
When building cloud environments, you need more than just a scalable infrastructure, you also need a high-performance storage component. We look at Ceph, a distributed object store and filesystem that pairs well in the cloud with OpenStack.
Storage in the Cloud
No matter how jaded the word “cloud” has become as a buzzword, it has had little effect on the cloud’s popularity, especially in the enterprise: OpenNebula, openQRM, and Eucalyptus are all examples of enterprise clouds, but no solution enjoys similar attention to OpenStack, which resulted from a collaboration of the US space agency NASA and the US hosting service provider Rackspace.
In the past two years, the project has evolved from the underdog to the standard; OpenStack conferences attract far more visitors than many traditional community events. Even the leaders of the OpenStack Foundation are surprised by the success. Companies often evaluate their cloud solutions with a preference for OpenStack (see the box “OpenStack in the Enterprise”).

The Touchy Topic of Storage
When admins plan to set up in the cloud, they must deal with the topic of storage. Traditional storage systems are not sufficient in cloud computing because of two factors: scalability and automation. While an admin can include classic storage in automated processes, the issue of scalability can be more difficult to manage: Once a SAN is in the rack, any potential expansion is often expensive, if it is even feasible.
One aggravating factor for a public cloud provider is that you can hardly predict the required disk space. On the basis of recent demand, you might be able to calculate the growth of disk space, but that is little help if a new customer appears out of the blue requiring 5TB of space for its image hosting service. As with computing components, the provider must be able to expand the cloud quickly, and this is where the open source and free Ceph software enters the game. The source code of the distributed filesystem Ceph is largely covered by the LGPL and BSD licenses.
Ceph Rules
An existing Ceph cluster can be easily extended by adding disks; only commodity hardware is required. Normal SATA disks complete the array, which affects the project budget considerably less than a (usually much smaller) SAS disk would.
It helps admins that Inktank has promoted the seamless integration of OpenStack and Ceph in recent months and, in a sense, already ensures at the factory that OpenStack optimally leverages the capabilities of Ceph. To determine the ideal location for Ceph and OpenStack, it makes sense to look at the kind of data the OpenStack components process and how they deal with storage.
Who Stores What?
In OpenStack services, two types of data basically occur: metadata and the actual payload. Technically, the metadata includes the cloud-specific configuration, which is usually handled by a separate database, such as MySQL. Most of the services deployed for virtualization purposes in OpenStack exclusively store metadata in the long term; this includes Keystone (identity service), Neutron (Network as a Service), Heat (Orchestration), and Ceilometer (monitoring).
The OpenStack dashboard. a.k.a. Horizon, does not create any data – either meta or user. The compute service Nova is a special case: The component takes on the job of managing virtual machines. In addition to persistent metadata, it creates temporary images of virtual machines. The images of VMs in OpenStack are volatile – virtually by definition: in technical jargon, this is known as “ephemeral storage.” If Nova wants to store a VM permanently, it needs to rely on an additional service.
This just leaves two services, Glance and Cinder, which create payload data in addition to their own metadata. Glance is the image service. Its purpose in life is to offer redundant image files from which new VMs can be booted. Cinder is the block storage service; it steps in to help Nova when the VMs require persistent storage. The task is thus to team Ceph with these two services to achieve optimal OpenStack integration.
Swift versus Ceph
If you have worked with OpenStack before, you are probably asking what role Swift, OpenStack’s in-house storage service, plays in this scenario. It seems absurd at first glance to integrate an external solution if OpenStack purportedly offers a comparable function – “purportedly,” because in fact there are a few big differences between Swift and Ceph.
The similarities, however, are quickly listed: Like Ceph, Swift is also an object store; it stores data in the form of binary files and thus enables horizontal storage scaling. The native Swift interface provides an API that understands both the in-house Swift protocol as well as Amazon’s Simple Storage Service (S3). At the Ceph level, admins can achieve similar behavior by additionally deploying the Ceph Gateway. It provides almost the same functions as the Swift proxy.
What is striking, however, are the differences between the two solutions: Ceph does quite different things under the hood than Swift. The complete CRUSH (Controlled Replication Under Scalable Hashing) functionality, which in Ceph handles the task of splitting and distributing data to different drives, is something that OpenStack’s native object store totally lacks.
