
Parallel programming is not easy, but one tool you can use to help parallelize your application is OpenMP. Most compilers are compatible with OpenMP and allow you to parallelize your code on a single node.
Introduction to OpenMP
Almost any HPC developer will tell you that parallel programming is not easy. Unfortunately, no magic -parallel option exists, so typically you have to dive into the details with the goal of improving the performance of your application. This means really understanding the algorithm, the code that performs the algorithm, and the hardware on which you are going to run the final application.
Today, it’s very easy to get laptops with at least two, if not four, cores. Desktops can easily have eight cores with lots of memory. You can also get x86 servers with 64 cores that access all of the memory on the system. The seductive call of “more cores” is very attractive for improving performance or even running larger problems (or larger games), but it can take a great deal of work to get there.
That magic -parallel compiler option that would automagically parallelize your applications is so elusive because any arbitrary application can be parallelized in a number of ways – including such methods as defining how variables relate to one another, what data pointers represent, and the level of loop parallelism – leaving the compiler with no idea which of the many possible parallelizations is correct. What is needed is a way to guide the compiler by giving it hints about what it can parallelize and how, without having to write lots of extra code. The goal is to keep the number of changes to the source code to a minimum, so they do not affect the building of serial code, and let the compiler parallelize the application for you. This is exactly what OpenMP does.
Introduction to OpenMP
OpenMP, short for Open Multi-Processing, is an Application Program Interface (API) that can be used to direct explicitly multithreaded, shared memory parallelism in applications. It is a set of standard directives and tools that are inserted into code to help guide the compiler in parallelizing the application.
The emphasis is on shared memory systems. For example, it will work for a system with multiple cores, in which all cores can access any memory directly on the system (e.g., a single node with multiple processors). However, OpenMP by itself cannot access memory on a different system (e.g., a completely separate node), even if the systems are networked together. As I pointed out earlier, now that you have tons of cores on single systems, it would be nice to take advantage of them.
The goals of OpenMP are:
- Standardization
- A focused set of directives
- Ease of use
- Portability
The result of the OpenMP effort is a set of very focused, simple, and somewhat limited standard directives for programming shared memory systems. The set of directives are very easy to use and allow the compiler to parallelize portions of your code quickly, and hopefully successfully, according to your directives. They do not release you from understanding your algorithm, code, and the concepts of parallelization; however, they greatly help with the details.
Do not underestimate directives. They allow you easily to explain to the compiler what you want to accomplish. More importantly, directives allow you to keep a single codebase, whether for serial or parallel code. The API is specified for C/C++ and Fortran, and it has been implemented on a large number of compilers, such as GNU, Open64, Intel, and PGI, so it’s very portable; that is, you can take the same code and use different compilers without having to change the source code.
OpenMP suffers from a few misconceptions: It is not the magic -parallel compile option; it does not free you from thinking about how your code operates in parallel; it requires you to think about the section of code you are parallelizing; and you have to pay attention to how the data is shared between threads and how threads can have their own local data. Although it is not always easy, once you see a path forward, the coding portion of OpenMP is really easy.
Fundamentally, OpenMP consists of three parts:
- Compiler directives
- Run-time library support
- Environment variables
The programmer uses compiler directives, which really look like comments, in the code. If the compiler is OpenMP-capable and it is directed to create OpenMP code, then it will act upon the directives. The parallelism is then implemented with the help of a library. Finally, the resulting code is directed at a high level by environment variables (e.g., how many threads to use).
The underlying parallelism in OpenMP is thread based, which means the compiler looks for your directives and attempts to create threads for the portions about which it has been informed. It’s not quite the magic -parallel compile option, but it can very easily do some parallelization under your direction. Therefore, although it is an explicit programming model, which means you still have to know something about your algorithm, it does release you from worrying about how to move data and coordinate the threads because OpenMP takes care of that for you.
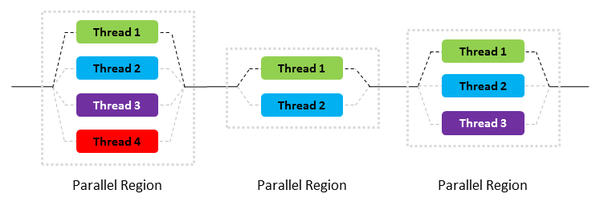 Figure 1: Illustration of a fork-join model for OpenMP.
Figure 1: Illustration of a fork-join model for OpenMP.
