« Previous 1 2 3 Next »
The SDFS deduplicating filesystem
Slimming System
Snapshot as Backup
After editing a file, most users like to create a safe copy. To do this, SDFS offers a practical snapshot feature, which you can enable with the sdfscli tool. The following command backs up the current status of the /media/pool0/letter.txt file in /media/pool0/backup/oldletter.txt:
cd /media/pool0
sdfscli --snapshot 66 --file-path=letter.txt \
--snapshot-path=backup/oldletter.txtEven though it looks like SDFS copies the file, this does not actually happen. The oldletter.txt snapshot does not occupy any additional disk space. A snapshot is thus very useful for larger directories in which only a few files change retroactively. The details following --snapshot-path are always relative to the current directory. Seen from the outside, snapshots are separate files and directories, which you can edit or delete in the normal way – just as if you copied the files.
Distributing Data Across Multiple Servers
SDFS can distribute a volume's data across multiple servers. The computers in the SDFS cluster that this creates need a static IP address and as fast a network connection as you can offer. The individual nodes use multicast over UDP for communication. Any existing firewalls need to let the packets through. Beyond this, some virtualizers such as KVM block multicast. A cluster cannot be created in this case, or there are limitations, or you can only use a specific configuration of the virtual machines.
Start by installing the SDFS package on all servers that will be providing storage space for a volume. Then, launch the Dedup Storage Engine (DSE). This service fields the deduplicated data blocks and stores them. Before you can launch a DSE, you must first configure it with the following command:
mkdse --dse-name=sdfs --dse-capacity=100GB \
--cluster-node-id=1The first parameter names the DSE, which is sdfs in this example. The second parameter defines the maximum storage capacity the DSE will provide in the cluster. The default block size is 4KB. Then, --cluster-node-id gives the node a unique ID, which must be between 1 and 200. In the simplest case, just number the nodes consecutively starting at 1. A DSE refuses to launch if it finds a DSE with the same ID already running on the network.
Next, mkdse writes the DSE's configuration to /etc/sdfs/. You need to add the following line below <UDP to the jgroups.cfg.xml file:
bind_addr="192.168.1.101"
Replace the IP address with your server's IP address. As the filename jgroups.cfg.xml suggests, the SDFS components use the JGroups toolkit to communicate [6]. You can then start the DSE service:
startDSEService.sh -c /etc/sdfs/sdfs-dse-cfg.xml &
Follow the same steps on the other nodes, taking care to increment the number following --cluster-node-id.
By default, DSEs store the delivered data blocks on each node's hard disk. However, they can also be configured to send the data to the cloud. At the time of writing, SDFS supported Amazon's AWS and Microsoft Azure. To push the data into one of these two clouds, you only need to add a few parameters to mkdse that mainly provide the access credentials but depend on the type of cloud. Calling mkdse --help will help you find the required parameters, and the Opendedup Quick Start page [7] has more tips.
Once the nodes are ready, you can create and mount the volume on another server. These tasks are handled by the File System Service (FSS). To create a new volume named pool1 with a capacity of 256GB, type the following command:
mkfs.sdfs --volume-name=pool1 --volume-capacity=256GB \
--chunk-store-local falseThis is the same command as for creating a local volume: For operations on a single computer, DSE and FSS share a process. The final parameter, --chunk-store-local false, makes sure that FSS uses the DSEs to create the volume (Figure 3). The block size must also match that of the DSEs, which is the default 4KB in this example. Then, you can type
mount.sdfs pool1 /media/pool1
to mount the volume in the normal way.
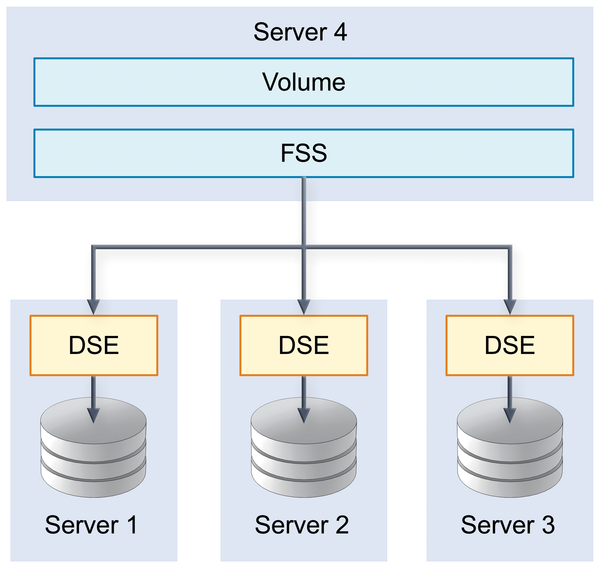 Figure 3: DSEs provide storage space, which the FSS then uses to provide a volume.
Figure 3: DSEs provide storage space, which the FSS then uses to provide a volume.
High Availability and Redundancy
SDFS can store data blocks redundantly in the cluster. To do this, use the --cluster-block-replicas parameter to tell mkfs.sdfs on how many DSE nodes you want to store a data block. In the following example, each data block stored in the volume ends up on three independent nodes:
mkfs.sdfs --volume-name=pool3 --volume-capacity=400GB \
--chunk-store-local false --cluster-block-replicas=3If a DSE fails, the others step in to take its place. However, this replication has a small drawback: SDFS only guarantees high availability of the data blocks, not of the volume metadata – in fact, administrators have to ensure this themselves by creating a backup.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Build a Network Attached Storage System with FreeNAS

We provide an overview of FreeNAS and ZFS, its main filesystem, then show you how to set up and maintain a FreeNAS installation.
-
An introduction to FreeNAS
 We provide an overview of FreeNAS and ZFS, its main filesystem, then show how to set up and maintain a FreeNAS installation.
We provide an overview of FreeNAS and ZFS, its main filesystem, then show how to set up and maintain a FreeNAS installation. -
Storage cluster management with LINSTOR
 LINSTOR is a toolkit for automated cluster management that takes the complexity out of DRBD management and offers a wide range of functions, including provisioning and snapshots.
LINSTOR is a toolkit for automated cluster management that takes the complexity out of DRBD management and offers a wide range of functions, including provisioning and snapshots. -
Build storage pools with GlusterFS
 GlusterFS stores data across the network and can be used as a storage back end in cloud environments.
GlusterFS stores data across the network and can be used as a storage back end in cloud environments. -
GlusterFS Storage Pools

GlusterFS stores data across the network and can be used as a storage back end in cloud environments.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