Instead, Swift decides on the basis of a proprietary algorithm exactly where to put an uploaded file. Splitting or simultaneous reading of individual objects from multiple target servers does not take place, so if you read data from a Swift cluster, you always do so from a single disk. In terms of performance, you have to make do with what that disk can give you.
Ceph and Swift also differ in terms of the number of interfaces they offer; besides the two protocols I mentioned earlier, Swift only understands protocols that use the RESTful principle, but no other languages.
In contrast, the Ceph gateway itself supports the RBD (Rados Block Device) driver, either based on the kernel module rbd, or via the RBD library. Ceph thus provides an interface at the block level and is useful as direct block storage for virtual machines. Swift completely lacks this option, but turns out to be important in the OpenStack context.
Consistency
Ceph relies on a concept in which all data are always 100% consistent. Internally, it uses different features that protect the integrity of the data to achieve this. It also imposes a quorum: if a Ceph cluster fails, only those parts that remain functional reside in the majority partition (i.e., those that know that the majority of the nodes in the cluster are on their side). All other nodes refuse to work.
In the worst case, this can mean that a Ceph cluster fails and is unusable because the remaining nodes do not achieve a quorum. The administrator, on the other hand, can always be sure that access to storage is coordinated at all times; in other words, there will never be a split-brain scenario in which undesirable inconsistencies arise.
In contrast, Swift follows an “eventually consistent” approach: In a Swift cluster, 95 of 100 nodes can fail. The five remaining nodes would still allow write access and serve read requests if they have the requested object locally.
If a Swift cluster fell apart, users could write divergently to the nodes of different cluster partitions. At the moment of reunification, Swift would then simply replace the divergent data throughout the cluster with the latest version of a record. Swift clusters thus almost always remain available, but do not guarantee data consistency, which often becomes a problem in enterprise setups.
OpenStack and Ceph Basics
How exactly cloud operators manage the OpenStack and Ceph installation is left up to them; all roads lead to Rome, as they say. From the OpenStack side, the options – besides manual installation – include Packstack or even Kickstack. You can install Ceph quite conveniently with the help of the ceph-deploy tool – and even automatically with Chef and Puppet.
Special care should be taken when planning the cluster for Ceph. As always with storage, it is predominantly a question of performance, and only the performance the cluster is capable of delivering will actually reach the virtual machines later on. Staging a high-performance Ceph cluster is not too complicated, despite all the doomsayers (see the box “Cluster Performance”).

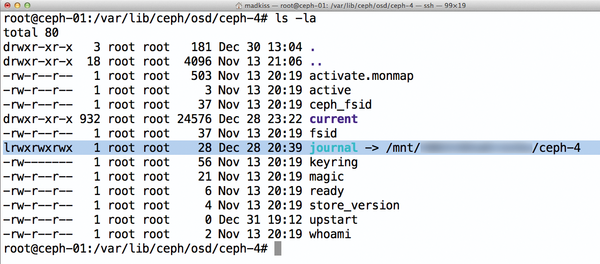 Figure 1: Easy to see: The OSD journal is on a separate partition, which belongs to a solid state disk; this usually leads to significant performance gains.
Figure 1: Easy to see: The OSD journal is on a separate partition, which belongs to a solid state disk; this usually leads to significant performance gains.
Once OpenStack and Ceph are professionally installed – and assuming the Ceph cluster has the power it needs under the hood – the rest of the setup only involves integrating the OpenStack Cinder and Glance services with Ceph. Both services come with a native back end for Ceph, which the administrator then enables in the configuration. However, this step also affects security: Inktank recommends creating separate Cephx users for Cinder and Glance (Figure 2).
 Figure 2: The ceph.conf file contains entries for the keyrings of the Cinder and Glance users. The admin copies them along with the key files themselves to the affected hosts.
Figure 2: The ceph.conf file contains entries for the keyrings of the Cinder and Glance users. The admin copies them along with the key files themselves to the affected hosts.