OpenMP uses a “fork-join” model of parallel execution (Figure 1). Application execution proceeds from left to right. Initially, the application starts with a single thread (the “master thread,” shown as a solid black line). When the application then hits a parallel region in the code, the master thread creates a team of parallel threads. This is the “fork” phase. The portion of the code in the parallel region is then executed in parallel, with the master thread remaining as one of the threads (the black dashed line; the other threads are shown in light gray).
When the threads in the parallel region finish, they synchronize and terminate, going back to a single thread (the master thread). This is the “join” phase. Execution of the application then proceeds, possibly going through several parallelizations, as shown in Figure 1. Notice that it is possible to control the number of threads in these regions so that they don’t all have to use the same number of threads.
The real advantage of OpenMP is that the developer can specify regions of parallelism with some very simple directives. This means very few, if any, code changes are needed to add parallelism to a serial application. With that quick introduction, I’ll dive into an example to show how OpenMP works on some classic code.
Laplace Solver
To illustrate how OpenMP can be used to parallelize applications, I’m going to use a simple serial Laplace solver as a starting point. A Laplace solver solves a second-order differential equation (elliptical) over a region with specified boundary conditions. In this example, I’ll be using a simple Jacobi iterative approach to solving the questions. Although not the most efficient or fastest method for solving the problem, it does illustrate how one can use OpenMP to parallelize applications.
I will be using the serial code from the cited Boston University website as a starting point. I have made some simple changes to the code to illustrate more clearly the loops where parallelization might be used, and I’ve added a timing function, so I can easily check the wall clock time (how long it takes to run the application). Listing 1 is the serial code I used as a starting point.
Listing 1: Jacobi Iterative Serial Code
001 !
002 ! Solve Laplace equation using Jacobi iteration method
003 ! Kadin Tseng, Boston University, November 1999
004 !
005 MODULE jacobi_module
006 IMPLICIT NONE
007 INTEGER, PARAMETER :: real4 = selected_real_kind(6,37) ! Real
008 INTEGER, PARAMETER :: real8 = selected_real_kind(15,307) ! Double Precision
009 REAL(real8), DIMENSION(:,:), ALLOCATABLE :: unew
010 REAL(real8), DIMENSION(:,:), ALLOCATABLE :: u ! solution array
011 REAL(real8) :: tol=1.d-4, diff=1.0d0
012 REAL(real8) :: delta
013 REAL(real8) :: x
014 REAL(real8) :: pi
015 REAL(real8) :: exact
016 REAL(real8) :: pdiff
017 REAL(real4) :: start_time, end_time
018 INTEGER :: m, iter = 0
019 INTEGER i, j
020 REAL( kind = 8 ) seconds, seconds2, elapsed_time
021 PUBLIC
022
023 CONTAINS
024 SUBROUTINE wtime(wtime2)
025
026 !*****************************************************************************
027 !
028 !! WTIME returns a reading of the wall clock time.
029 !
030 ! Discussion:
031 !
032 ! To get the elapsed wall clock time, call WTIME before and after a given
033 ! operation, and subtract the first reading from the second.
034 !
035 ! This function is meant to suggest the similar routines:
036 !
037 ! "omp_get_wtime ( )" in OpenMP,
038 ! "MPI_Wtime ( )" in MPI,
039 ! and "tic" and "toc" in MATLAB.
040 !
041 ! Licensing:
042 !
043 ! This code is distributed under the GNU LGPL license.
044 !
045 ! Modified:
046 !
047 ! 27 April 2009
048 !
049 ! Author:
050 !
051 ! John Burkardt
052 !
053 ! Parameters:
054 !
055 ! Output, real ( kind = 8 ) WTIME, the wall clock reading, in seconds.
056 !
057 IMPLICIT NONE
058
059 integer ( kind = 4 ) clock_max
060 integer ( kind = 4 ) clock_rate
061 integer ( kind = 4 ) clock_reading
062 real ( kind = 8 ) wtime2
063
064 call system_clock ( clock_reading, clock_rate, clock_max )
065
066 wtime2 = real ( clock_reading, kind = 8 ) &
067 / real ( clock_rate, kind = 8 )
068
069 RETURN
070 END SUBROUTINE wtime
071
072 END MODULE jacobi_module
073
074 !
