« Previous 1 2 3 4 Next »
Monitoring, alerting, and trending with the TICK Stack
Cloud Radar
Where the Data Lives
The best monitoring system is useless if it can't access the data in some way. Because the TICK Stack seeks to be a complete offering, its developers have also put much thought into this subject. The answer is Telegraf [6]: In a MAT system based on InfluxDB, this service collects the metrics on the servers and passes them to InfluxDB for storage.
Telegraf (Figure 3) is similar to Prometheus Node Exporter in the same way that Kapacitor is like its Prometheus counterpart Alert Manager. Telegraf is far more powerful than the Node Exporter, which becomes clear when comparing the scope of delivery: More than 100 plugins for Telegraf extend the program to include a variety of functions. When you roll out Telegraf on the systems from which you want to collect metrics, you use a configuration file to define which plugins will be active and which data will find its way into InfluxDB.
 Figure 3: Telegraf reads basic system values (in a Ceph cluster, e.g., the CPU load, disk I/O, and network throughput).
Figure 3: Telegraf reads basic system values (in a Ceph cluster, e.g., the CPU load, disk I/O, and network throughput).
When selecting the desired plugins, you can choose from almost your heart's desire: PowerDNS or PostgreSQL can be evaluated just as easily as Apache or iptables. Telegraf also provides various other databases out the box, such as Kafka, MongoDB, and CouchDB. Several interesting parameters for classic Linux systems are also provided (e.g., disk fill states, current RAM usage, and system load).
Additionally, various functions let Telegraf monitor services on other systems. Network hardware typically speaks SNMP and outputs data over this interface, but Telegraf cannot be installed on most switches, because it would require Cumulus, which still has a niche status despite all its advantages. However, if you roll out a Telegraf instance that collects metrics from the devices in question over SNMP, the data will find its way into InfluxDB.
Telegraf also plays a central role in generating alarms, which shows once again that the TICK Stack and Prometheus are clearly different in details. Alert Manager connects directly to the Prometheus server and monitors incoming measurement data, whereas in the TICK Stack, Telegraf supplies Kapacitor with data and stores the data in a parallel database. Therefore, if you want to use the TICK Stack, you at least need a minimal Telegraf-InfluxDB-Kapacitor (TIK) setup.
Colorful Chronograf
The "C" in TICK Stack also plays a role: The Chronograf tool [7] conjures up colorful graphs from data in InfluxDB for interpreting the measured data. This TICK Stack component is the only one that might leave you with mixed feelings. InfluxDB, Telegraf, and Kapacitor prove to be unrivaled winners in their respective fields, but Chronograf might lead to ask, "Why?"
Clearly Chronograf has exactly the same target group as Grafana, which is all about data visualization. When Influx started developing Chronograf, Grafana already existed and was already able to evaluate data stored in InfluxDB. Whereas the developers of Prometheus gave up their own PromDash user interface in favor of Grafana (Figure 4), Influx went the opposite way and developed its own user interface.
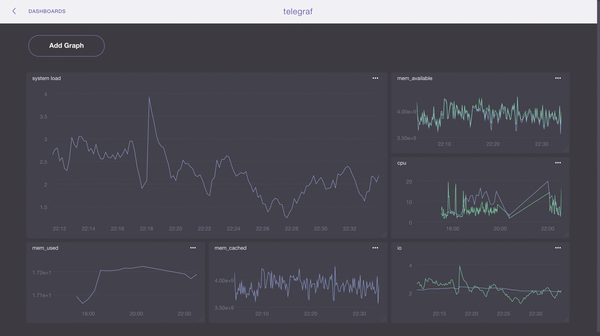 Figure 4: Grafana is a popular tool for visualizing metrics.
Figure 4: Grafana is a popular tool for visualizing metrics.
