« Previous 1 2 3 Next »
How graph databases work
Relationships
First Steps
The Gremlin Console is one easy way to experiment with a graph database. Gremlin is the query language for Apache TinkerPop, an abstraction layer for multiple graph databases and processors that uses the LPG model.
Gremlin supports declarative pattern matching, which means that what is described is the problem, not the how or the solution. It is also path-based, meaning that queries follow a chain of nodes. Among others, Neo4j, OrientDB, DataStax Enterprise, Hadoop, and Amazon Neptune can use the Gremlin query language – sometimes in parallel with other query languages, which sometimes (e.g., SPARQL) can also be translated into Gremlin code.
Installing the console requires only downloading and unpacking the current version [9] on a Linux computer. If Java 8 is also already installed, the console is immediately ready to launch. A database – the Apache TinkerGraph in-memory model – is also included as a plugin. A selection of sample data is even included in the package.
To start the console from the directory created during unpacking, type bin/gremlin.sh. A very small sample database (Figure 4) can be created with the command from the first line of Listing 2, which loads the Modern
database from the subdirectory data/, so named because it is a more modern version of an older example with six nodes and six edges.
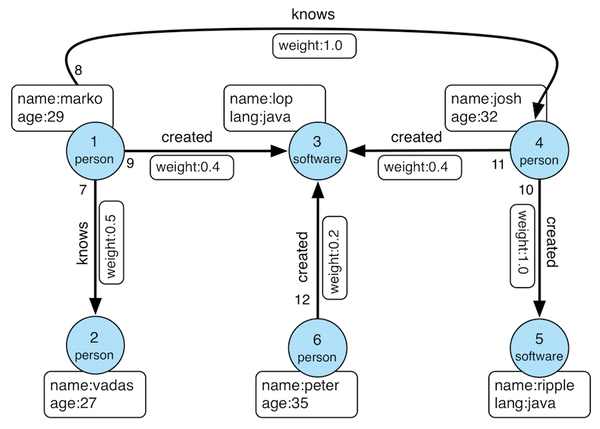 Figure 4: Structure of the Modern database included in the Gremlin Console package.
Figure 4: Structure of the Modern database included in the Gremlin Console package.
Listing 2
Gremlin Database Example
01 graph = TinkerFactory.createModern()
02 ==>tinkergraph[vertices:6 edges:6]
03
04 gremlin> g = graph.traversal()
05 ==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
06
07 gremlin> g.V().label().groupCount()
08 ==>[software:2,person:4]
09
10 # Names of all persons:
11 gremlin> g.V().hasLabel('person').values('name')
12 ==>marko
13 ==>vadas
14 ==>josh
15 ==>peter
16
17 # Name of person with ID 1
18 gremlin> g.V(1).values('name')
19 ==>marko
20
21 # The name and age of the persons who know the person with ID 1:
22 gremlin> g.V(1).outE('knows').inV().valueMap('name', 'age')
23 ==>[name:[vadas],age:[27]]
24 ==>[name:[josh],age:[32]]
25
26 # Which of these people who know the person with ID 1 is less than 30?
27 gremlin> g.V(1).out('knows').has('age', lt(30)).values('name')
28 ==>vadas
29
30 # Display matches step-by-step
31 gremlin> g.V().outE('created').inV().next()
32 ==>v[3]
33
34 gremlin> g.V().outE('created').inV().next(2)
35 ==>v[3]
36 ==>v[5]
The database contains information about a small group of software developers and their products. Some of the developers know each other and have contributed to the same projects. Additionally, Gremlin needs a traversal source, which describes how it should move through the graph. The easiest way to do this is to use the standard path (Listing 2, lines 4 and 5).
To output all the nodes, you use g.V(), and to list all edges, you use g.E(). The queries are generally organized in steps separated by dots. As previously mentioned, g is the traversal source, and V() is an iterator that runs step by step through all nodes. Further steps can now output properties of the respective node (.values()) or check it for certain conditions (.has()).