=====================================================================================
075
076 PROGRAM Jacobi
077 USE jacobi_module
078
079 write(*,*) 'Enter matrix size, m:'
080 read(*,*) m
081
082 CALL wtime(seconds) ! Wall clock time
083
084 delta = 1.0/(m-1) ! Delta (x and y directions)
085
086 ALLOCATE ( unew(1:m,1:m), u(1:m,1:m) ) ! mem for unew, u
087
088 !
089 ! Boundary Conditions
090 ! ===================
091 !
092 pi = DACOS(0.0d0)
093
094 ! Top of unit square: (N)
095 DO i=1,m
096 x=delta*(i-1)
097 u(i,m) = dsin(pi*x)*dexp(-pi)
098 ENDDO
099
100 ! Bottom of unit square: (S)
101 DO i=1,m
102 x=delta*i
103 u(i,1) = dsin(pi*x)
104 ENDDO
105
106 ! Right hand side of unit square: (E)
107 DO j=1,m
108 u(m,j) = 0.0d0
109 ENDDO
110
111 ! Left hand side of unit square: (W)
112 DO i=1,m
113 u(1,j) = 0.0d0
114 ENDDO
115
116 !
117 ! Solution Initialization
118 !
119 DO j=2,m-1
120 DO i=2,m-1
121 u(i,j)=0.0d0
122 ENDDO
123 ENDDO
124
125 !
126 ! Start looping
127 ! =============
128 !
129 DO WHILE (diff > tol) ! iterate until error below threshold
130 iter = iter + 1 ! increment iteration counter
131 IF (iter > 5000) THEN
132 WRITE(*,*)'Iteration terminated (exceeds 5000)'
133 STOP ! nonconvergent solution
134 ENDIF
135
136 diff = -100000.0d0
137 DO j=2,m-1
138 DO i=2,m-1
139 unew(i,j) = (u(i+1,j) + u(i-1,j) + u(i,j+1) + u(i,j-1))/4.0
140 diff = max( diff, abs(unew(i,j)-u(i,j)) )
141 ENDDO
142 ENDDO
143
144 IF(MOD(iter,10)==0) WRITE(*,"('iter,diff:',i6,e12.4)") iter,diff
145
146 ! Update solution
147 DO j=2,m-1
148 DO i=2,m-1
149 u(i,j) = unew(i,j)
150 ENDDO
151 ENDDO
152 ENDDO
153
154 CALL wtime(seconds2) ! Wall clock time
155 elapsed_time = seconds2-seconds
156
157 PRINT *,'Total cpu time =',elapsed_time,' secs'
158 PRINT *,'Stopped at iteration =',iter
159 PRINT *,'The maximum error =',diff
160
161 DEALLOCATE (unew, u)
162
163 END PROGRAM JacobiIf you look through the code, you’ll see three nested loops: (1) initialization of the solution matrix, u (lines 119-123), (2) the iteration loop (lines 137-142), and (3) the update of the solution (lines 146-151). Loops are wonderful places for parallelization – they can use a great deal of wall clock time but also be parallelized fairly easily – so I’ll focus on these areas of the code.
Before I jump into parallelizing these loops, I’ll quickly review some simple utility functions that are provided by OpenMP (use of these functions is not necessary, but I recommend them). The ones I’m going to use are:
- omp_get_num_procs()
- omp_get_max_threads()
- omp_get_num_threads()
- omp_get_thread_num()
To use these functions in the Fortran90 code, I need to include the OpenMP module with the simple use omp_lib command.
The first function, omp_get_num_procs, returns the number of cores or processors in the system. The second function, omp_get_max_threads, tells me the maximum number of threads I can run, which is controlled by an environment variable, OMP_NUM_THREADS. The last function, omp_get_thread_num, returns the number of the thread that calls the function.
I will be using these four functions to acquire information about the OpenMP environment when the code runs (Listing 2). The first three lines are pretty straightforward – they just write some information to standard output (stdout). However, the next section requires some explanation.
Listing 2: OpenMP Utility Function Code
01 write(*,*) 'The number of processors available is ', omp_get_num_procs() 02 write(*,*) 'The number of available threads is ',omp_get_max_threads( ) 03 write(*,*) 'The number of threads in use is ', omp_get_num_threads() 04 05 !$OMP PARALLEL PRIVATE (id) 06 07 id = omp_get_thread_num() 08 write(*,*) 'Thread ',id,' Checking in' 09 10 IF (id == 0) THEN 11 WRITE(*,*) ' Number of threads in use is ',omp_get_num_threads() 12 ENDIF 13 14 !$OMP END PARALLEL
Line 5, !$OMP PARLLEL PRIVATE(id), looks like a comment because it begins with an exclamation mark, but, when followed by $OMP, it becomes an OpenMP compiler directive. If a compiler is not OpenMP-capable, or if you didn’t tell the compiler you had OpenMP directives in your code, it would ignore this statement and treat it as a comment. This directive is telling OpenMP that the next section of code, all the way to !$OMP END PARALLEL (line 14), is to be run in parallel with a number of threads.
