
Photo by Christopher Ruel on Unsplash
Secure microservices with centralized zero trust
Inspired
How often have you been caught out by an application that has suddenly and catastrophically failed, only to discover deep in the logs of some unexciting but critical component a message – such as Unable to connect to https://database.service.local – expired TLS certificate – and smacked your head in frustration at how such a preventable failure mode brought down your carefully crafted microservices-based architecture? With an expired TLS certificate, your database could no longer prove its identity or play a part in a zero trust network (Figure 1).
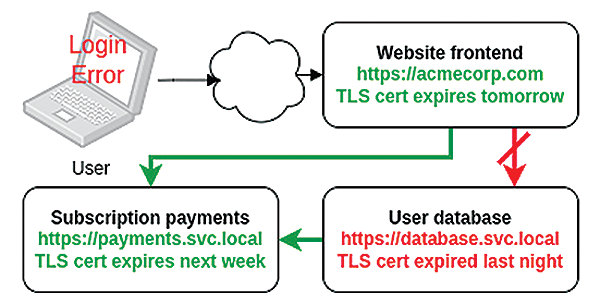 Figure 1: Expiry of a single service's Transport Layer Security (TLS) certificate makes the whole application unusable.
Figure 1: Expiry of a single service's Transport Layer Security (TLS) certificate makes the whole application unusable.
Certificate expiry is just one example of how the human factors involved in identity management can be high maintenance, prone to error, and the source of vulnerabilities. Yet, cast-iron workload identities are, by definition, the foundation of zero trust application architecture. No two workloads should trust each other's legitimacy simply because they both happen to be running on the same physical host or within the same network perimeter. Instead, each TCP session is validated by both participants, and no data is exchanged without each side knowing for sure who is at the other end of the wire.
SPIFFE offers a framework for creating standardized cryptographic identities for heterogenous workloads spanning domains of potentially unlimited size. Because the identity documents use standard public key infrastructure, they also enable strong encryption of inter-workload traffic, thus enabling zero trust by means of mutual TLS. SPIRE is a production-ready open source implementation of SPIFFE that you can implement today. Between them, they can relieve the problems of provisioning and updating identities for all the workloads that make up your application and of trying to maintain complex sets of firewall rules to control who can talk to which host on what port. When zero trust is working right, you don't care half so much about who gets into your network: If they don't have identity, they aren't getting data!
That was a lot of acronyms to begin an article with, so let me clear them up before going any further:
- SPIFFE. Secure Production Identity Framework for Everyone is an open source standard that defines workload identities (SPIFFE IDs), cryptographic identity documents (SVIDs), and the APIs by which those identities are requested and delivered to workloads.
- SPIRE. SPIFFE Runtime Environment is a complete, production-ready suite of software containing an identity server, node agents, APIs, and attestation plugins that, taken together, implement a SPIFFE framework.
- SVID. A SPIFFE Verifiable Identity Document usually takes the form of an X.509 certificate, but alternatively, it can be a JSON web token (JWT). Here, I will talk only about X.509, which lends itself to the mutual TLS (mTLS) example deployed here. Because an X.509 certificate relies on a corresponding private key, it is not vulnerable to a replay attack, unlike the JWT alternative.
In this article I introduce you to SPIFFE's concept of identity and how it is implemented by SPIRE. After covering the core concepts of the SPIRE Server, SPIRE Agent, registration, and attestation, I'll show you how to deploy SPIRE infrastructure on Kubernetes, followed by a simple mTLS client-server application with SVIDs generated by SPIRE. Then, I'll explain the three core methods for creating workloads that are able to use SPIRE. (For more about the origins and implementation of SPIFFE and SPIRE, read Solving the Bottom Turtle [1]).
SPIFFE Core Concepts
SPIFFE describes a trust domain in which the identity of every workload is centrally managed, issued, and validated. The domain could be a single Kubernetes cluster, a lab network, a small company, or a multinational conglomerate; the important points are the top-down control of every identity issued, its structure, its time to live (TTL), and, of course, the workload(s) to which it is issued. For this purpose, SPIFFE defines some key concepts:
SPIFFE ID
This identity string takes the form:
spiffe://<name of domain>/<workload identifier>
The format of the workload identifier itself can be determined by the needs of the implementation and is often broken down into further fields separated by more slash (/) characters, with the contents of each "field" being chosen to represent information that characterizes the workload in a useful way. As a consequence, a SPIFFE-native application can be written to make good use of the data carried in the SPIFFE IDs of its component workloads, over and above the mTLS use case that we are focusing on in this article. Note that although a SPIFFE ID looks very much like a URI, it has no meaning in the DNS sense, and plays no role in establishing the initial layer 3 TCP connection between services.
