
Lead Image © artqu, 123RF.com
Scalable network infrastructure in Layer 3 with BGP
Growth Spurt
Large-scale virtualization environments have ousted typical small setups. Whereas a company previously purchased a few physical servers to deploy an application, today, the entire workload of a new setup ends up on virtual machines running on a cloud service provider's platform.
A physical layout often is based on a tree structure (Figure 1), with the admin connecting all the servers to one or two central switches and adding more switches if the number of ports on a switch is not sufficient. Together, the switches and network adapters form a large physical segment in OSI Layer 2.
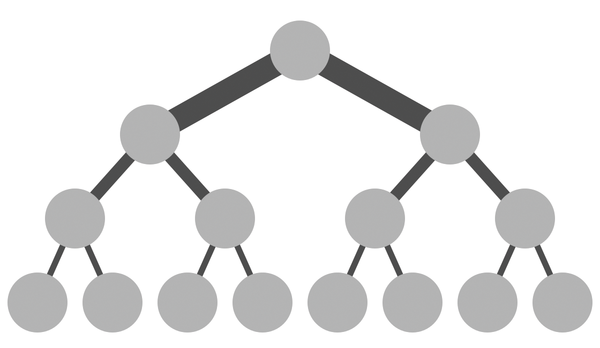 Figure 1: Classic network architectures that follow a tree structure are not suitable for scale-out platforms.
Figure 1: Classic network architectures that follow a tree structure are not suitable for scale-out platforms.
In this article, I describe how you can build an almost arbitrarily scalable network for your environments with Layer 3 tools. As long as two hosts have any kind of physical communication path, communication on Layer 3 works, even if the hosts in question reside in different Layer 2 segments. The Border Gateway Protocol (BGP) makes this possible by providing a way to let each server know how to reach other servers; "IP fabric" describes data center interconnectivity via IP connections.
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
OS10 and Dell's open networking offensive
 Dell's OS10 is a Linux-based operating system for network hardware that is designed to free network admins from the stranglehold of established manufacturers. We look at what it is, how the system works, and what it can do for you.
Dell's OS10 is a Linux-based operating system for network hardware that is designed to free network admins from the stranglehold of established manufacturers. We look at what it is, how the system works, and what it can do for you. -
Software-defined networking with Windows Server 2016
 Windows Server 2016 takes a big step toward software-defined networking, with the Network Controller server role handling the centralized management, monitoring, and configuration of network devices and virtual networks. This service can also be controlled with PowerShell and is particularly interesting for Hyper-V infrastructures.
Windows Server 2016 takes a big step toward software-defined networking, with the Network Controller server role handling the centralized management, monitoring, and configuration of network devices and virtual networks. This service can also be controlled with PowerShell and is particularly interesting for Hyper-V infrastructures. -
Useful tools for automating network devices
 Armed with the right tools, you can manage your network infrastructure both automatically and effectively in a DevOps environment.
Armed with the right tools, you can manage your network infrastructure both automatically and effectively in a DevOps environment. -
Spanning Tree Protocol
 Ethernet is so popular because it simply works and is inexpensive. However, the administration side looks a bit more complicated: For the network to run smoothly, the admin might need to make important decisions about the Spanning Tree protocol.
Ethernet is so popular because it simply works and is inexpensive. However, the administration side looks a bit more complicated: For the network to run smoothly, the admin might need to make important decisions about the Spanning Tree protocol. -
Network overlay with VXLAN
 VXLAN addresses the need for overlay networks within virtualized data centers accommodating multiple tenants.
VXLAN addresses the need for overlay networks within virtualized data centers accommodating multiple tenants.