Every thread runs the code that falls between the directives (lines 6-13). This code uses the function omp_get_thread_num to determine the number of the thread that is being run. Each thread will have a unique thread number (if it doesn’t, something is seriously wrong). The code then writes the thread ID, which is stored in the variable id, to standard output (stdout) in line 8. However, to make sure the thread numbers are unique to each thread, I need to tell OpenMP that variable id is really private to each thread (i.e., unique), which I do in the first OpenMP directive (line 5) with the phrase PRIVATE (id).
Moving down the code section, the IF ... ENDIF code block (lines 10-12) looks for an id value of 0. When true, it calls the corresponding master thread (i.e., thread 0). All OpenMP applications have a master thread with a thread ID of 0. Although you can create and destroy threads in your code, if you destroy thread 0, you kill the application. The reason I’m checking for the master thread in the parallel section of the code is to ensure that all I/O is done only by the master thread. This prevents problems with threads trying to read or write the same data. Although you can handle I/O in each thread, you have to be extremely careful, or you can corrupt data files pretty easily. Finally, the IF ... ENDIF section prints how many threads are being used.
Now that you have your first OpenMP parallel code, all you need to do is compile the code, set an environment variable, and execute it; however, I want to look a bit more at OpenMP before I present the final code listing.
The particular aspect of OpenMP programming that I will be using to improve performance involves defining parallel regions in the code – regions where the code is parallelized so that each thread executes a copy of the code. The idea is, if you have four threads running the same code, the execution of that section should be close to four times faster than in the serial version. To start, I’ll parallelize the iteration loop block (lines 137-142 in Listing 1) with the use of the PARALLEL OpenMP directive, as I did in Listing 2.
Remember that when splitting the work of a set of loops (nested loops in this case) across a set of threads, each thread is independent. The implication is that each thread will have its own values for variables. For example, a loop variable m defines the upper limit on a loop (e.g., do i=1,m); each thread will have its own version of m, but only the master thread will have a value for m, so you have to tell OpenMP that the value of m needs to be given to each thread; that is, the master thread has to “share” the value with the other threads.
At this point, the OpenMP directive !$OMP PARALLEL only tells OpenMP to create the default number of threads for the block of code and run the code in the block in parallel (i.e., each thread runs exactly the same thing, without sharing the work). Fortunately, OpenMP has some specific directives for parallelizing loops. A variation of the !$OMP PARALLEL statement that tells the compiler to parallelize the loops in Fortran, and thus share the work, is !$OMP DO, which with !$OMP END DO brackets the iteration loop as follows:
!$OMP PARALLEL !$OMP DO DO j=1,m ... ENDDO !$OMP END DO !$OMP END PARALLEL
OpenMP allows you to combine these two directives into one !$OMP PARALLEL DO, which combines a work-sharing construct with a parallel loop construct. The directive around the loops is now:
!$OMP PARALLEL DO DO j=1,m ... ENDDO !$OMP END PARALLEL DO
The last piece to address before attempting to compile the code is the question of variables and scoping (i.e., what values the variables in the threads have, what they modify, and what they need to keep separate from other threads). The first thing to decide is what variables are shared across the threads or what variables are needed by the threads as “input” (i.e., data that needs to be defined when starting the thread). Remember that you want the loops to be parallelized so that each thread has its own portion of the loops and data sets (u and unew). At the same time, you want to make sure the data that is updated is passed back to the master thread, which means you want the data to be shared. Fairly obviously, the variables u and unew need to be shared (with the keyword SHARED in the OpenMP directive), as well as the variable m, so that all threads know that value.
Of the other variables and functions (i.e., i, j, diff, max, and abs), the variables i and j can be local because each thread needs to have its own loop counters, so they don’t need SHARED. Although you could list them as PRIVATE, OpenMP assumes variables are private by default.