Additionally, filter results can be aggregated. For example, what happens when the user asks the database how many nodes of different types it has (Listing 2, lines 7 and 8)? Further examples of simple queries are demonstrated in lines 10-28. In principle, each query walks along the tree, which can be observed several ways. You can display hits, step by step (e.g., the first node a created edge points to; lines 31 and 32), the next two (lines 34-36), and so on.
With .toList(), you can return all matches in one fell swoop, and .toSet() returns all matches, but without duplicates. Also, you can retrieve the path that was traversed to get to a search hit. The call in Listing 3 (first query) displays the software projects in which developer Josh was involved.
Listing 3
Simple Queries
gremlin> g.V().hasLabel('person').has('name','josh').outE('created').inV().values('name')
==>ripple
==>lop
gremlin> g.V().hasLabel('person').has('name','josh').outE('created').inV().values('name').path()
==>[v[4],e[10][4-created->5],v[5],ripple]
==>[v[4],e[11][4-created->3],v[3],lop]
gremlin> g.V().outE('created').has('weight', 1.0).inV().values('name')
==>ripple
gremlin> g.V().outE('created').has('weight', 1.0).outV().values('name')
==>josh
The path determination (second query) first finds node 4 with label person and name property josh; from there, it then traces outgoing edges 10 and 11, which are both tagged with the created property (i.e., they must refer to software). By doing so, it finds nodes 3 and 5, which stand for lop and ripple.
In the case of a software product that someone has developed alone, the weighting of the created edge needs to be set to a value of 1.0, as shown in the third query. The final query finds the programmer who created a project on their own by looking for created edges with a weighting of 1.
These queries have all been simple thus far. Traversals also can follow branches in the graph (branching traversals), be processed recursively (recursive traversals), follow paths (path traversals), or refer to subgraphs (subgraph traversals). The step-by-step structure, however, always remains the same, and the number of commands required for the steps does not become unmanageable. In this article, though, I'll stick with simple queries.
If you want to explore the Gremlin language on your own, the Gremlin Console comes with other sample datasets, some of them far more extensive, like the eponymous database of Grateful Dead songs that includes information about the vocalists and composers and the order in which they appeared live and on vinyl. This database has many hundreds of nodes and thousands of edges and is tricky to visualize clearly.
(No) Puzzles
Take the classic river-crossing riddle: A farmer arrives at a river with a wolf, a goat, and a cabbage. He can only carry one animal or the cabbage in his boat at a given time. Furthermore, he cannot leave the wolf and the goat, or the goat and the cabbage, alone on a bank, because the former would eat the latter. How does he get all his belongings across the river unharmed? Spoiler alert! If you want to work it out yourself, read no further.
First, the farmer takes the goat to the other side and goes back empty. Then he picks up the wolf, but takes the goat back with him. Next, he can take the cabbage across and leave it with the wolf, and finally he can take the goat across the river.
This procedure can be represented as a graph with nodes as the respective end states of a crossing (Figure 5). The letters FGCW, for example, stand for farmer, goat, cabbage, and wolf. The comma symbolizes the river. Unauthorized states are colored red. Each step has an action the farmer could take to undo the transport that has just taken place, but this action would not make any progress and is not shown here for the sake of clarity.
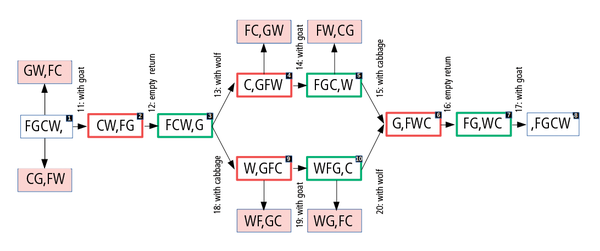 Figure 5: The river-crossing puzzle as a sequence diagram. The boxes show the states at the end of a crossing.
Figure 5: The river-crossing puzzle as a sequence diagram. The boxes show the states at the end of a crossing.
