« Previous 1 2 3 Next »
OpenStack observability with Sovereign Cloud Stack
Guard Duty
The Open Source Business Alliance (OSBA) Sovereign Cloud Stack (SCS) project was launched in 2019 to enable federation-capable cloud environments. In close collaboration between the community and OSBA's SCS team, the project uses an agile approach to create the appropriate standards and a reference implementation. SCS [1] is an open, federation-capable modular cloud and container platform based on open source software. It builds on proven open source components such as OpenStack and Kubernetes in the reference implementation (Figure 1). As a platform, SCS provides the foundations for creating offerings that deliver full digital sovereignty.
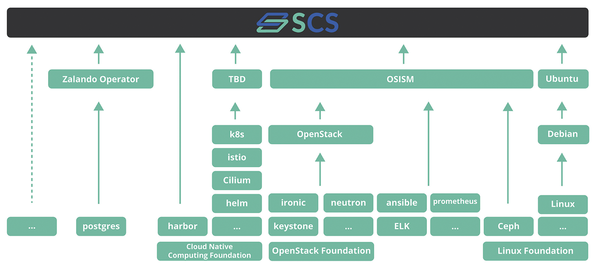 Figure 1: Visualization of the relationships between Sovereign Cloud Stack components.
Figure 1: Visualization of the relationships between Sovereign Cloud Stack components.
SCS Community
The community comprises a wide variety of cloud service providers (CSPs) and their employees, people from the OpenStack community, and companies working on deliverables that are awarded through open tenders. Collaboration between the different providers creates a level of cooperation that rarely exists elsewhere. Various teams and special interest groups (SIGs) work together on the topics, coordinating standards and requirements
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Bare metal deployment with OpenStack
 Automating processes in the age of the cloud is not just a preference, but a necessity, especially as it applies to the installation and initial setup of compute nodes. OpenStack helps with built-in resources.
Automating processes in the age of the cloud is not just a preference, but a necessity, especially as it applies to the installation and initial setup of compute nodes. OpenStack helps with built-in resources. -
Sovereign Cloud Stack – a genuine alternative for Europe
 The Sovereign Cloud Stack promises no less than liberation from the shackles of vendor tie-in. Cloud users who rely on this technology are free to choose their provider and switch, without further investment in training or financial penalty.
The Sovereign Cloud Stack promises no less than liberation from the shackles of vendor tie-in. Cloud users who rely on this technology are free to choose their provider and switch, without further investment in training or financial penalty. -
Combining containers and OpenStack
 The OpenStack cosmos cannot ignore the trend toward containers. If you want to combine both technologies, projects like Magnum, Kolla, and Zun come into play. Which one?
The OpenStack cosmos cannot ignore the trend toward containers. If you want to combine both technologies, projects like Magnum, Kolla, and Zun come into play. Which one? -
The state of OpenStack in 2022
 The unprecedented hype surrounding OpenStack 10 years ago changed to disillusionment, which has nevertheless had a positive effect: OpenStack is still evolving and is now mainly deployed where it actually makes sense to do so.
The unprecedented hype surrounding OpenStack 10 years ago changed to disillusionment, which has nevertheless had a positive effect: OpenStack is still evolving and is now mainly deployed where it actually makes sense to do so. -
Questions about the present and future of OpenStack
 OpenStack has been on the market for 12 years and is generally considered one of the great open source projects. Thierry Carrez and Jeremy Stanley both work on the software and provide information about problems, innovations, and future plans.
OpenStack has been on the market for 12 years and is generally considered one of the great open source projects. Thierry Carrez and Jeremy Stanley both work on the software and provide information about problems, innovations, and future plans.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