SVID
As mentioned, I focus on X.509 SVIDs here. An X.509 SVID is a standard TLS certificate that you can retrieve in .pem format and decode with OpenSSL. As such, it can be consumed by just about any type of workload and used for securing its communications. An SVID must contain, in its Subject Alternative Name (SAN) field, only one SPIFFE ID. That ID is the identity of the workload to which the SVID is issued (Figure 2). The workload also receives the SVID's corresponding private key, which it needs to decrypt any information that a remote service has encrypted with the public key in the SVID.
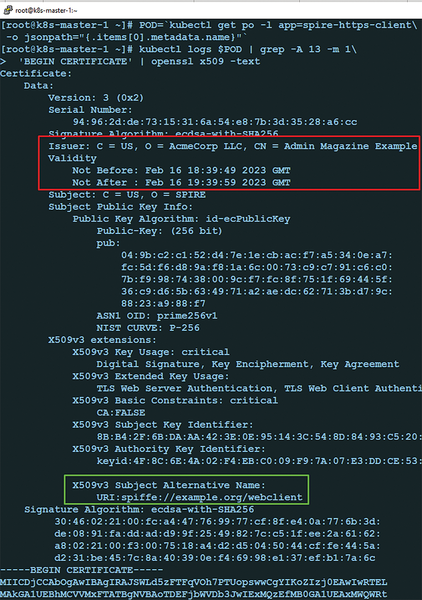 Figure 2: An SVID is just a TLS certificate that contains a SPIFFE ID in its SAN field. The issuer and validity information are in the red box, and the SPIFFE ID is in the green box.
Figure 2: An SVID is just a TLS certificate that contains a SPIFFE ID in its SAN field. The issuer and validity information are in the red box, and the SPIFFE ID is in the green box.
Workload API
This is the means by which workloads request and receive their identities from the SPIFFE framework.
Trust Bundle
As with TLS certificates presented to a web browser, the SVIDs presented by one SPIFFE-enabled workload to another need to be verified. In a production environment, the SPIFFE domain's trust bundle contains the public key material of the organization's root certification authority (CA) and any necessary intermediates sufficient to establish the SVIDs' chain of trust.
Federation
SPIFFE also provides for federation between trust domains. Federation allows a workload in one domain to trust a workload in another domain. In its current form, this requires a SPIFFE domain to expose its trust bundle through an authenticated public endpoint so that it can be retrieved by other permitted domains. Community work to make federation easier to set up and manage is currently under way. Instead of relying on public endpoints exposed by SPIRE servers, a central hub ("Galadriel") and a per-server agent ("Harvester") will orchestrate the exchange of trust bundles between SPIRE domains. The example in this article does not extend to federation, but you can read more about SPIFFE federation in the documentation [2].
Attestation of Identity
SPIFFE's creators explain their approach to identity with an entertaining analogy to Jason Bourne, hero of films such as The Bourne Identity . When Jason Bourne is rescued from the Mediterranean Sea, he is suffering from memory loss and has no idea who he is – just like the containerized workloads I look at later in this article, which have no intrinsic identity. The fishermen who discover him determine that he is skilled in combat and linguistics and has a laser projector embedded in his hip that reveals the number of a safe deposit box, inside which his passport is found, thus establishing his identity.
Likewise, SPIFFE uses the workload's external attributes, such as container image hashes, Unix process IDs (PIDs), and Kubernetes namespace information, to search a database for a registration entry corresponding to this "fingerprint" of attributes. This identification through attributes is called attestation. If a registration is found whose selectors exactly match those attested by the workload, an SVID, key, and trust bundle are delivered to the workload for its use. The process is repeated every time the SVID TTL expires.
SPIRE
SPIRE is an open source implementation of SPIFFE and shares the same open source community and a common Internet home [3]. In addition to the source code, the project [4] provides precompiled implementations for Linux, macOS, Kubernetes, and Docker. SPIRE's two executable components, shown as green boxes in Figure 3, are:
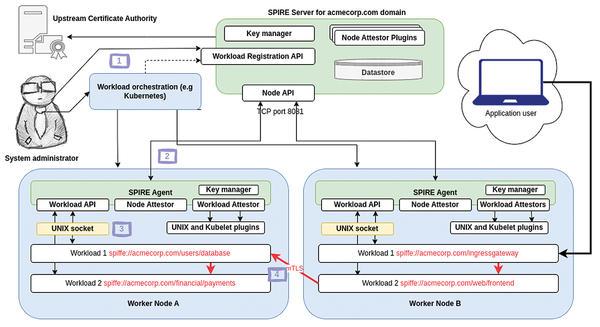 Figure 3: SPIRE infrastructure and workloads.
Figure 3: SPIRE infrastructure and workloads.