Before saving the graph, you can simplify it further by omitting the reverse actions and the transitions to the illegal states. Whatever remains can be stored directly in the database without the need to design a schema or define tables first, unlike relational models. You could now enter all nodes and all edges interactively one after the other. However, it is easier and less prone to error to create the database content in a file (Listing 4) in XML format (GraphML) and then load this file into the Gremlin console with the commands in Listing 5.
Listing 4
River XML Database
<?xml version="1.0" encoding="UTF-8"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.1/graphml.xsd">
<key id="labelV" for="node" attr.name="labelV" attr.type="string" />
<key id="name" for="node" attr.name="name" attr.type="string" />
<key id="labelE" for="edge" attr.name="labelE" attr.type="string" />
<graph id="G" edgedefault="directed">
<node id="1">
<data key="labelV">state</data>
<data key="name">FGCW,</data>
</node>
<node id="2">
<data key="labelV">state</data>
<data key="name">CW,FG</data>
</node>
<node id="3">
<data key="labelV">state</data>
<data key="name">FCW,G</data>
</node>
<node id="4">
<data key="labelV">state</data>
<data key="name">C,GFW</data>
</node>
<node id="5">
<data key="labelV">state</data>
<data key="name">FGC,W</data>
</node>
<node id="6">
<data key="labelV">state</data>
<data key="name">G,FWC</data>
</node>
<node id="7">
<data key="labelV">state</data>
<data key="name">FG,WC</data>
</node>
<node id="8">
<data key="labelV">state</data>
<data key="name">,FGCW</data>
</node>
<node id="9">
<data key="labelV">state</data>
<data key="name">W,GFC</data>
</node>
<node id="10">
<data key="labelV">state</data>
<data key="name">WFG,C</data>
</node>
<edge id="11" source="1" target="2">
<data key="labelE">action</data>
<data key="name">with_goat</data>
</edge>
<edge id="12" source="2" target="3">
<data key="labelE">action</data>
<data key="name">empty_return</data>
</edge>
<edge id="13" source="3" target="4">
<data key="labelE">action</data>
<data key="name">with_wolf</data>
</edge>
<edge id="14" source="4" target="5">
<data key="labelE">action</data>
<data key="name">with_goat</data>
</edge>
<edge id="15" source="5" target="6">
<data key="labelE">action</data>
<data key="name">with_cabbage</data>
</edge>
<edge id="16" source="6" target="7">
<data key="labelE">action</data>
<data key="name">empty_return</data>
</edge>
<edge id="17" source="7" target="8">
<data key="labelE">action</data>
<data key="name">with_goat</data>
</edge>
<edge id="18" source="3" target="9">
<data key="labelE">action</data>
<data key="name">with_cabbage</data>
</edge>
<edge id="19" source="9" target="10">
<data key="labelE">action</data>
<data key="name">with_goat</data>
</edge>
<edge id="20" source="10" target="6">
<data key="labelE">action</data>
<data key="name">with_wolf</data>
</edge>
</graph>
</graphml>
Listing 5
Loading the Database
gremlin> conf = new BaseConfiguration()
==>org.apache.commons.configuration.BaseConfiguration@1bbae752
gremlin> graph = TinkerGraph.open(conf)
==>tinkergraph[vertices:0 edges:0]
gremlin> g=graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io("/home/jcb/river.xml").with(IO.reader,IO.graphml).read().iterate()
Now you can start a query at the node that contains the start position (FGCW,
). From then on, you need to trace all outgoing edges and incoming nodes until the query finds the node that represents the final state after the river crossing (,FGCW
). At this point, you want the database to output the path taken (.path(); the example has two equivalent paths). Listing 6 discovers the solution to the riddle. The output from the database lists the ID of the node (e.g., [1]), followed by the ID of the outgoing edge (e.g., [e11]) and a description of the edge with start and destination node and transported goods (e.g., 1-with_goat->2). After reaching the node, it continues in the same way until the query has arrived at the destination node.
