
Overcome the Global Interpreter Lock in Python and take advantage of run-time parallelism on multicore machines.
Parallel CPython
The modern way to boost run-time performance of Python programs is to leverage the run-time parallelism provided by modern multicore machines along with the SMP-enabled operating systems. Thus, if you could design your Python applications so that their independent parts run in parallel on these multicore machines at run time, then performance of the applications would be improved a lot. In other words, if your existing Python applications are multithreaded or you write your new code in a way that exploits concurrency, things run in parallel on the multicore machines.
Unfortunately, the current implementation of standard Python known as CPython is unable to provide run-time parallelism for the Python threads on multicore machines because of the Global Interpreter Lock (GIL). I’ll explore ways to conquer this GIL issue in CPython.
The objective of this article is to get you started with parallel computing on multicore/multiprocessor and computing cluster hardware using Python, but you will need some understanding of parallel computing [1]. I used the Ubuntu 9.10 x86_64 desktop distribution along with Python 2.7 to test the code in this article and to generate the screen shots.
Breaking GIL and Extracting Performance
GIL limits the number of the threads that can execute concurrently in the CPython interpreter to one. The lock also impairs the ability of CPython to take advantage of parallel execution in modern multicore machines. To overcome this limitation on Python programs, one uses subprocesses in place of the threads in the Python code. Although this subprocess model does have some creation and interprocess communication overhead, it’s free of the GIL issue and adequate most of the time when dealing with parallelism in Python programs.
If this picture seems complicated to you, don’t worry; you won’t have to deal with the arcane details of lower level subprocess creation and interprocess communication most of the time. All of the alternatives I’ll discuss for turbocharging your Python code are internally based on this multiprocess model. The only difference between them is the level of abstraction provided to parallelize your Python code.
Multithreading the Multiprocessing Way
The easiest way to transform your existing Python code designed with threading is to use the built-in multiprocessing package included in Python from version 2.6 on. This package provides an API similar to the threading Python module. Although some lower level work is needed to turn your new Python code into multicore-friendly applications, you don’t need to download and install any additional Python components. If your application is already using the threading module, you can turn that into code that runs parallel with very few changes because of the interface similarities between threading and multiprocessing.
To begin, you need to use the Process class from multiprocessing to create a new independent subprocess object. The start method of the process object created executes a function passed to it in the subprocess created with a tuple of arguments passed. Also, you should use the join method to wait for the completion of your created subprocess.
After you type the code shown in Listing 1 into a file named basic.py and make the source file executable (with chmod u+x basic.py in a text console), you can run the code either by typing python basic.py or ./basic.py. Then, you should clearly see the different output generated by the different subprocesses.
Listing 1: basic.py
01 #! /usr/bin/env python2.7
02
03 from multiprocessing import Process
04
05 def test(name):
06 print ' welcome ' + name + ' to multiprocessing!'
07
08 if '__main__' == __name__:
09
10 p1 = Process(target = test, args = ('Rich',))
11 p2 = Process(target = test, args = ('Nus',))
12 p3 = Process(target = test, args = ('Geeks',))
13
14 p2.start()
15 p1.start()
16 p3.start()
17
18 p1.join()
19 p2.join()
20 p3.join()To see that multiprocessing creates multiple subprocesses, run the code shown in Listing 2 (counting.py) and Listing 3 (waste.py) and note how different subprocesses print to the console in a mangled manner.
Listing 2: counting.py
01 #! /usr/bin/env python2.7 02 03 from time import sleep 04 from multiprocessing import Process 05 06 def count(number, label): 07 for i in xrange(number): 08 print ' ' + str(i) + ' ' + label 09 sleep((number ‑ 15)/10.0) 10 11 if '__main__' == __name__: 12 13 p1 = Process(target = count, args = (20, ' Rich',)) 14 p2 = Process(target = count, args = (25, ' Nus',)) 15 p3 = Process(target = count, args = (30, ' Geeks',)) 16 17 p1.start() 18 p2.start() 19 p3.start()
Listing 3: waste.py
01 #! /usr/bin/env python2.7 02 03 from multiprocessing import Process 04 05 def waste(id): 06 while 1: 07 print str(id) + ' Total waste of CPU cycles!' 08 09 if '__main__' == __name__: 10 11 for i in xrange(20): 12 Process(target = waste, args = (i,)).start()
The counting.py program delays printing, so you can see the subprocesses play out slowly. I also captured the top command screen while waste.py ran on my dual-core machine; it shows multiple Python subprocesses running concurrently. The results also show the balanced distribution of the subprocesses on multiple cores as the percent idle time (Figure 1).
