« Previous 1 2 3 Next »
High-performance backup strategies
Keep More Data
Multilayer Backup Strategy
Storage area network (SAN) storage has long been capable of using a combination of data carriers with different attributes in order to use the best properties of each. The combination of SSDs and HDDs, for example, ensures that the fast but more expensive SSDs can be used for the part of the data on which you are currently working (hot data). The other part of the data, which is not really in use but still has to be available (cold data), is then stored on the large and slow, but inexpensive, HDDs.
To achieve a performance boost for your backup through this combination, you define two different storage locations. The first location (referred to as tier 1 in the remainder of this document) comprises flash storage and is capable of holding the backup data for a few days (Figure 1). You can define how long this period is yourself. Because a large part of data restores relate to the most recent backup, a few days are usually enough in this case. The longer you want to store data on tier 1, the more expensive this storage area becomes. Restores are very fast, function like instant recovery (i.e., starting VMs from backup storage), and benefit strongly from the high performance.
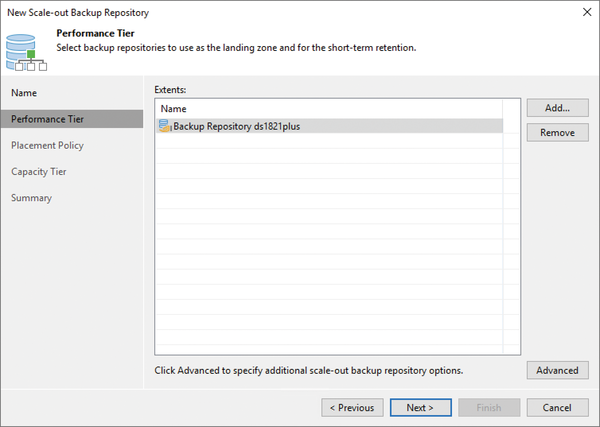 Figure 1: The structure of storage tiers (here, a Synology DS1821+ in the demo lab with Veeam) ensures that backups are distributed over time to storage media of different costs.
Figure 1: The structure of storage tiers (here, a Synology DS1821+ in the demo lab with Veeam) ensures that backups are distributed over time to storage media of different costs.
Some backup products also support manual or automated restoration of backups for testing purposes and to verify data integrity, which not only ensures that the backup is present but also demonstrates that recovery is possible and your backup is usable. This feature of restoring data to a sandbox enhances security and often satisfies various compliance requirements.
Many audits or insurance policies now ask whether restores are performed regularly for validation purposes. Backup storage with sufficient performance enables such tests within a very short time, even when using multiple VMs at the same time. By restoring in a special sandbox, your production is not disturbed at any time (e.g., the tests can even run during the daytime). Another advantage of this shielded environment is that you can run scenarios such as updates, upgrades, and so on with temporarily started VMs.
Once the time period during which the backup data is allowed to reside in tier 1 has expired, the data automatically moves to backend storage (tier 2). For this storage, too, you define how long it stores the data. Through strategic timing (e.g., weekly, monthly, or annually), you can achieve periods of several years. Because you will be using HDDs, you can't expect too much in the way of performance (compared with tier 1 storage), but you will get significantly more storage at a lower cost. Each day the backup data ages decreases the likelihood that you will need to restore the data again. However, if a coworker only notices months later that, say, important files on the file server have been mistakenly overwritten or are completely missing, they will be glad the data is still available somewhere, even if a restore takes longer than a few minutes.
The process of moving data between the different backup tiers should happen automatically so that no manual intervention is necessary. Professional backup software supports you in these steps and offers this feature by default. Be sure to pay attention to the editions available: Depending on the software, these functions are more likely to be included in the more expensive editions and may have to be licensed subsequently or additionally.
Optimal Hardware and Software Combination
The Veeam Backup & Replication product [1] has achieved a considerable market share in just a few years and enjoys a very good reputation. Coupled with a well-thought-out hardware configuration, you can build a backup infrastructure that is highly scalable and benefits from the hardware performance already mentioned (Figure 1).
The smallest and simplest setup combines software and storage directly in a single system. Here, the data carriers are either operated directly in the server, or you can connect one or more external JBOD (just a bunch of disks) enclosures and thus greatly increase the number of data carriers. Depending on the model, between 12 and 72 data carriers will fit and can then be combined into one or more pools in a classic approach with a RAID controller.
Alternatively, you can use S2D, wherein each hard disk, connected by a non-RAID controller (host bus adapter, HBA) and individually visible on the Windows Server operating system, is included in a storage pool; on the basis of this pool, you can then create virtual disks. The advantage of this approach is that you are not tied to the performance of the RAID controller. Furthermore, with a Windows Storage Spaces pool, you can combine several data carrier types to use the flash memory strategically as a cache.
If you size the server adequately in terms of CPU, RAM, and network, it can also act as a VMware backup proxy when using Veeam. On Hyper-V, this would be an alternative to using the resources of the respective Hyper-V host.