Guests at the Pool
Cephx is Ceph’s internal function for user authentication. After deploying the Ceph cluster with the ceph-deploy installer, this authentication layer is enabled by default. The first step in teaming OpenStack and Ceph should be to create separate Cephx users for Cinder and Glance. To do this, you define separate pools within Ceph that only the associated service can use. The following commands, which need to be run with the permissions of the client.admin user, create the two pools:
ceph osd pool create cinder 1000 ceph osd pool create images 1000
The administrator can then create the corresponding user along with the keyring (Listing 1). The best place to do this for Glance and its users is the host on which glance-api is running, because this is where Glance expects the keyring. If you want glance-api to run on multiple hosts (e.g., as part of a high-availability setup), you need to copy the /etc/ceph/ceph.client.glance.keyring file to all the hosts in question.
The commands for the Cinder user are almost identical (Listing 2). The ceph.client.cinder.keyring file needs to be present on the host or hosts on which cinder-volume is used. It is then a good idea to add an entry for the new key to the /etc/ceph/ceph.conf configuration file (Listing 3).
Listing 1: Creating a Glance User
01 ceph auth get-or-create client.glance mds 'allow' osd 'allow * pool=images' mon 'allow *' > /etc/ceph/ceph.client.glance.keyring 02 chmod 0640 /etc/ceph/ceph.client.glance.keyring
Listing 2: Creating a Cinder User
01 ceph auth get-or-create client.cinder mds 'allow' osd 'allow * pool=cinder' mon 'allow *' > /etc/ceph/ceph.client.cinder.keyring 02 chmod 0640 /etc/ceph/ceph.client.cinder.keyring
Listing 3: ceph.conf
01 [client.glance] 02 keyring = /etc/ceph/ceph.client.glance.keyring 03 04 [client.cinder] 05 keyring = /etc/ceph/ceph.client.cinder.keyring
Preparing Glance
Following these steps, Ceph is ready for OpenStack. The components of the cloud software now need to learn to use Ceph in the background. For Glance, this is simple: You just set up the glance-api component. In its configuration file, which usually resides in the path /etc/glance/glance-api.conf, take a look at the default_store parameter (Figure 3). This parameter determines where Glance stores its images by default. If you enter the value rbd here, the images end up with Ceph in the future. After restarting glance-api, the changes are now active.
 Figure 3: The file entry is the default value in glance-api.conf. For Glance to use RBD, you need to enter rbd instead of file.
Figure 3: The file entry is the default value in glance-api.conf. For Glance to use RBD, you need to enter rbd instead of file.
Lower down in the file, you will also see some parameters that determine the behavior of Glance’s rbd back end. For example, you can set the name of the pool that Glance will use (Figure 4). The example shown uses the default values, as far as possible.
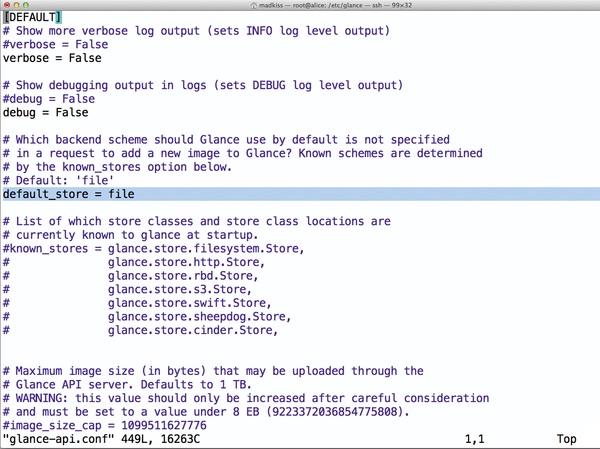 Figure 4: In the glance-api.conf configuration file there are some additional RBD options that define the behavior of the rbd back end.
Figure 4: In the glance-api.conf configuration file there are some additional RBD options that define the behavior of the rbd back end.
Getting Cinder Ready
Configuring Cinder proves to be more difficult than configuring Glance because it involves more components. One thing is for sure: The host running cinder-volume needs to talk to Ceph. After all, its task later on will be to create RBD images on Ceph, which the admin then serves up to the VMs as virtual disks.
In a typical Ceph setup, the hosts that run the VMs (i.e., the hypervisors) also need to cooperate. After all, Ceph works locally: The host on which cinder-volume runs does not act as a proxy between the VM hosts and Ceph; this would be an unnecessary bottleneck. Instead, VM hosts talk directly with Ceph later on. To do this, they need to know how to log in to Ceph as Cephx.