- SPIRE Server. This centralized server implements the Registration API and the Node API. The SPIRE Server needs persistent storage to track the workloads registered there and the corresponding identities it has issued. It uses an SQLite database as the default choice; MySQL and PostgreSQL are also supported. As will become clear in the following examples, the entire SPIRE-enabled application becomes completely reliant on the availability of this data store to work, so for production implementations a great deal of consideration needs to be given to this one area. The SPIRE Server also needs a CA for signing SVID requests and a keystore for securing its signing keys. When you install a SPIRE Server, you have the option to specify an upstream CA – typically your corporate root CA or an intermediate – or to accept the default option, with which SPIRE Server will sign SVID requests with a self-signed CA.
- SPIRE Agent. This per-node agent attests the node's identity to the SPIRE Server by means of a TCP connection to the SPIRE Server's Node API and implements the Workload API. A "node" is an individual host – a bare metal or virtual server or a cloud instance such as an Amazon Elastic Compute Cloud (AWS EC2) – capable of running workloads. After the node's own attestation is complete, it receives updated registration information from the SPIRE Server for all the workloads that could be run on that node. When the SPIRE-enabled workloads start up, they request their identity from the SPIRE Agent through the Workload API, which uses a Unix domain socket for communication on the node. The SPIRE Agent performs workload attestation and, if it finds a matching registration, sends the signed SVID for that registration back to the running workload, which then uses the SVID to perform mTLS with other workloads. A workload can be as large as an entire server or as granular as a single process – the many options available for attestation allow you to tailor workload registrations exactly as needed.
To deploy a SPIRE-enabled workload on a running SPIRE infrastructure, the following steps must be completed (see Figure 3):
The system administrator, or some application running on their behalf, registers the workload with the SPIRE Server. The registration contains as many selectors as are needed to identify uniquely the workload(s) that will use this registration. In a Kubernetes environment, the tag or fingerprint of the container image is often used as one of the selectors, as is the Kubernetes service account name. Note that only one registration per SVID is allowed. An example registration command is:
spire-server entry create -spiffeID spiffe://example.org/webclient -parentID spiffe://example.org/ns/spire/sa/spire-agent -selector k8s:container-name:spire-client -selector k8s:container-image:docker.io/acmecorp/go-spiffe-https-example:v0.8 -selector unix:uid:1102 -selector k8s:ns:acmewebappnamespace
Only a workload with characteristics that match these four selectors will be issued the SVID for spiffe://example.org/webclient . The parent ID controls which agent(s) will be able to issue the SVID to the workload and therefore gives additional control over the subset of nodes on which the workload will successfully run.
- The SPIRE Server stores the registration in its database and pushes the registration information to the relevant node(s).
- A SPIRE-enabled workload starts up and requests an SVID through the Workload API. The agent performs workload attestation according to the attestation plugins it is configured to use. In this example, these are the Unix and Kubernetes plugins. If the workload characteristics discovered by the plugins match the values specified for a registration, the agent creates and signs an SVID for the workload (with the stored signing key that it received from the SPIRE Server) and sends the SVID to the workload.
- The workload uses its SVID as its TLS certificate for securing communications to other workloads in the application. If the other workloads have also successfully attested to their local SPIRE Agents, mTLS communication is successful. You can relax in the knowledge that your workloads are able to authenticate one another safely.
The agent tracks the expiration of the SVIDs that it has issued and is able to push updated SVIDs to the workloads as needed. Likewise, the agent's own identity is validated and refreshed by the SPIRE Server itself, according to a preconfigured TTL.
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Sustainable Kubernetes with Project Kepler
 Measure, predict, and optimize the carbon footprint of your containerized workloads.
Measure, predict, and optimize the carbon footprint of your containerized workloads. -
Rancher manages lean Kubernetes workloads
 The Rancher lightweight alternative to Red Hat's OpenShift gives admins a helping hand when entering the world of Kubernetes, but with major differences in architecture.
The Rancher lightweight alternative to Red Hat's OpenShift gives admins a helping hand when entering the world of Kubernetes, but with major differences in architecture. -
Rancher Kubernetes management platform
 Rancher has set up shop as an agile alternative to Red Hat OpenShift as an efficient way to manage Kubernetes clusters. In terms of the architecture, a Rancher setup differs significantly from classic Kubernetes.
Rancher has set up shop as an agile alternative to Red Hat OpenShift as an efficient way to manage Kubernetes clusters. In terms of the architecture, a Rancher setup differs significantly from classic Kubernetes. -
Containers made simple
 The Portainer graphical management interface makes it easy to deploy containers, relieving you of huge amounts of routine work you would normally have to handle with Docker, Podman, or Kubernetes. However, the licensing structure leaves something to be desired.
The Portainer graphical management interface makes it easy to deploy containers, relieving you of huge amounts of routine work you would normally have to handle with Docker, Podman, or Kubernetes. However, the licensing structure leaves something to be desired. -
Zero-Ops Kubernetes with MicroK8s
 A zero-ops installation of Kubernetes with MicroK8s operates on almost no compute capacity and roughly 700MB of RAM.
A zero-ops installation of Kubernetes with MicroK8s operates on almost no compute capacity and roughly 700MB of RAM.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
