
The powerful OpenMP parallel do directive creates parallel code for your loops.
OpenMP
The HPC world is racing toward Exascale, resulting in systems with a very large number of cores and accelerators. To take advantage of this computational power, users have to get away from serial code by writing parallel code as much as possible. Why run 100,000+ serial jobs on an Exascale machine? You can accomplish this with cloud computing. OpenMP is one of the programming technologies that can help you write parallel code.
OpenMP has been around for about 21 years for Fortran and C/C++ programming. Its directives tell the compiler how to create parallel code in certain regions of a program. If the compiler understands the directives, it creates parallel code to fulfill them. Directives have proven to be a good approach to easy parallelization, so OpenACC borrowed this approach (see previous articles).
Directives just look like comments to a compiler that doesn't understand them, so you can keep one source tree for both the original code and the parallel code. Simply changing a compiler flag builds the code for the original code version or for a parallel code version.
Initially, OpenMP focused solely on CPUs. Shared Memory Processing (SMP) systems, in which each processor (core) could “see” all of the others, were coming online. OpenMP provided a very convenient way to write parallel code that could run on all of the processors in the SMP system or a subset of them. As time went on, people integrated MPI (Message Passing Interface) with OpenMP for running code on distributed collections of SMP nodes (e.g., a cluster of four-core processors).
With the ever increasing demand for more computation, companies developed HPC “accelerators,” which are general non-CPU processors such as GPUs (graphic processing units), DSPs (digital signal processors), FPGAs (field programmable gate arrays), and other specialized processors. Fairly quickly GPUs jumped into the lead, offering hundreds if not thousands of lightweight threads. With the help of various tools, users could write code that executed on the GPUs and produced massive speedups for many applications.
Starting with OpenMP 4.0, the OpenMP standard added directives that targeted GPUs and has expanded on this capability with the recent release or OpenMP 5.0.
In this first of several articles introducing OpenMP, I want to get you to take your serial Fortran or C/C++ code and start porting it to parallel processing. To make this as simple as possible, in this and the next two articles I explain a very small number of directives you can use to parallelize your code. Only the most used or easiest to use directives are discussed to illustrate that you don’t need all of the directives and clauses in the standard; just a small handful will get you started porting your code and can result in real performance gains. These articles won’t be extensive because you can find many tutorials online.
OpenMP
OpenMP has a fairly long history in the HPC world. It was started in 1996 by several vendors, each with their own SMP, to create vendor-neutral shared memory parallelism. OpenMP uses pragmas in the form of comments to tell the compiler how it should process the code. With a vendor-neutral approach to SMP, code could be moved easily to other compilers or other operating systems and rebuilt. If the compiler wasn't OpenMP aware, then it would just ignore the comments and build serial code, allowing one code base to be used for serial or parallel code.
OpenMP has matured over the years, steadily adding new features to the standard:
- 1996 – Architecture Review Board (ARB) formed by several vendors implementing their own directives for SMP.
- 1997 – OpenMP 1.0 for C/C++ and Fortran added support for parallelizing loops across threads.
- 2000, 2002 – Version 2.0 of Fortran, C/C++ specifications released.
- 2005 – Version 2.5 combined both specs into one.
- 2008 – Version 3.0 added support for tasking.
- 2011 – Version 3.1 improved support for tasking.
- 2013 – Version 4.0 added support for offloading (and more).
- 2015 – Version 4.5 improved support for offloading targets (and more).
OpenMP is designed for multiprocessor/multicore shared memory machines exclusively using threads. It offers explicit, but not automatic, parallelism, giving the user full control. As previously mentioned, control is achieved by the use of directives (pragmas) embedded in the code.
The OpenMP API has three parts: compiler directives, run-time library routines, and environment variables. The compiler directives are used for such things as spawning a parallel region of code, dividing blocks of code per thread, distributing loop iterations among threads, and synchronizing work among the threads.
In general, OpenMP operates on a fork-and-join model of parallel execution. As shown in Figure 1, application execution proceeds from left to right. Initially the application starts with a single thread, the master thread shown in black. The application then hits a parallel region in the code and the master thread creates a “team” of parallel threads. This is the “fork” phase. The portion of the code in the parallel region is then executed in parallel, where the master thread is one of the threads (the other threads are shown in light gray).
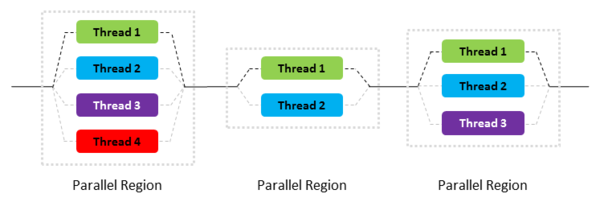 Figure 1: Illustration of fork-and-join model for OpenMP.
Figure 1: Illustration of fork-and-join model for OpenMP.
The OpenMP run-time library has routines for various purposes, such as setting and querying the number of threads, querying unique thread IDs, and querying the thread pool size.
OpenMP environment variables allow you to control execution of parallel code at run time, including setting the number of threads, specifying how loop iterations are divided, and enabling or disabling dynamic threads.
Classically, the run-time portion of OpenMP assigns a thread to each available core on the system (I cover GPUs in a later article), which can be controlled by OpenMP directives in the code or environment variables. The important thing to remember is that OpenMP will use all of the cores if you let it.
OpenMP Directives
Specifying the OpenMP directives in your code is straightforward (Table 1). In general, the directives appear as comments in both Fortran and C, unless the compiler understands OpenMP.
Table 1: Specifying OpenMP Directives
| Fortran | C |
!$OMP or !$omp |
#pragma omp |