« Previous 1 2 3
Monitoring HPC Systems
Nerve Center
Ganglia Clients
As soon as you have the master node up and running, it's time to start getting other nodes to report their information to the master. This isn't difficult; I just installed the gmond RPMs on the client node.
I used the exact same command I did for installing gmond on the master node. The output looks something like Listing 11. I did have to make sure I had libconfuse installed on the client node before installing the RPMs.
Listing 11
Installing gmond on Clients
Retrieving http://vuksan.com/centos/RPMS-6/x86_64/ganglia-gmond-modules-python-3.6.0-1.x86_64.rpm Retrieving http://vuksan.com/centos/RPMS-6/x86_64/libganglia-3.6.0-1.x86_64.rpm Retrieving http://vuksan.com/centos/RPMS-6/x86_64/ganglia-gmond-3.6.0-1.x86_64.rpm Preparing... ########################################### [100%] 1:libganglia ########################################### [ 33%] 2:ganglia-gmond ########################################### [ 67%] 3:ganglia-gmond-modules-p########################################### [100%]
The next steps are pretty easy, just start up gmond:
[root@test8 ~]# /etc/rc.d/init.d/gmond start Starting GANGLIA gmond: [ OK ] [root@test8 ~]# /etc/rc.d/init.d/gmond status gmond (pid 3250) is running...
At this point, gmond should be running on the client node. You can check this by searching for it in the process table with the following command:
ps -ef | grep -i gmond
If you see it, then gmond should be running fine. If not, check /var/log/messages for anything that might indicate you have problems. If you don't find anything there, then try running gmond interactively with
/usr/local/sbin/gmond/gmond -d 5 -c /etc/ganglia/gmond.conf
and look for problems. (Maybe you are missing something on the client system?)
The next step is to add the client to the list of nodes on the master node. As root, edit the file /etc/ganglia/gmetad.conf, then go to the line that starts with data_source and add the IP address of the client node. In my case, the IP address of the client is 192.168.1.250. Now save the file and restart gmetad using:
/etc/rc.d/init.d/gmetad restart
If you are successful, you should see the second node in the web interface (Figure 3). Notice that both nodes are shown: home4 (master node) and 192.168.1.250 (client). In the upper left-hand corner, you can see the number of hosts that are up (2). I also scrolled down a bit in the web page so you could see the "1-minute" stacked graph (called load_one). Notice that you see both hosts in this graph (green = home4, red = 192.168.1.250). I think I can declare success at this point.
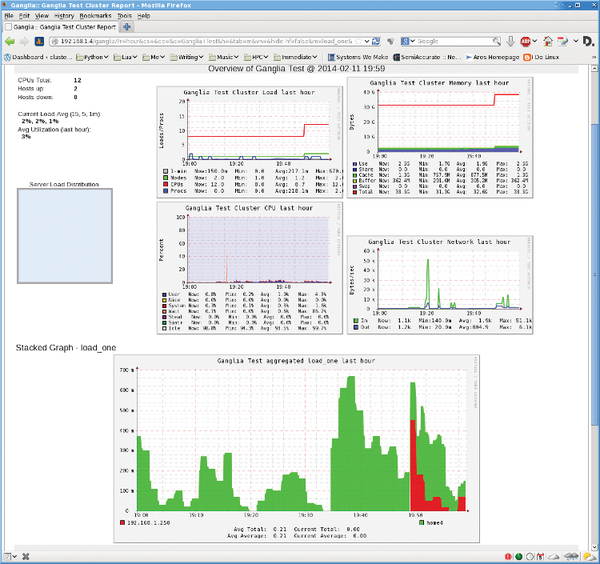 Figure 3: Ganglia showing the host and the client node.
Figure 3: Ganglia showing the host and the client node.
Summary
Ganglia is quickly becoming the go-to system monitoring tool, particularly for large-scale systems. It has been in use for many years, so most of the kinks have been worked out, and it has been tested at very large scales just to make sure. The new web interface makes data visualization much easier than before; it was designed for and written by admins.
For this article, I installed Ganglia on my master node (my desktop), which is running CentOS 6.5. Although I originally tried to build everything myself, it's not easy to get right. (You might get it running, but it might not be correct). Thus, I downloaded the RPMs that one of the developers makes available. Installation was very easy (rpm -ivh ?), as was configuration. Gweb was also easily built and installed, and within seconds, I could visualize what was happening on my desktop. This was nice, but I also wanted to extend my power grab to other systems, so I installed the gmond RPMs on a second system, told the master node about it, and, bingo, the new node was being monitored.
Ganglia has a number of built-in metrics that it monitors, primarily from the /proc filesystem. However, you can extend or add your custom metrics to Ganglia via Python or C/C++ modules.
In a future blog, I'll write about integrating the metrics I wrote in previously into the Ganglia framework. Until then, give Ganglia a whirl. I also highly recommend the well-written book Monitoring with Ganglia [18] from O'Reilly, which explains the inner workings of Ganglia.
Acknowledgments
A quick thank you to Maciej Lasyk [19] and Vladimir Vuksan. Lasyk spent a great deal of time on the Ganglia developers list doing his absolute best to help me build Ganglia from source and get it working. He was very polite and very determined to help me succeed, but in the end, he convinced me that I totally screwed up my installation and I was better off installing the RPMs. I hate to admit defeat, but he was correct. Vuksan's RPMs were my saving grace in installing Ganglia. Thank you, Maciej and Vladimir.
Infos
- "Monitoring HPC Systems: What Should You Monitor?" by Jeff Layton, http://www.admin-magazine.com/HPC/Articles/HPC-Monitoring-What-Should-You-Monitor
- BeoBash: http://www.slideshare.net/insideHPC/beo-bash-2013-podcast
- "Monitoring HPC Systems: Processor and Memory Metrics" by Jeff Layton, http://www.admin-magazine.com/HPC/Articles/Processor-and-Memory-Metrics
- "Monitoring HPC Systems: Process, Network, and Disk Metrics" by Jeff Layton, http://www.admin-magazine.com/HPC/Articles/Process-Network-and-Disk-Metrics
- Monitorix: http://www.monitorix.org
- Munin: http://munin-monitoring.org
- Cacti: http://www.cacti.net
- Ganglia: http://ganglia.sourceforge.net
- Zabbix: http://www.zabbix.com
- Zenoss Community: http://community.zenoss.org/
- Observium: http://www.observium.org/
- GKrellM: http://en.wikipedia.org/wiki/GKrellM
- RRDtool: http://oss.oetiker.ch/rrdtool/
- "Installing Ganglia" by Sachin Sharma, http://sachinsharm.wordpress.com/tag/installing-ganglia/
- Vuksan's World: http://vuksan.com
- CentOS RPMs: http://vuksan.com/centos/RPMS-6/x86_64/
- Ganglia on Sourceforge: http://sourceforge.net/projects/ganglia/files/ganglia-web/
- Massie, Matt, Bernard Li, Brad Nicholes. Monitoring with Ganglia. O'Reilly, 2012
- SecOPS/SysOp blog: http://maciek.lasyk.info/sysop/
« Previous 1 2 3
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Listing 3
Listing 3 for Warewulf – Part 4
-
Warewulf Cluster Manager – Administration and Monitoring

In the last of this four-part series on using Warewulf to build an HPC cluster, I focus a bit more on the administration of a Warewulf cluster, particularly some basic monitoring and the all-important resource manager.
-
Listing 5
Listing 4 for Warewulf Part 4
-
Listing 4
Listing 4 for Warewulf Part 4