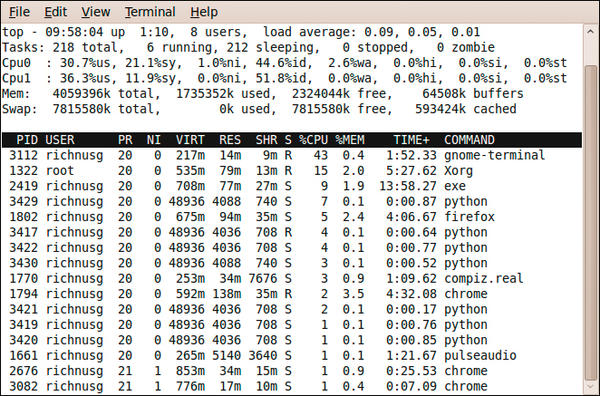 Figure 1: Multiprocessing subprocesses running in parallel.
Figure 1: Multiprocessing subprocesses running in parallel.
If you have worked previously with the lower level thread module or the object-oriented threading interface in Python, then you should clearly see the similarities to multiprocessing.
If you need thread-locking functionality, multiprocessing provides the Lock class, and you can use the acquire and release methods of the lock object. Multiprocessing also provides the Queue class and Pipe function for communication between created subprocesses.
Queue is thread and process safe, so you don’t have to worry about locking and unlocking stuff while working with those. Pipe() returns a pair of connection objects that are connected by pipe in two-way mode by default. If you want a pool of worker subprocesses, then you could use the Pool class. This class offloads the work to the created subprocesses in a few different ways. To see these concepts in action, run the code shown in Listing 4 (miscellaneous.py).
Listing 4: miscellaneous.py
01 #! /usr/bin/env python2.7
02
03 import os
04 from multiprocessing import Process, Lock, Queue, Pipe, cpu_count
05
06 def lockfunc(olck, uilaps):
07 olck.acquire()
08
09 for ui in xrange(4*uilaps):
10 print ' ' + str(ui) + ' lock acquired by pid : ' + str(os.getpid())
11
12 olck.release()
13
14 def queuefunc(oque):
15 oque.put(" message in Queue : LPM rockz!!!")
16
17 def pipefunc(oc):
18 oc.send(" message in Pipe : FOSS rulz!!!")
19 oc.close()
20
21 if '__main__' == __name__:
22
23 uicores = cpu_count()
24 olck = Lock()
25
26 oque = Queue()
27 op, oc = Pipe()
28
29 for ui in xrange(1, 2*uicores):
30 Process(target = lockfunc, args = (olck, ui,)).start()
31
32 opq = Process(target = queuefunc, args = (oque,))
33 opq.start()
34 print
35 print oque.get()
36 print
37 opq.join()
38
39 opp = Process(target = pipefunc, args = (oc,))
40 opp.start()
41 print op.recv()
42 print
43 opp.join()The multiprocessing package provides a lot of other functionality as well, and you can refer to the tutorial link [2] to explore those.
Parallelism Through the pprocess Module
The pprocess module is an external Python module that provides various constructs to exploit the parallel computational capabilities of multicore- and multiprocessor-based machines through Python code. The module is somewhat inspired by the thread Python module, but it provides a simple API and different styles for parallel programming.
The pprocess module is very similar to the multiprocessing package explored previously, so I shall only touch on the important concepts. The pprocess module provides lower level constructs, such as threading, and forking, such as parallelism, as well as higher level constructs such as pmap, channel, Exchange, MakeParallel, MakeReusable, and so on.
To make use of the pprocess module, download the latest version from the homepage [3] and uncompress it with
tar zxvf pprocess‑version.tar.gz
in a text console.
Now issue python setup.py install with sudo or su privileges after cd pprocess‑version to install it. You can verify the successful installation by typing python ‑m pprocess in the text console.
The easiest way to parallelize code that uses map to execute a function over a list is to use pmap, which does the same thing but in parallel. An examples subdirectory in the pprocess source contains the map-based simple.py, along with the pmap version of it, simple_pmap.py. On execution, the pmap version was roughly 10 times faster than the serial map version and clearly shows the performance boost provided by parallel execution on multicores. The screen shot of this map and pmap performance comparison is shown in Figure 2.
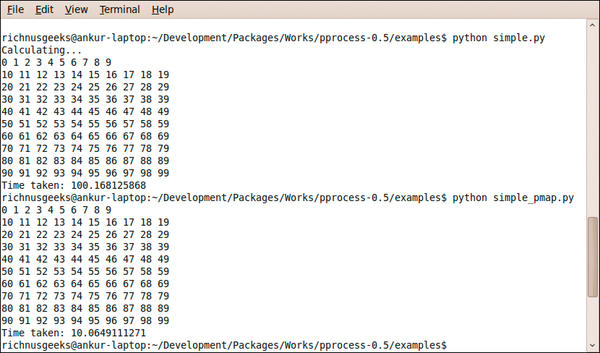 Figure 2: Performance boost through pprocess pmap.
Figure 2: Performance boost through pprocess pmap.
The channels are the objects returned after the creation of subprocesses that are used to communicate with the created processes. Also, you can create an Exchange object to know when to read from channels. The Exchange can be initialized with a list of channels, or the channels could be added through the add method later. To determine whether an exchange is actually monitoring any channels and ready to see whether any data is ready to be received, you can use the active method.