Their success was limited: Chronograf (Figure 5) is naturally better designed than Grafana for InfluxDB, but it still does not offer all the functions of its competitor and cannot claim to have more useful graphs than Grafana. Many admins do without Chronograf and use the TIK setup. All told, the feeling Chronograf delivers is a very clear case of "Not invented here."
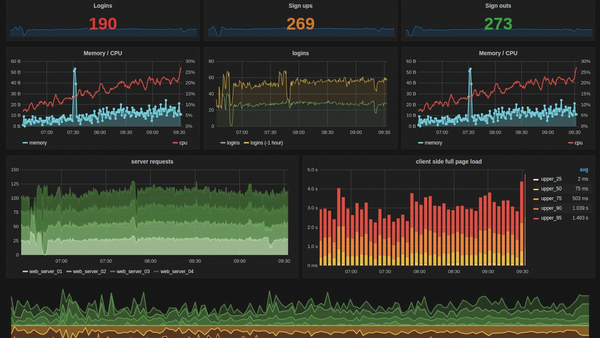 Figure 5: TICK Stack Chronograf is a competitor of Grafana and performs worse in a direct comparison.
Figure 5: TICK Stack Chronograf is a competitor of Grafana and performs worse in a direct comparison.
Peaceful Coexistence?
Many administrators see the choice between Prometheus and the TICK Stack as a black and white decision: Either you commit yourself to Prometheus and rely on the components from its stack or you take InfluxDB and put its helpers on your systems. As usual, there are many shades between black and white, and this is no different when choosing a MAT solution: Instead of an either-or decision, a "why not both" alternative is also conceivable. You can combine the best of both worlds and use the available functions optimally.
Instead of using the not always optimally designed Prometheus Node Exporter, you can use Telegraf to collect metrics on the hosts. This solution offers even more possibilities, because Telegraf comes with various features that are missing in the Prometheus Node Exporter.
Parts of both solutions can be combined even better when it comes to storing data. Whereas Prometheus is not very good at storing data permanently in large quantities to implement long-term trending, InfluxDB is far better at this task and can even store distributed data in a storage cluster on the network, while hardly slowing down – even with large amounts of data.
Prometheus has advantages in short-term trending, and it is also a step ahead when the task is metrics-based monitoring. What could be more obvious than combining the two solutions? The InfluxDB developers even explicitly provide for such a possibility.
InfluxDB developer Paul Dix, who is responsible for the adapter that translates between InfluxDB and Prometheus, describes this kind of setup in a blog post [8]. In a presentation at Percona Live Europe 2017, database manufacturer Percona also discussed the combination of solutions in detail [9]. Finally, the InfluxDB documentation contains a description of this process.
« Previous 1 2 3 4 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
How to query sensors for helpful metrics
 Discover the sensors that already exist on your systems, learn how to query their information, and add them to your metrics dashboard.
Discover the sensors that already exist on your systems, learn how to query their information, and add them to your metrics dashboard. -
Storage monitoring with Grafana
 Create intuitive and meaningful visualizations of storage performance values with a "TIG" stack: Telegraf, InfluxDB, and Grafana.
Create intuitive and meaningful visualizations of storage performance values with a "TIG" stack: Telegraf, InfluxDB, and Grafana. -
Make better use of Prometheus with Grafana, Telegraf, and Alerta
 The Prometheus monitoring tool might not always look like one of the Titans, but add-ons like Alerta or Telegraf can improve its looks.
The Prometheus monitoring tool might not always look like one of the Titans, but add-ons like Alerta or Telegraf can improve its looks. -
Efficiently planning and expanding the capacities of a cloud
 With the right approaches and tools, you can design and manage cloud hardware as efficiently as possible – and discover as early as possible when to upgrade.
With the right approaches and tools, you can design and manage cloud hardware as efficiently as possible – and discover as early as possible when to upgrade. -
Grafana and time series databases
 We look at database back ends for monitoring, alerting, and trending analysis in the Grafana visualization tool.
We look at database back ends for monitoring, alerting, and trending analysis in the Grafana visualization tool.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