The max function is called a “reduction.” The purpose of this function is to search for the largest difference between the new solution in unew and the previous value in u, which should indicate how the solution is progressing. This function should operate on the entire solution, but OpenMP is spreading the solution across all threads, so each thread will have its own value for the variable diff. Somehow, the program needs to search for the largest value within each thread and then search for the largest value across threads. Fortunately, OpenMP has a way to do this easily using the REDUCTION clause, which takes the form:
REDUCTION (<operator>|<intrinsics>: <list>)
In this case, intrinsics is the intrinsic function max.
The REDUCTION clause allows you to perform a reduction on the variable specified by creating a private copy of each variable in each thread. Then, just before the threads are synchronized and stopped, it performs a reduction on all of the private copies to create a “global” value that is then assigned to the global shared variable in the master thread.
For the simple example here, the REDUCTION clause is:
REDUCTION (max:diff)
The operator max reduces all diff values from the threads to a single global value. Listing 3 shows how to wrap the OpenMP directives around the iteration loop.
Listing 3: Loop with OpenMP Directives
!$OMP PARALLEL DO SHARED(m,unew,u) REDUCTION(max:diff) 137 DO j=2,m-1 138 DO i=2,m-1 139 unew(i,j) = (u(i+1,j) + u(i-1,j) + u(i,j+1) + u(i,j-1))/4.0 140 diff = max( diff, abs(unew(i,j)-u(i,j)) ) 141 ENDDO 142 ENDDO !$OMP END PARALLEL DO
The original code is shown with line numbers, surrounded by the added code with no line numbers. So far, I’ve only added two lines to the code to get OpenMP to create any number of parallel threads.
One last thing to do before I compile and run the code is to set the environment variable OMP_NUM_THREAD to the number of desired threads,
export OMP_NUM_THREADS=4
where 4 is the number of threads I want to create on my system. (Note: I used the Bash shell here.) With a four-core processor, I want to run no more than one thread per physical or real core. Although I could set the value to less than 4 (e.g., 1 or 2), anything larger is probably not a good idea because the application won’t run any faster and could, in fact, run slower.
Compiling and Running the Code
For this article, I’m using a system with Scientific Linux 6.2 and the GNU compilers – specifically GFortran. To tell the compiler to pay attention to the OpenMP directives, I use the compiler option -fopenmp, in conjunction with my other compiler options, and just execute the binary as I normally would.
To provide a performance baseline, I first ran the serial version of the code in Listing 1 with a problem size of 1,000 (i.e., m=1000). Notice that it finished in just a little over 44.5 seconds on a single core (Listing 4). I can tell it only used a single processor by looking at GKrellM just after it finished (Figure 2).
Listing 4: Tail End of the Performance Baseline
iter,diff: 2200 0.1082E-03 iter,diff: 2210 0.1077E-03 iter,diff: 2220 0.1072E-03 iter,diff: 2230 0.1067E-03 iter,diff: 2240 0.1063E-03 iter,diff: 2250 0.1058E-03 iter,diff: 2260 0.1053E-03 iter,diff: 2270 0.1048E-03 iter,diff: 2280 0.1044E-03 iter,diff: 2290 0.1039E-03 iter,diff: 2300 0.1035E-03 iter,diff: 2310 0.1030E-03 iter,diff: 2320 0.1026E-03 iter,diff: 2330 0.1021E-03 iter,diff: 2340 0.1017E-03 iter,diff: 2350 0.1012E-03 iter,diff: 2360 0.1008E-03 iter,diff: 2370 0.1003E-03 Total cpu time = 44.528000000165775 secs Stopped at iteration = 2378 The maximum error = 9.99983047509922507E-005
 Figure 2: GKrellM output while executing the serial application.
Figure 2: GKrellM output while executing the serial application.
 Figure 3: GKrellM output runnning the OpenMP application with four threads.
Figure 3: GKrellM output runnning the OpenMP application with four threads.
Notice that CPU1 had a load for a period of time while the other CPUs had almost nothing. This tells me that the application ran on a single core (in this case, CPU1).
Listing 5 is a quick snapshot of the beginning and end of the application running with OpenMP directives around only the main iteration loop. At the top of the listing, notice that all four threads (0-3) “check in” and four processors and four threads are available. If you compare Listings 5 and 4, you will see that it took the same number of iterations and that the maximum error is the same. However, instead of taking 44.5 seconds to complete, it took 18.3 seconds. To make sure it ran on all four cores, I checked out the GKrellM output just after the run (Figure 3).