This module also provides a MakeParallel class to create a wrapper around unmodified functions that returns the results in the channels provided. To explore more about pprocess, check the tutorial and references provided in the docs subdirectory and the code samples in the examples subdirectory of the source.
Full-Throttle Multicores and Clusters
Parallel Python (PP) is one of most flexible, versatile, and high-level tools among the options discussed here. The PP module provides one of the easiest ways to write parallel applications in Python. A unique feature of this module is that you can parallelize your Python code over a computing cluster, in addition to multicore and multiprocessor machines, through a very simple programming model by starting the pp execution server, submitting jobs for parallel computing, and retrieving the results.
To install PP, download the latest tarball [4]. In a text console, execute:
tar jzvf pp‑version.bz2 && cd pp‑version
Then, issue
python setup.py install
with sudo or su rights. To confirm the installation, type python ‑m pp in the console, and the command should return without errors. Now, it’s time to get your hands dirty with this marvelous Python module. To run the code shown in Listing 5, either type
python parallel.py
or ./parallel.py after making the source file executable with chmod u+x parallel.py in a text console.\
Listing 5: parallel.py
01 #! /usr/bin/env python
02
03 from pp import Server
04
05 def coremsg(smsg, icore):
06 return ' ' + smsg + ' from core : ' + str(icore)
07
08 if '__main__' == __name__:
09
10 osrvr = Server()
11 ncpus = osrvr.get_ncpus()
12
13 djobs = {}
14 for i in xrange(0, ncpus):
15 djobs[i] = osrvr.submit(coremsg, ("hello FLOSS", i))
16
17 for i in xrange(0, ncpus):
18 print djobs[i]()The code in Listing 5 first creates the pp execution server object using the Server function. This function takes many parameters and, if you don’t provide any, the defaults are good. By default, the number of worker subprocesses created on the local machine is the number of cores or processors in your machine, but you can pass any value desired to the ncpus parameter. Also, you can inquire about the local worker processes created with the get_ncpus method of the execution server object. Parallel programing can’t be simpler than this.
PP shines mainly when you have to split a lot of CPU-bound stuff into multiple parallel parts (e.g., number crunching-intensive code), and it’s not very useful for intensive I/O-bound code. The next step is to run the code in Listing 6 to see the parallel computation in action through PP.
Listing 6: parcompute.py
01 #! /usr/bin/env python
02
03 from pp import Server
04
05 def compute(istart, iend):
06 isum = 0
07 for i in xrange(istart, iend+1):
08 isum += i**3 + 123456789*i**10 + i*23456789
09
10 return isum
11
12 if '__main__' == __name__:
13
14 osrvr = Server()
15 ncpus = osrvr.get_ncpus()
16
17 #total number of integers involved in the calculation
18 uinum = 10000
19
20 #number of samples per job
21 uinumperjob = uinum / ncpus
22
23 # extra samples for last job
24 uiaddtlstjob = uinum % ncpus
25
26 djobs = {}
27 iend = 0
28 istart = 0
29 for i in xrange(0, ncpus):
30 istart = i*uinumperjob + 1
31 if ncpus‑1 == i:
32 iend = (i+1)*uinumperjob + uiaddtlstjob
33 else:
34 iend = (i+1)*uinumperjob
35
36 djobs[i] = osrvr.submit(compute, (istart, iend))
37
38 ics = 0
39 for i in djobs:
40 ics += djobs[i]()
41
42 print ' workers : ' + str(ncpus)
43 print ' parallel computed sum : ' + str(ics)These examples give you an idea of how you can use PP, and you can explore more in the examples subdirectory of the PP source, where you’ll also find some straightforward documentation in the doc subdirectory.
If you want to parallelize your Python code on computing clusters, you have to run a utility known as ppserver.py, which is installed during the installation of PP on the remote computational nodes.
In the cluster mode, you can even set a secret key so the computational nodes will only accept remote connections from a trusted source. The only differences between PP multicores/multiprocessors and cluster modes are the ppserver.py instances, with various options, and a list of the ppserver nodes passed in the Server function. Readers are encouraged to explore more about PP cluster mode through the included documentation.
Conclusion
The CPython GIL presents challenges regarding multicore utilization through Python programs. The built-in multiprocessing package provides the familiar threading interface and breaks the limitations of GIL through a process-based model of threading. The pprocess module also employs the process-forking model to load multicores.
The parallel Python module addresses the manipulation of multicores and clusters through a distributed computation model. With these tools, Python programs can turbocharge modern multicore machines to extract the highest possible performance.
Info
[1] Parallel computing Wikipedia entry:
[http://en.wikipedia.org/wiki/Parallel_computing]
[2] Online documentation for multiprocessing package:
[http://docs.python.org/library/multiprocessing.html]
[3] pprocess homepage:
[http://www.boddie.org.uk/python/pprocess.html]
[4] Parallel Python homepage:
[http://www.parallelpython.com]
[5] Author’s code (click on Article Code at top):
[http://www.admin-magazine.com/Archive/2010/02]