Listing 6
Solving the Puzzle
gremlin> g.V().has('name','FGCW,').repeat(outE().inV()).until(has('name',',FGCW')).path()
==>[v[1],e[11][1-with_goat->2],v[2],e[12][2-empty_return->3],v[3],e[18][3-with_cabbage->9],v[9],e[19][9-with_goat->10],v[10],e[20][10-with_wolf->6],v[6],e[16][6-empty_return->7],v[7],e[17][7-with_goat->8],v[8]]
==>[v[1],e[11][1-with_goat->2],v[2],e[12][2-empty_return->3],v[3],e[13][3-with_wolf->4],v[4],e[14][4-with_goat->5],v[5],e[15][5-with_cabbage->6],v[6],e[16][6-empty_return->7],v[7],e[17][7-with_goat->8],v[8]]
The result is obvious in this case and could be read off from the graph at first glance, but if you were to store something more complex like the public transport network in Munich as a graph and search for a connection between two points (which might require changing trains one or more times), the task would no longer be trivial – especially if the edges are weighted by distance, travel time, or travel costs, and you are looking for the shortest, fastest, or cheapest route. The method also works even if the graph is too large to be visualized and surveyed.
Hands On
Beyond such finger exercises: For which applications are graph databases best suited in practical use? Are there any useful examples? In this article, I show you some impressive potential applications with genuine case studies.
Say Ms. X is an employee of company Y and lives in Z. She has an unsuspicious current account at a local savings bank. Mr. A lives at exactly the same address and is employed by B as a manager. B has subsidiary C, and it maintains an offshore account in the Cayman Islands. Ms. X's connection to this account is only indirect, but graph databases are particularly useful for tracing such connections around several corners. Indeed, the reporters of the ICIJ used this tool for months of analysis of the 2.6TB of leaked tax data from the Panama Papers – as mentioned at the beginning of the article. The well-known Neo4j open source graph database makes the data available to everyone free of charge for testing in its sandbox (Figure 6), accessible online from a browser [10].
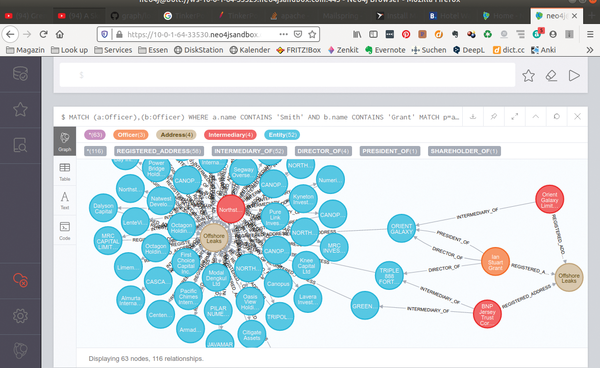 Figure 6: The result of a search in the Panama Papers database.
Figure 6: The result of a search in the Panama Papers database.
Knowledge represented in the form of an ontology (i.e., a formally ordered hierarchy of terms) results in a tree-like graph. A semantic network, which also represents terms and their mutual relationships, is also a graph. Within the individual scientific disciplines, ancestry or kinship relationships in biology or history are a good example. The research project Nomen et Gens (NeG) [11], for example, stores in a graph database more than 21,500 individual records of names and persons in continental Europe between AD400 and 800, together with their relationships.
Another example from science is the cross-location, cross-discipline, and cross-species networking of research data on diabetes at the German Center for Diabetes Research (DZD) in the project Graphs to Fight Diabetes [12]. The database links many heterogeneous data items, including measured values, data from basic research, clinical studies or animal experiments, microscope images, and information on metabolic pathways, genes, or proteins, but also side effects and finally publication references. This combination results in a kind of meta-database that the researchers hope will help them identify new subtypes of the disease and find new, individualized steps for prevention or therapy.
The database currently comprises about 2.1 billion nodes and 3.8 billion edges and weighs in at about 480GB. It is currently used by around 450 scientists at the DZD but is due to be expanded to other centers of health research this year.
What is helpful here is that the relationships between the contents can be visualized (Figure 7). In this way, queries can also be put together by pointing and clicking, without necessarily having to learn one of the supported query languages. In the simplest case, you just need to select two nodes and choose Find Shortest Path from the context menu by right-clicking. Of course, you can also program queries in Cypher or a script language like Python or R.
