
Lead Image © Chris Dorney, 123RF.com
DebOps delivers easy Ansible automation for Debian-based systems
Pre-Assembled
Special Thanks: This article was made possible by support from Linux Professional Institute [1].
Enterprise-grade automation solutions like Puppet and Chef are very powerful, but they require a huge amount of learning. Ansible has gained popularity as an alternative to Puppet and the other similar enterprise automation tools. The strict but simple Ansible syntax lets you define roles that are essentially self-documenting (Figure 1), which makes access far easier and ensures that you can integrate your existing knowledge faster.
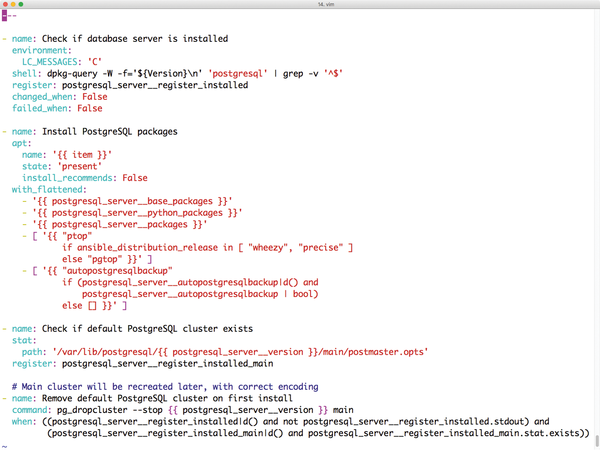 Figure 1: Ansible relies on YAML and takes an approach that forces playbooks to document themselves.
Figure 1: Ansible relies on YAML and takes an approach that forces playbooks to document themselves.
Even though Ansible is simpler than Puppet or Chef, writing your own roles takes time. Wouldn't it be great if you had a library of prebuilt Ansible recipes for standard services that you could install in seconds by pressing a button?
DebOps [2] is a huge collection of prebuilt Ansible roles that you can use on fresh Debian systems.
What Is DebOps?
The collection of prebuilt Ansible roles currently totals more
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
DebOps delivers easy Ansible automation for Debian-based systems
 Ansible is a simple and sensible automation solution, as long as you don’t need to spend a lot of time creating new roles and playbooks. DebOps is a convenient collection of Ansible playbooks for Debian-based Linux systems.
Ansible is a simple and sensible automation solution, as long as you don’t need to spend a lot of time creating new roles and playbooks. DebOps is a convenient collection of Ansible playbooks for Debian-based Linux systems. -
Keeping it simple – the Ansible automator
 The powerful Ansible automator comes without airs and graces, does without complex syntax, self-documents, and has no need to hide its light compared with Puppet and other configuration management tools.
The powerful Ansible automator comes without airs and graces, does without complex syntax, self-documents, and has no need to hide its light compared with Puppet and other configuration management tools.