If a single system is too risky for you or you need more storage space, one option is to operate a failover cluster that is responsible for storing the backup data. Since Windows Server 2016, this has been available in S2D. Note that you need the Datacenter Edition to run it because the Standard Edition does not offer this feature. With ordinary server systems and locally attached disks, you can build highly available and scalable storage. The setup requires a minimum of two nodes with a maximum of up to 16 servers per cluster, which supports a storage capacity of up to 4PB per cluster that is available exclusively for your backup data, if so desired.
If this setup is not enough, or if you want to set up two storage clusters in different locations or fire zones, you can add the clusters to a scale-out repository in the Veeam software. This technique assembles individual storage locations and devices to create a logical storage target from which you can add or remove any number of backup stores in the background, without changing anything for the backup jobs. This setup gives you a vector for flexible growth without having to check all backup jobs every time you expand or, in the worst case, move multiple terabytes of data.
ReFS is the filesystem used in an S2D cluster. Veeam works with this filesystem, and this shared use offers you some advantages in your daily work. With support for metadata operations, lengthy copy processes on the drive are not required; instead, new pointers are directed at the data blocks and are especially noticeable in backup chains. For example, if you create an incremental backup for 14 days, the change compared with day 14 must be saved on day 15, and the data from day 1 must be moved to the file for day 2. Depending on the size and performance of the storage, this process can sometimes take hours on an NTFS volume. On ReFS, the data on the volume is not moved; references to the location already in use are used. This process is very fast and usually completed within one to two minutes.
Another advantage is that when making weekly, monthly, or yearly backups that create a complete backup file in memory each time, the data is not completely rewritten but references the existing blocks – saving time and storage space.
Money or Data Loss!
Backups also have options to protect your data against ransomware by storing the backup on additional storage (tier 3), which can be on-site, in another building, another city, another country, or outsourced to a cloud provider. Depending on the type and nature of the storage, it might not be possible to modify data after the fact. As a result, malware cannot delete or encrypt the stored backups (Figure 2). Examples of this type of storage include a deduplication appliance or object storage (e.g., Amazon Simple Storage Service (AWS S3) storage), where each object is given an attribute that specifies how long it cannot be modified.
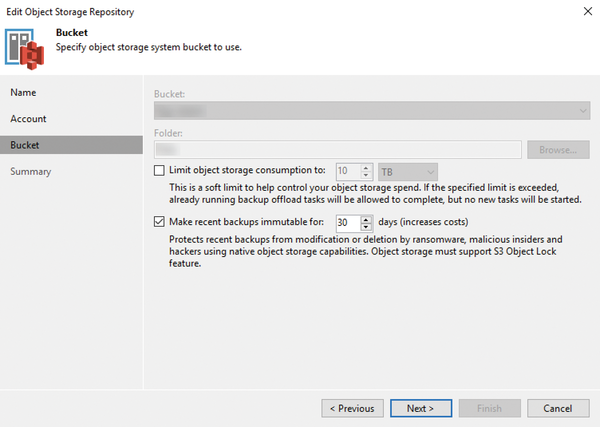 Figure 2: A third storage tier with an immutable attribute can protect against ransomware.
Figure 2: A third storage tier with an immutable attribute can protect against ransomware.
If you use this type of storage, either the data can be written directly from tier 1 to tier 2 and tier 3, or the data from tier 2 can be moved downstream to tier 3. However, you do need to take into account how old the backup data was at the moment of removal and whether it is already too old for disaster recovery.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Backups using rdiff-backup and rsnapshot
 The easier you can back up and restore data, the better. Mature Linux tools show that performing regular, automated backups doesn't have to be a pain.
The easier you can back up and restore data, the better. Mature Linux tools show that performing regular, automated backups doesn't have to be a pain. -
Using rsync for Backups
Although commercial Linux backup tools are available, many people prefer open source to better understand and control the backup process. One open source tool that can do both full and incremental backups is rsync.
-
Back up virtual machines and clusters
 Vembu BDR Suite provides comprehensive software that supports flexible configuration when backing up virtual production operations.
Vembu BDR Suite provides comprehensive software that supports flexible configuration when backing up virtual production operations. -
Flexible backup for large-scale environments
 Bacula is a powerful open source backup solution for large environments that offers automation, extension modules, and commercial support.
Bacula is a powerful open source backup solution for large environments that offers automation, extension modules, and commercial support. -
Cloud protection with Windows Azure Backup
 Microsoft offers the Windows Azure Backup service, which lets you back up data from servers in the cloud. This removes the need for your own infrastructure, and the service alleviates privacy concerns by using continuous encryption.
Microsoft offers the Windows Azure Backup service, which lets you back up data from servers in the cloud. This removes the need for your own infrastructure, and the service alleviates privacy concerns by using continuous encryption.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