 Figure 7: Authors, institutions, publications, and how they are connected, as shown by this small excerpt from the graph database of the DZD. © Deutsches Zentrum f¸r Diabetesforschung
Figure 7: Authors, institutions, publications, and how they are connected, as shown by this small excerpt from the graph database of the DZD. © Deutsches Zentrum f¸r Diabetesforschung
Yet another example of the efficacious use of a graph database is the Smart Infrastructure project at Siemens (see the "Intelligent Twins" box).
Intelligent Twins
By Markus Winterholer
At first glance, it seems strange: How can a house be intelligent? What is meant, however, is not so much its walls as the built-in air conditioning, heating, or lighting, which are linked by a network of diverse devices, sensors, service protocols, or contracts, are constantly monitored and analyzed and must be managed in a cost- and resource-saving manner.
In light of occupancy statistics, would it be advantageous to make two small rooms out of a large meeting room? In which rooms of more than 20 square meters in buildings without air conditioning was the average temperature in July 2019 greater than 30C (86F)? We're investigating such questions at Siemens under the heading of Smart Infrastructure. Our goal is to turn more than half a million commercially used buildings into smart buildings with the help of cloud-based digital services and products.
A digital twin serves as a collection point for all plans, contracts, models, service reports, and sensor data. This data is also available for simulations or is used for remote maintenance or energy optimization or flow into apps for room booking and navigation in the building. Combining this flood of data in a single model requires a highly flexible data structure.
Shortly after the start of the project, we realized at Siemens that a conventional relational database would not be fit for the purpose because of the variety of relationships between the data. Various NoSQL databases also reached their limits, because they structure the data poorly. The solution finally came with the introduction of a graph database, which made it possible to reduce the time-to-data by 30 to 50 percent and, in turn, allowed the core modeling team to refocus on refining the model rather than brooding over how to formulate extremely complex queries.
In our case, we chose Amazon Neptune because Amazon Web Services (AWS) gives us access to the widest range of services and lets us scale on demand. Additionally, with AWS, we can be confident that other services that we need will be continually developed. We have also reduced our operating costs.
What lessons have we learned? First, not all data is equally suitable for a graph database. It may make sense to leave time series data in a special database, for example. Second, the graph database alone does not solve the problem if the data model and queries are not adapted. These issues and formulating the queries require skilled personnel. Finally, the highest benefit can often only be achieved by suitable visualization of the query results.
 Markus Winterholer, Global Head of Digital Buildings Go-To-Market Strategy, Siemens
Markus Winterholer, Global Head of Digital Buildings Go-To-Market Strategy, Siemens
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Advantages of data analysis with graph databases
 Analyze scattered but related data in real time with a graph database.
Analyze scattered but related data in real time with a graph database. -
OrientDB document and graph database
 OrientDB is a NoSQL document and graph database with a flexible data model and an elegant approach to querying.
OrientDB is a NoSQL document and graph database with a flexible data model and an elegant approach to querying. -
Graph database Neo4j discovers fake reviews on Amazon
 A Neo4j graph database example shows how to uncover fraudulent reviews on Amazon.
A Neo4j graph database example shows how to uncover fraudulent reviews on Amazon. -
Getting started with Prometheus
 Prometheus is a centralized time series database with metrics, scraping, and alerting logic built in. We help you get started monitoring with Prometheus.
Prometheus is a centralized time series database with metrics, scraping, and alerting logic built in. We help you get started monitoring with Prometheus. -
Workflow-based data analysis with KNIME
 They say data is "the new oil," but all that data you collect is only valuable if it leads to new insights. An open source analysis tool called KNIME lets you analyze data through graphical workflows – without the need for programming or complex spreadsheet manipulation.
They say data is "the new oil," but all that data you collect is only valuable if it leads to new insights. An open source analysis tool called KNIME lets you analyze data through graphical workflows – without the need for programming or complex spreadsheet manipulation.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
