working and quickly pinpoint problems. We look at the basics of OpenStack observability in the Sovereign Cloud Stack.
Operators of an OpenStack environment need to know whether the environment is working and quickly pinpoint problems. We look at the basics of OpenStack observability in the Sovereign Cloud Stack. -
Getting started with Prometheus
 Prometheus is a centralized time series database with metrics, scraping, and alerting logic built in. We help you get started monitoring with Prometheus.
Prometheus is a centralized time series database with metrics, scraping, and alerting logic built in. We help you get started monitoring with Prometheus. -
Time-series-based monitoring with Prometheus
 As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications.
As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications. -
Monitoring container clusters with Prometheus
 In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation.
In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation.