« Previous 1 2 3 Next »
Detect anomalies in metrics data
Jerk Detector
Fourier and Prophet
Metrics are available as numbers in Prometheus; however, sinusoidal curves are far better suited for accurate analysis of the current data, as well as the future development of these values in the context of machine learning. Each value is represented in the form of a frequency. The Fourier algorithm is responsible for the transformation between the worlds by using sine and cosine to convert the numbers into frequency signals, after which useful basic data is available for the prediction. This process is known as "fast Fourier transformation," which goes back to the mathematicians James Cooley and John Tukey, who popularized the idea for converting data into sinusoidal curves in a paper that appeared in 1965 [1]. The method is now considered a standard algorithm of modern IT. The Fourier module in Python has an AI-trainable model to predict the further evolution of an existing graph on the basis of historical values.
The other algorithm that PAD uses to detect anomalies, Prophet, comes directly from the Facebook social network (Figure 1) and is significantly more complex in direct comparison with Fourier. In return, it allows factoring into its predictions such things as the potential seasonality of data, including the factors year, week, and day. All told, the dataset that Prophet uses to analyze ongoing data streams, predict their continuation, and raise the alarm if necessary is far larger.
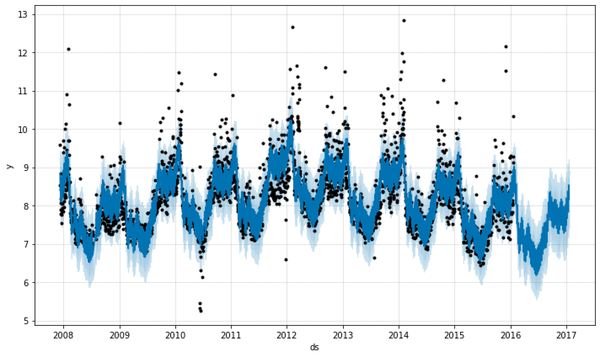 Figure 1: The Prophet PAD component is trimmed to respond correctly with predictive methods to the smallest deviations in metric data, represented here by the black dots.
Figure 1: The Prophet PAD component is trimmed to respond correctly with predictive methods to the smallest deviations in metric data, represented here by the black dots.
PAD, with its two implementations of anomaly detection, goes significantly further than the analysis of the acquired metrics described at the beginning. The aim is not just to notice that something is wrong at an early stage, but to notice it even earlier: Both Fourier and Prophet are trainable AI models in PAD that use existing metrics data to predict the evolution of the respective metrics, allowing for a response at the slightest sign of an anomaly. Your task is to compare the developments of a metric value calculated by Prophet or Fourier with the actual state. Ideally, thanks to the trained models in PAD, you will notice very quickly that something suspicious is going on (Figure 2).
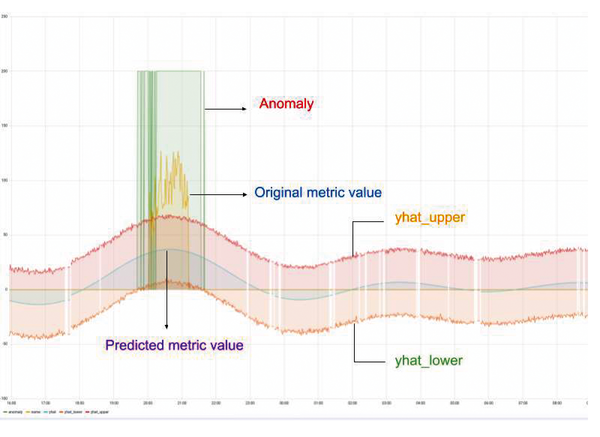 Figure 2: The blue line shows the predicted evolution of the data for the respective metric; yellow and green indicate the range of variation. The anomaly is clearly visible.
Figure 2: The blue line shows the predicted evolution of the data for the respective metric; yellow and green indicate the range of variation. The anomaly is clearly visible.
A Failure to Scale
From the very beginning, the Prometheus developers designed their work to ignore high availability in the classical sense. Instead, you have to run multiple instances of Prometheus at the same time. Because retrieving metrics data from the target systems ties up virtually no resources, it doesn't generate more load on the monitored systems. If one of the running instances fails, the idea is that you have enough other instances to query. In this way, comprehensive deduplication is implemented at the alert manager level: If 20 instances feed an alert into the alert manager because of the same metric value, the alert manager still sends only one message to the alerting targets.
However, this use case turns ugly when it comes to horizontal scaling. Massively scalable environments, in particular those with hundreds or thousands of hosts, mean that individual Prometheus instances become a bottleneck over time. If you go for manual sharding, however, you lose the central advantage of the single point of administration because individual Prometheus instances then query a local list of targets, and it's your task to connect to the appropriate Prometheus instance to view the metrics for a particular host. What's more: Grafana also needs to be configured in the same way and different queries need to access the different data sources in Grafana.
What's almost worse, though: The more data Prometheus stores, the slower and more unresponsive it becomes. However, you do have a legitimate interest in retaining historical data because it allows for better scalability planning and makes it easier to identify trends. If you keep too much legacy information in Prometheus, calling individual Grafana dashboards will soon take several seconds. Intelligent downsampling of data is missing, as is high-performance storage for archived data outside of Prometheus itself.
Thanos and Historical Data
Thanos is now a separate project, independent of Prometheus, that wraps around several self-sufficient Prometheus instances. First, Thanos provides a unified query view: No matter which of the Prometheus instances connected to Thanos has the metrics data for a particular host, the admin always talks to Thanos, which gathers the data appropriately in the background. The same thing also applies to Grafana instances.
Second, a Thanos component is responsible for storing historical data in a meaningful way. To this end, Thanos provides an interface, known as StoreAPI, to its own storage implementation, as well as interfaces to other databases. Thanos provides Prometheus with the Sidecar component, which dynamically handles writes not to local Prometheus memory, but distributed across the network. The long-term storage of the historical data is so much better than if Prometheus itself were used for this purpose.
In brief, Thanos is a practical extension to the plain vanilla Prometheus that has found its way into many installations around the world. The fact that Prometheus anomaly detection takes advantage of Thanos is hardly surprising: In particular, storing historical data is extremely helpful when it comes to detecting anomalies.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Artificial admin
 AIOps brings artificial intelligence tools into everyday administrative work, with AI-supported automation of some admin responsibilities.
AIOps brings artificial intelligence tools into everyday administrative work, with AI-supported automation of some admin responsibilities. -
Monitoring, alerting, and trending with the TICK Stack
 If you are looking for a monitoring, alerting, and trending solution for large landscapes, you will find all the components you need in the TICK Stack.
If you are looking for a monitoring, alerting, and trending solution for large landscapes, you will find all the components you need in the TICK Stack. -
Time-series-based monitoring with Prometheus
 As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications.
As Prometheus gave fire to mankind, the distributed monitoring software with the same name illuminates the admin's mind in native cloud environments, offering metrics for monitored systems and applications. -
Monitoring container clusters with Prometheus
 In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation.
In native cloud environments, classic monitoring tools reach their limits when monitoring transient objects such as containers. Prometheus closes this gap, which Kubernetes complements, thanks to its conceptual similarity, simple structure, and far-reaching automation. -
A new approach to more attractive histograms in Prometheus
 Histograms are a proven means of displaying latencies in Prometheus, but until now, they have had various restrictions. Native histograms now provide a remedy.
Histograms are a proven means of displaying latencies in Prometheus, but until now, they have had various restrictions. Native histograms now provide a remedy.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