Listing 5: OpenMP Parallel Application
Enter matrix size, m: 1000 The number of processors available is 4 The number of available threads is 4 The number of threads in use is 1 Thread 0 Checking in Thread 3 Checking in Thread 2 Checking in Number of threads in use is 4 Thread 1 Checking in iter,gdel: 10 0.2402E-01 iter,gdel: 20 0.1210E-01 iter,gdel: 30 0.8080E-02 iter,gdel: 40 0.5984E-02 iter,gdel: 50 0.4845E-02 ... iter,gdel: 2300 0.1035E-03 iter,gdel: 2310 0.1030E-03 iter,gdel: 2320 0.1026E-03 iter,gdel: 2330 0.1021E-03 iter,gdel: 2340 0.1017E-03 iter,gdel: 2350 0.1012E-03 iter,gdel: 2360 0.1008E-03 iter,gdel: 2370 0.1003E-03 Total cpu time = 18.332000000169501 secs Stopped at iteration = 2378 The maximum error = 9.99983047509922507E-005
All four CPUs had a very high load (100 percent) during the run. Comparing Figures 3 and 2, you can also see that the widths of the load indicators (the green traces) are narrower in Figure 3 than in Figure 2, indicating that the application took less time to complete.
The initialization loops (lines 119-123 of Listing 1) and the solution update loops (lines 146-151 of Listing 1) can also be parallelized in the same manner as the main iteration loops (Listing 6), giving just about the best possible parallelization and performance possible.
Listing 6: Final Parallel Code
001 !
002 ! Solve Laplace equation using Jacobi iteration method
003 ! Kadin Tseng, Boston University, November 1999
004 !
005 MODULE jacobi_module
006 IMPLICIT NONE
007 INTEGER, PARAMETER :: real4 = selected_real_kind(6,37) ! Real
008 INTEGER, PARAMETER :: real8 = selected_real_kind(15,307) ! Double Precision
009 REAL(real8), DIMENSION(:,:), ALLOCATABLE :: unew
010 REAL(real8), DIMENSION(:,:), ALLOCATABLE :: u ! solution array
011 REAL(real8) :: tol=1.d-4
012 REAL(real8) :: delta
013 REAL(real8) :: x
014 REAL(real8) :: pi
015 REAL(real8) :: exact
016 REAL(real8) :: diff=1.0d0
017 REAL(real8) :: pdiff
018 REAL(real4) :: start_time, end_time
019 INTEGER :: m, iter = 0
020 INTEGER :: i, j
021 INTEGER :: id
022 REAL( kind = 8 ) seconds, seconds2, elapsed_time
023 PUBLIC
024
025 CONTAINS
026 SUBROUTINE wtime(wtime2)
027
028 !*****************************************************************************
029 !
030 !! WTIME returns a reading of the wall clock time.
031 !
032 ! Discussion:
033 !
034 ! To get the elapsed wall clock time, call WTIME before and after a given
035 ! operation, and subtract the first reading from the second.
036 !
037 ! This function is meant to suggest the similar routines:
038 !
039 ! "omp_get_wtime ( )" in OpenMP,
040 ! "MPI_Wtime ( )" in MPI,
041 ! and "tic" and "toc" in MATLAB.
042 !
043 ! Licensing:
044 !
045 ! This code is distributed under the GNU LGPL license.
046 !
047 ! Modified:
048 !
049 ! 27 April 2009
050 !
051 ! Author:
052 !
053 ! John Burkardt
054 !
055 ! Parameters:
056 !
057 ! Output, real ( kind = 8 ) WTIME, the wall clock reading, in seconds.
058 !
059 IMPLICIT NONE
060
061 integer ( kind = 4 ) clock_max
062 integer ( kind = 4 ) clock_rate
063 integer ( kind = 4 ) clock_reading
064 real ( kind = 8 ) wtime2
065
066 call system_clock ( clock_reading, clock_rate, clock_max )
067
068 wtime2 = real ( clock_reading, kind = 8 ) &
069 / real ( clock_rate, kind = 8 )
070
071 RETURN
072 END SUBROUTINE wtime
073
074 END MODULE jacobi_module
075
076 PROGRAM Jacobi
077 USE jacobi_module
078 USE omp_lib
079
080 write(*,*) 'Enter matrix size, m:'
081 read(*,*) m
082
083 CALL wtime(seconds)
084
085 write(*,*) 'The number of processors available is ', omp_get_num_procs()
086 write(*,*) 'The number of available threads is ',omp_get_max_threads( )
087 write(*,*) 'The number of threads in use is ', omp_get_num_threads()
088
089 !$OMP PARALLEL PRIVATE (id)
090
091 id = omp_get_thread_num()
092 write(*,*) 'Thread ',id,' Checking in'
093
094 IF (id == 0) THEN
095 WRITE(*,*) ' Number of threads in use is ',omp_get_num_threads()
096 ENDIF
097
098 !$OMP END PARALLEL
099
100 delta = 1.0/(m-1) ! Delta (x and y directions)
101
102 ALLOCATE ( unew(1:m,1:m), u(1:m,1:m) ) ! mem for unew, u
103
104 !
105 ! Boundary Conditions
106 ! ===================
107 !
108 pi = DACOS(0.0d0)
109
110 ! Top of unit square: (N)
111 DO i=1,m
112 x=delta*(i-1)
113 u(i,m) = dsin(pi*x)*dexp(-pi)
114 ENDDO
115
116 ! Bottom of unit square: (S)
117 DO i=1,m
118 x=delta*i
119 u(i,1) = dsin(pi*x)
120 ENDDO
121
122 ! Right hand side of unit square: (E)
123 DO j=1,m
124 u(m,j) = 0.0d0
125 ENDDO
126
127 ! Left hand side of unit square: (W)
128 DO i=1,m
129 u(1,j) = 0.0d0
130 ENDDO
131
132 !
133 ! Solution Initialization
134 !
135 !$OMP PARALLEL DO SHARED(m,n,u)
136 DO j=2,m-1
137 DO i=2,m-1
138 u(i,j)=0.0d0
139 ENDDO
140 ENDDO
141 !$OMP END PARALLEL DO
142
143 !
144 ! Start looping
145 ! =============
146 !
147 DO WHILE (diff > tol) ! iterate until error below threshold
148 iter = iter + 1 ! increment iteration counter
149 IF (iter > 5000) THEN
150 WRITE(*,*)'Iteration terminated (exceeds 5000)'
151 STOP ! nonconvergent solution
152 ENDIF
153
154 diff = -100000.0d0
155 !$OMP PARALLEL DO SHARED(m,unew,u) REDUCTION(max:diff)
156 DO j=2,m-1
157 DO i=2,m-1
158 unew(i,j) = (u(i+1,j) + u(i-1,j) + u(i,j+1) + u(i,j-1))/4.0
159 diff = max( diff, abs(unew(i,j)-u(i,j)) )
160 ENDDO
161 ENDDO
162 !$OMP END PARALLEL DO
163
164 IF(MOD(iter,10)==0) WRITE(*,"('iter,gdel:',i6,e12.4)") iter,diff
165
166 !$OMP PARALLEL DO SHARED(m,n,unew,u)
167 ! Update solution
168 DO j=2,m-1
169 DO i=2,m-1
170 u(i,j) = unew(i,j)
171 ENDDO
172 ENDDO
173 !$OMP END PARALLEL DO
174
175 ENDDO
176
177 CALL wtime(seconds2)
178 elapsed_time = seconds2-seconds
179
180 WRITE(*,*) 'Total cpu time =',elapsed_time,' secs'
181 WRITE(*,*) 'Stopped at iteration =',iter
182 WRITE(*,*) 'The maximum error =',diff
183
184 DEALLOCATE (unew, u)
185
186 END PROGRAM JacobiAlthough I only added 24 lines to the code, they allowed me to gather some OpenMP information and add directives for all three loop blocks. The version of the code in Listing 6 was run on four cores (Listing 7).
Listing 7: OpenMP Code with All Loops Parallelized
... iter,gdel: 2300 0.1035E-03 iter,gdel: 2310 0.1030E-03 iter,gdel: 2320 0.1026E-03 iter,gdel: 2330 0.1021E-03 iter,gdel: 2340 0.1017E-03 iter,gdel: 2350 0.1012E-03 iter,gdel: 2360 0.1008E-03 iter,gdel: 2370 0.1003E-03 Total cpu time = 17.579999999841675 secs Stopped at iteration = 2378 The maximum error = 9.99983047509922507E-005
Parallelizing the other two loop blocks shaved about 0.7 seconds from the total time (about another 3.8 percent) when I ran the job with four threads. Given the small amount of work required to write the OpenMP directives, getting another 3.8 percent improvement in performance is something I’ll take every day of the week.
To run on only two threads, I set OMP_NUM_THREADS to 2 (Listing 8; note that you don’t have to recompile).
Listing 8: Running on Two Threads
Enter matrix size, m: 1000 The number of processors available is 4 The number of available threads is 2 The number of threads in use is 1 Thread 0 Checking in Number of threads in use is 2 Thread 1 Checking in iter,gdel: 10 0.2402E-01 iter,gdel: 20 0.1210E-01 iter,gdel: 30 0.8080E-02 iter,gdel: 40 0.5984E-02 iter,gdel: 50 0.4845E-02 ... iter,gdel: 2300 0.1035E-03 iter,gdel: 2310 0.1030E-03 iter,gdel: 2320 0.1026E-03 iter,gdel: 2330 0.1021E-03 iter,gdel: 2340 0.1017E-03 iter,gdel: 2350 0.1012E-03 iter,gdel: 2360 0.1008E-03 iter,gdel: 2370 0.1003E-03 Total cpu time = 23.030000000027940 secs Stopped at iteration = 2378 The maximum error = 9.99983047509922507E-005
You can see at the top of the output that only two threads were used; the number of threads available is only two because OMP_NUM_THREAD was fixed at 2. The GKrellM output in Figure 4 shows that only two threads were active during the run.
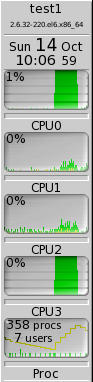 Figure 4: GKrellM output runnning OpenMP application with two threads.
Figure 4: GKrellM output runnning OpenMP application with two threads.
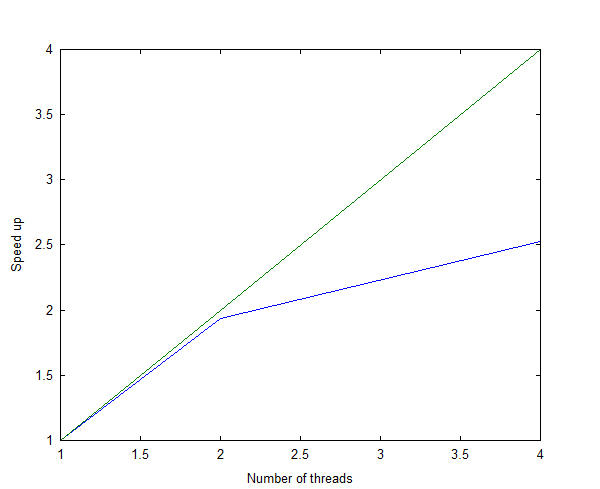 Figure 5: Plot of speed-up.
Figure 5: Plot of speed-up.
You can see that only CPU0 and CPU3 ran near 100 percent. (Note that nothing else was running when the application ran.)
Summary
If you look at the execution time for the Laplace equation code used in my example, you can see that it went from about 44.5 seconds in the serial version to 23 seconds with two cores and 17.6 seconds with four cores in the parallel version. In Figure 5, I plot the speed-up on the y-axis as a function of the number of threads on the x-axis. The blue line is the actual and the green line is the theoretical result.
With two threads, the speed-up is very close to the theoretical line. Although the speed-up with four threads wasn’t much of an improvement, the application did run faster than with two threads. Part of the reason performance did not improve as much as expected is that I didn’t run a large enough problem, so time spent in the parallel loops was low and the effects of the parallelization on performance was minimized.
The point of this article was to show that you can parallelize your code with just a few added lines and take advantage of all of those cores in your system. These added lines, called directives, are a great way to start parallelizing your application.
Don’t think that OpenMP will limit you if you only run on a single node, because you can get single nodes with 64 cores nowadays. Perhaps more importantly, the concept of directives is growing rapidly. For example, an initiative called OpenACC is developing a set of directives that tell compilers how to create code that runs on an accelerator. The most common example of an accelerator is a GPU, so instead of learning CUDA or OpenCL, you can just use directives and let the compiler do the heavy lifting.
Don’t be surprised to see OpenMP and OpenACC merge in some way that will allow you to use a single set of directives that create parallel, heterogeneous code. Other types of processors, such as a Digital Signal Processor (DSP), can be programmed using OpenMP directives, as well. For example, Texas Instruments has a DSP that comes with a programming kit that uses OpenMP for coding.
I hope this quick introduction has given you an appetite for learning more about OpenMP and what it can do for your applications.