
Lead Image © Victoria, Fotolia.com
OrientDB document and graph database
Linked Worlds
Relational databases have been popular for many years, but they force users to squeeze their data models into table designs, which has increasingly proved to be too rigid. For example, tables do not have an elegant solution for saving the relationships of objects one below another. The document and graph data structures found in NoSQL (Not only SQL) databases – of which OrientDB is a representative – have solved some of the storage and retrieval problems of relational databases.
In this article, I demonstrate a few of the OrientDB features that cannot be implemented with classical relational databases. Figure 1 shows a comparison: Relational databases keep all data in tables, with a column for each attribute. The tables impose a rigid schema at run time, and additional attributes either require the existing tables to be adapted or an extra table to be defined. Both solutions involve intervention by the database administrator, and possibly even migration of the entire database.
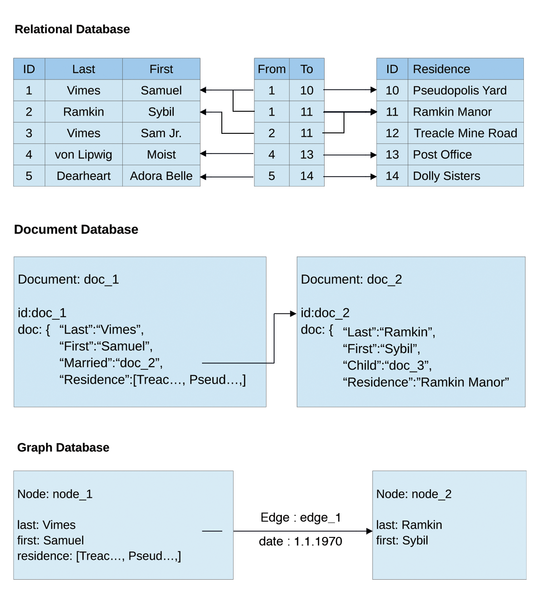 Figure 1: Three kinds of databases.
Figure 1: Three kinds of databases.
With document databases, the data for each object is available in a document (XML, JSON, etc.). Each document has a unique ID that the database uses to access the record. Object links refer to other documents by ID. Additional attributes can easily be added to the document. This structure makes the document database more flexible than the
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
- Third Release Candidate Of OrientDB Speeds Up
-
How graph databases work
 Graph databases excel at revealing the relationships among different but related sets of data.
Graph databases excel at revealing the relationships among different but related sets of data. -
Advantages of data analysis with graph databases
 Analyze scattered but related data in real time with a graph database.
Analyze scattered but related data in real time with a graph database. -
When you should and should not use NoSQL databases
 Tables are an established format for storing information in databases, but they don't always fit the bill – which is just one argument of many that speaks for NoSQL.
Tables are an established format for storing information in databases, but they don't always fit the bill – which is just one argument of many that speaks for NoSQL. -
Getting started with the Apache Cassandra database
 The open source Apache Cassandra database claims to be fail-safe, economical, highly scalable, and easy to manage. A few exercises show whether it lives up to its advertising.
The open source Apache Cassandra database claims to be fail-safe, economical, highly scalable, and easy to manage. A few exercises show whether it lives up to its advertising.