The following example describes the configuration based on KVM and Libvirt, which both have a Cephx connection. Other virtualizers provide their own control mechanisms that let them talk to Ceph – other hypervisors, such as VMware, do not have direct Ceph back ends.
The first step in configuring the hypervisor is to copy a functioning ceph.conf file from an existing Ceph host. Also, any required Cephx key files need to find their way to the hypervisor. For the Ceph-oriented configuration of Libvirt, you first need a UUID, which you can generate at the command line using uuidgen. (In my example, this is 2a5b08e4-3dca-4ff9-9a1d-40389758d081.) You then modify the Cinder configuration in the /etc/cinder/cinder.conf file to include the four color-highlighted entries from Figure 5. Restarting the Cinder services cinder-api, cinder-volume, and cinder-scheduler completes the steps on the Cinder host.
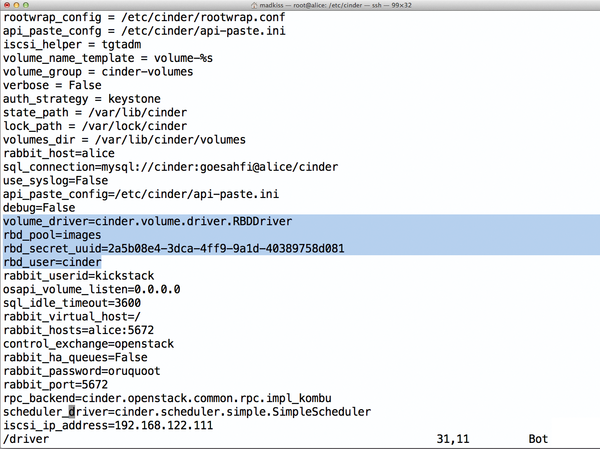 Figure 5: cinder.conf also requires additional settings to help it cooperate with Ceph.
Figure 5: cinder.conf also requires additional settings to help it cooperate with Ceph.
Hypervisor Plus Cephx
Still missing is the Cephx configuration on the hypervisor systems. You can use a trick to integrate them by giving each hypervisor a ceph-secret.xml file, which you populate with the contents of Listing 4. Then, run the
virsh define secret-ceph-secret.xml
command to create the entry for the password in the internal Libvirt database. However, this is just a blank entry without a password. The latter consists of the user’s Cephx client.cinder key; the command
ceph-authtool --id client.cinder --print- key /etc/ceph/ceph.client.cinder.keyring
outputs it on the screen. Finally, you assign the actual password to the empty space you create – in this example:
virsh secret-set-value 2a5b08e4-3dca-4ff9-9a1d-40389758d081 AQA5jhZRwGPhBBAAa3t78yY/0+1QB5Z/9iFK2Q==
Listing 4: ceph-secret.xml
01 <secret ephemeral="no" private="no"> 02 <uuid>2a5b08e4-3dca-4ff9-9a1d-40389758d081</uuid> 03 <usage type="ceph"> 04 <name>client.cinder secret</name> 05 </usage> 06 </secret>
The workflow from creating ceph-secret.xml to inputting the virsh command needs to be repeated on each host. Libvirt at least remembers the password after the first entry. The reward for all of this effort is a number of VMs that access Ceph directly, without any detours.
High-Speed Storage
One possible way to tease more performance out of the Cinder and Ceph team is for users to configure multiple volumes on their virtual machines and then combine them on the VM to create a virtual RAID 0. You could thus bundle the performance of each object storage device, which would allow write speeds of 500MBps and more within the VMs.
Conclusions
OpenStack and the Ceph object store are certainly not just a flash in the pan. The cloud storage solution that admins generate by teaming distributed object storage with the computing components of OpenStack impresses with its stability, redundancy, and performance – it significantly outperforms conventional virtualization systems.
If you are planning to build an open cloud in the near future and want to tackle the topic of storage the right way, right from the start, you will want to try teaming OpenStack and Ceph.
Info
[1] VMware vCloud
The Author

Martin Gerhard Loschwitz is the principal consultant with Hastexo, where he focuses on high-availability solutions. In his leisure time, he maintains the Linux Cluster stack for Debian GNU/Linux.